
つくりながら学ぶ!PyTorchによる発展ディープラーニング
- 著作者名:小川雄太郎
-
- 書籍:3,828円
- 電子版:3,828円
- B5変:512ページ
- ISBN:978-4-8399-7025-3
- 発売日:2019年07月29日
- 備考:中級
- Tweet

内容紹介
ディープラーニングの発展・応用手法を実装しながら学ぼう
本書ではディープラーニングの発展・応用手法を実装しながら学習していきます。ディープラーニングの実装パッケージとしてPyTorchを利用します。扱うタスク内容とディープラーニングモデルは次の通りで「ビジネスの現場でディープラーニングを活用するためにも実装経験を積んでおきたいタスク」という観点で選定しました。
[本書で学習できるタスク]
転移学習、ファインチューニング:少量の画像データからディープラーニングモデルを構築
物体検出(SSD):画像のどこに何が映っているのかを検出
セマンティックセグメンテーション(PSPNet):ピクセルレベルで画像内の物体を検出
姿勢推定(OpenPose):人物を検出し人体の各部位を同定しリンク
GAN(DCGAN、Self-Attention GAN):現実に存在するような画像を生成
異常検知(AnoGAN、Efficient GAN):正常画像のみからGANで異常画像を検出
自然言語処理(Transformer、BERT):テキストデータの感情分析を実施
動画分類(3DCNN、ECO):人物動作の動画データをクラス分類
本書は第1章から順番に様々なタスクに対するディープラーニングモデルの実装に取り組むことで高度かつ応用的な手法が徐々に身につく構成となっています。各ディープラーニングモデルは執筆時点でState-of-the-Art(最高性能モデル)の土台となっており、実装できるようになればその後の研究・開発に役立つことでしょう。
ディープラーニングの発展・応用手法を楽しく学んでいただければ幸いです。
実装環境
・読者のPC(GPU環境不要)、AnacondaとJupyter Notebook、AWSを使用したGPUサーバー
・AWSの環境:p2.xlargeインスタンス、Deep Learning AMI(Ubuntu)マシンイメージ(OS Ubuntu 16.04|64ビット、NVIDIA K80 GPU、Python 3.6.5、conda 4.5.2、PyTorch 1.0.1)
充実のラインナップに加え、割引セールも定期的に実施中!
商品を選択する
| フォーマット | 価格 | 備考 | |
|---|---|---|---|
| 書籍 | 3,828円 | ||
| 3,828円 | ※ご購入後、「マイページ」からファイルをダウンロードしてください。 ※ご購入された電子書籍には、購入者情報、および暗号化したコードが埋め込まれております。 ※購入者の個人的な利用目的以外での電子書籍の複製を禁じております。無断で複製・掲載および販売を行った場合、法律により罰せられる可能性もございますので、ご遠慮ください。 |
||

















備考
SIerの技術本部・開発技術部に所属。ディープラーニングをはじめとした機械学習関連技術の研究開発・技術支援を業務とする。明石工業高等専門学校、東京大学工学部を経て、東京大学大学院、神保・小谷研究室にて脳機能計測および計算論的神経科学の研究に従事し、2016年に博士号(科学)を取得。東京大学特任研究員を経て、2017年4月より現職。本書の他に、「つくりながら学ぶ! 深層強化学習 -PyTorchによる実践プログラミング-」(マイナビ出版、2018年6月)なども執筆。
章立て
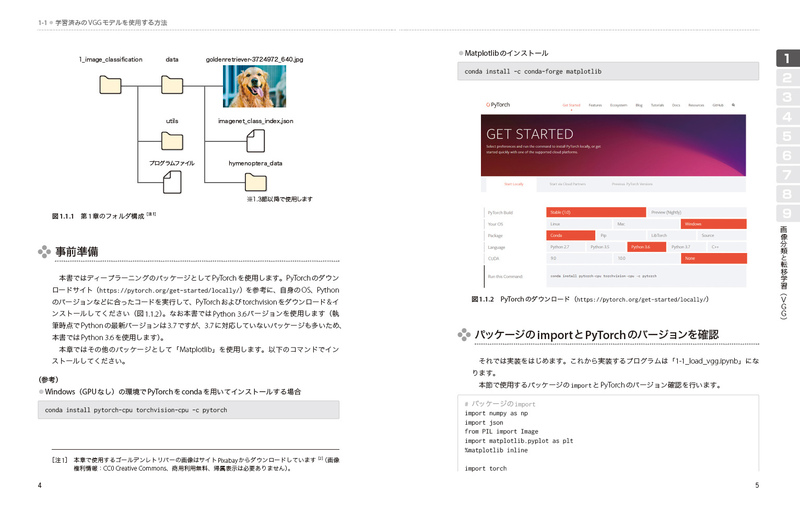
第1章 画像分類と転移学習(VGG)1.1 学習済みのVGGモデルを使用する方法
1.2 PyTorchによるディープラーニング実装の流れ
1.3 転移学習の実装
1.4 Amazon AWSのクラウドGPUマシンを使用する方法
1.5 ファインチューニングの実装
第2章 物体検出(SSD)
2.1 物体検出とは
2.2 Datasetの実装
2.3 DataLoaderの実装
2.4 ネットワークモデルの実装
2.5 順伝搬関数の実装
2.6 損失関数の実装
2.7 学習と検証の実施
2.8 推論の実施
第3章 セマンティックセグメンテーション(PSPNet)
3.1 セマンティックセグメンテーションとは
3.2 DatasetとDataLoaderの実装
3.3 PSPNetのネットワーク構成と実装
3.4 Featureモジュールの解説と実装
3.5 Pyramid Poolingモジュールの解説と実装
3.6 Decoder、AuxLossモジュールの解説と実装
3.7 ファインチューニングによる学習と検証の実施
3.8 セマンティックセグメンテーションの推論
第4章 姿勢推定(OpenPose)
4.1 姿勢推定とOpenPoseの概要
4.2 DatasetとDataLoaderの実装
4.3 OpenPoseのネットワーク構成と実装
4.4 Feature、Stageモジュールの解説と実装
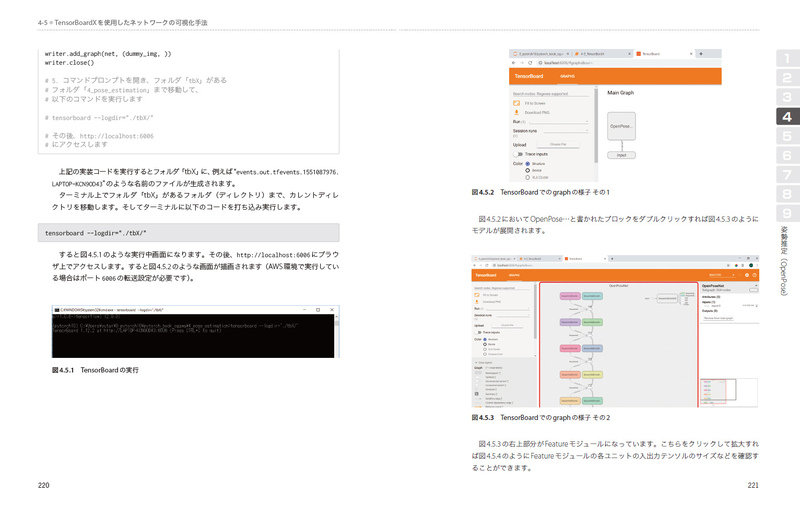
4.5 TensorBoardXを使用したネットワークの可視化手法
4.6 OpenPoseの学習
4.7 OpenPoseの推論
第5章 GANによる画像生成(DCGAN、Self-Attention GAN)
5.1 GANによる画像生成のメカニズムとDCGANの実装
5.2 DCGANの損失関数、学習、生成の実装
5.3 Self-Attention GANの概要
5.4 Self-Attention GANの学習、生成の実装
第6章 GANによる異常検知(AnoGAN、Efficient GAN)
6.1 GANによる異常画像検知のメカニズム
6.2 AnoGANの実装と異常検知の実施
6.3 Efficient GANの概要
6.4 Efficient GANの実装と異常検知の実施
第7章 自然言語処理による感情分析(Transformer)
7.1 形態素解析の実装(Janome、MeCab+NEologd)
7.2 torchtextを用いたDataset、DataLoaderの実装
7.3 単語のベクトル表現の仕組み(word2vec、fastText)
7.4 word2vec、fastTextで日本語学習済みモデルを使用する方法
7.5 IMDb(Internet Movie Database)のDataLoaderを実装
7.6 Transformerの実装(分類タスク用)
7.7 Transformerの学習・推論、判定根拠の可視化を実装
第8章 自然言語処理による感情分析(BERT)
8.1 BERTのメカニズム
8.2 BERTの実装
8.3 BERTを用いたベクトル表現の比較(bank:銀行とbank:土手)
8.4 BERTの学習・推論、判定根拠の可視化を実装
第9章 動画分類(3DCNN、ECO)
9.1 動画データに対するディープラーニングとECOの概要
9.2 2D Netモジュール(Inception-v2)の実装
9.3 3D Netモジュール(3DCNN)の実装
9.4 Kinetics動画データセットをDataLoaderに実装
9.5 ECOモデルの実装と動画分類の推論実施



