
囲碁ディープラーニングプログラミング
- 著作者名:Max Pumperla、 Kevin Ferguson
- 監訳者名:山岡 忠夫
-
- 書籍:3,608円
- 電子版:3,608円
- B5変:448ページ
- ISBN:978-4-8399-6709-3
- 発売日:2019年04月22日
- 備考:初~中級
- Tweet

内容紹介
Pythonによる囲碁AIボット開発からAlphaGo実装までわかりやすく解説!
ボードゲームを題材とした古典的なAIの実装からはじめ、深層学習と強化学習を囲碁AIに組み込み、改良していきます。囲碁ボット構築の方法を理解することで、他の人工知能開発にも応用することができるようになります。
Manning Publications『Deep Learning and the Game of Go』の日本語版。
・PythonとKerasを利用した囲碁AIボット開発でディープラーニングを深く理解できます。
・AlphaGo/AlphaGo Zeroで用いられた手法も解説!
・基本的なPythonと高校レベルの数学の知識で読破可能。
この本はAlphaGoの開発と拡張という魅惑的な冒険へ導いてくれます。あなたは最も美しくかつ挑戦的なゲーム開発の基礎を学ぶことになるでしょう。とても読みやすく魅力に溢れた人工知能と機械学習の実践的入門書です。
― Thore Graepel:DeepMind AlphaGoチームの研究・開発者(本書まえがきより)
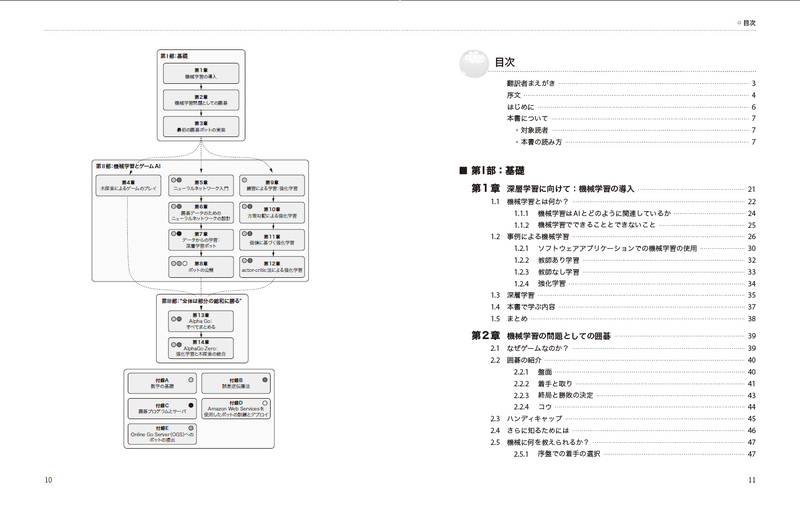
第I部:基礎
第1章 深層学習に向けて:機械学習の導入
第2章 機械学習の問題としての囲碁
第3章 最初の囲碁ボットの実装
第II部:機械学習とゲームAI
第4章 木探索によるゲームプレイ
第5章 ニューラルネットワーク入門
第6章 囲碁データのためのニューラルネットワークの設計
第7章 データからの学習:深層学習ボット
第8章 ボットの公開
第9章 練習による学習:強化学習
第10章 方策勾配による強化学習
第11章 価値に基づく強化学習
第12章 actor-critic法による強化学習
第III部:“全体は部分の総和に勝る”
第13章 AlphaGo:すべてをまとめる
第14章 AlphaGo Zero:強化学習と木探索の統合
付録A 数学の基礎
付録B 誤差逆伝播法
付録C 囲碁プログラムとサーバ
付録D Amazon Web Servicesを使用したボットの訓練とデプロイ
付録E Online Go Serverへのボットの提出
充実のラインナップに加え、割引セールも定期的に実施中!
商品を選択する
| フォーマット | 価格 | 備考 | |
|---|---|---|---|
| 書籍 | 3,608円 | ||
| 3,608円 | ※ご購入後、「マイページ」からファイルをダウンロードしてください。 ※ご購入された電子書籍には、購入者情報、および暗号化したコードが埋め込まれております。 ※購入者の個人的な利用目的以外での電子書籍の複製を禁じております。無断で複製・掲載および販売を行った場合、法律により罰せられる可能性もございますので、ご遠慮ください。 |
||
















備考
Max Pumperila: skymind.aiの深層学習専門のデータサイエンティスト。深層学習プラットフォームaetros.comの共同創設者。
Kevin Ferguson: Honorのデータサイエンティスト。GoogleやMeeboなどの企業での経験もある。
MaxとKevinは共同で、オープンソースの囲碁ボット「BetaGo」をPythonで開発した。
翻訳・山岡忠夫:東京工業大学工学部電子物理工学科卒業。システムエンジニア。『将棋AIで学ぶディープラーニング』著者。AlphaGoでディープラーニングに興味を持ち将棋ソフト「dlshogi」を開発中。
関連ページ
- ソースコードダウンロード(GitHub) https://github.com/maxpumperla/deep_learning_and_the_game_of_go
- 公式サイト(原著サポートサイト) https://www.manning.com/books/deep-learning-and-the-game-of-go
- 書籍サポートサイト https://book.mynavi.jp/supportsite/detail/9784839967093.html
目次
翻訳者まえがき序文
はじめに
本書について
■ 第I部:基礎
第1章 深層学習に向けて:機械学習の導入
1.1 機械学習とは何か?
1.2 事例による機械学習
1.3 深層学習
1.4 本書で学ぶ内容
1.5 まとめ
第2章 機械学習の問題としての囲碁
2.1 なぜゲームなのか?
2.2 囲碁の紹介
2.3 ハンディキャップ
2.4 さらに知るためには
2.5 機械に何を教えられるか?
2.6 囲碁 AIの強さを測定する方法
2.7 まとめ
第3章 最初の囲碁ボットの実装
3.1 Pythonによる囲碁ゲームの表現
3.2 ゲーム状態と非合法な着手のチェック
3.3 終局
3.4 最初のボット:考えられる限り最も弱い囲碁AI
3.5 ゾブリストハッシュによるゲームプレイのスピードアップ
3.6 ボットとの対局
3.7 まとめ
■ 第II部:機械学習とゲームAI
第4章 木探索によるゲームプレイ
4.1 ゲームの分類
4.2 ミニマックス探索による相手の手の予測
4.3 三目並べを解く:ミニマックスの例
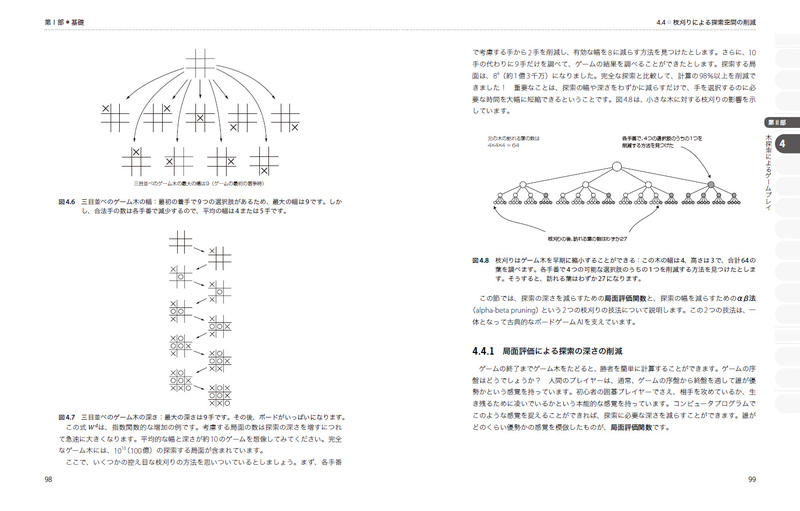
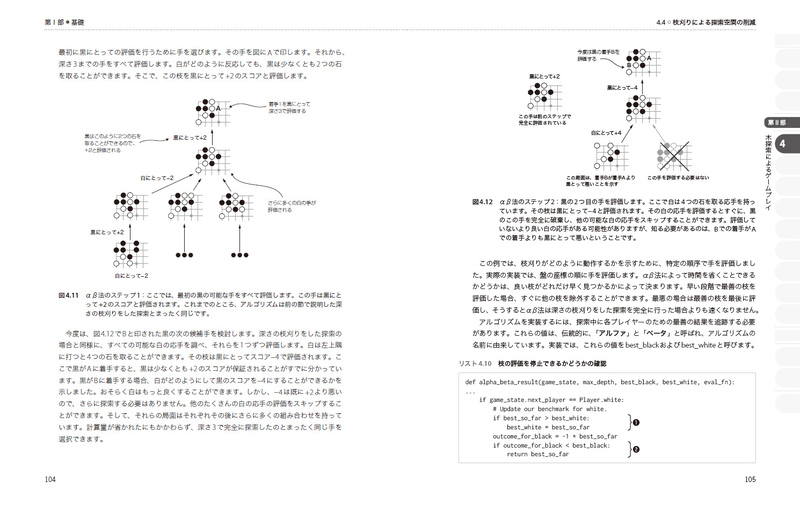
4.4 枝刈りによる探索空間の削減
4.5 モンテカルロ木探索アルゴリズムによるゲーム状態の評価
4.6 まとめ
第5章 ニューラルネットワーク入門
5.1 簡単な事例:手書き数字の分類
5.2 ニューラルネットワークの基礎
5.3 順伝播型ネットワーク
5.4 予測精度はどれくらいか? 損失関数と最適化
5.5 Pythonを使いニューラルネットワークをステップバイステップで訓練する
5.6 まとめ
第6章 囲碁データのためのニューラルネットワークの設計
6.1 ニューラルネットワークのための局面エンコーディング
6.2 木探索によるネットワークの訓練データの生成
6.3 深層学習ライブラリKeras
6.4 畳み込みネットワークによる空間解析
6.5 囲碁の着手確率の予測
6.6 ドロップアウトおよび正規化線形関数を使った、より深いネットワークの構築
6.7 より強力な着手予測ネットワークのためすべてをまとめる
6.8 まとめ
第7章 データからの学習:深層学習ボット
7.1 囲碁の棋譜のインポート
7.2 深層学習のための囲碁データの準備
7.3 人間の対局データによる深層学習モデルの訓練
7.4 より現実的な囲碁データエンコーダの構築
7.5 適応的勾配による効率的な訓練
7.6 独自の実験の実行とパフォーマンスの評価
7.7 まとめ
第8章 ボットの公開
8.1 深層ニューラルネットワークによる着手予測エージェントの作成
8.2 囲碁ボットのウェブフロントエンドへの提供
8.3 囲碁ボットのクラウドへの配置と訓練
8.4 他のボットとの対話:Go Text Protocol (GTP)
8.5 ローカルで他のボットと対局
8.6 オンライン囲碁サーバへの囲碁ボットの配置
8.7 まとめ
第9章 練習による学習:強化学習
9.1 強化学習サイクル
9.2 何が経験になるか
9.3 学習可能なエージェントの構築
9.4 自己対局:コンピュータプログラムの練習方法
9.5 まとめ
第10章 方策勾配による強化学習
10.1 ランダムなゲームでどのようにして良い決定を行うことができるか
10.2 勾配降下法によるニューラルネットワーク方策の更新
10.3 自己対局による訓練のためのヒント
10.4 まとめ
第11章 価値に基づく強化学習
11.1 Q学習を使用したゲームプレイ
11.2 KerasによるQ学習
11.3 まとめ
第12章 actor-critic法による強化学習
12.1 アドバンテージはどの決定が重要かを教える
12.2 actor-criticによる学習のためのニューラルネットワークの設計
12.3 actor-criticによるゲームプレイ
12.4 経験データからactor-criticエージェントを訓練する
12.5 まとめ
■ 第III部:“全体は部分の総和に勝る”
第13章 AlphaGo:すべてをまとめる
13.1 AlphaGoのための深層ニューラルネットワークの訓練
13.2 方策ネットワークからの自己対局のブートストラップ
13.3 自己対局データから価値ネットワークを導く
13.4 方策と価値ネットワークによるより良い探索
13.5 自作AlphaGoを訓練するための実践的考察
13.6 まとめ
第14章 AlphaGo Zero:強化学習と木探索の統合
14.1 木探索のためのニューラルネットワークの構築
14.2 ニューラルネットワークによる木探索のガイド
14.3 訓練
14.4 ディリクレノイズによる探索の改善
14.5 より深いニューラルネットワークのための最新のテクニック
14.6 追加の資料の探索
14.7 総仕上げ
14.8 まとめ
■ 付録
付録A 数学の基礎
付録B 誤差逆伝播法
付録C 囲碁プログラムとサーバ
付録D Amazon Web Servicesを使用したボットの訓練とデプロイ
付録E Online Go Serverへのボットの提出
索引
謝辞
著者紹介
