『東京大学のデータサイエンティスト育成講座』サポートサイト

このページは、
『東京大学のデータサイエンティスト育成講座(ISBN978-4-8399-6525-9)』
のサポートページです。
紙版: 2019/3/11 初版第1刷発行
サンプルファイルのダウンロード
本書のサンプルファイルです。下記からダウンロードしてください。
サンプルファイルはJupyter Notebook形式です。本書巻末に案内のあるAnacondaなどをインストールしてご覧ください。
特典ファイルのダウンロード
特典ファイルの内容は以下の通りです。
(1) PG_Python_Special.pdf…「データサイエンティスト中級者への道」(36ページ分)
(2) PG_Python_Special_Setup.pdf… (1) ファイルのための環境構築説明
(3) Tokuten_Answer.ipynb … (1) の練習問題解答
訂正情報
以下の誤りがありました。お詫びの上訂正します。
● P.029の1つ目の「出力」最後の行 ※11刷で修正
誤: data:20 & 10
正: data:20:yの値10
● P.033の「2-1-1-2 fromを使ったインポート」の最終行 ※7刷で修正
誤: 「ny.random.機能名」と記述する必要があるところを…
正: 「np.random.機能名」と記述する必要があるところを…
● P.042の「2-2-4 行列」 の「入力」 ※5刷で修正
誤: 行列から、行や列のみを抜き出したいときは、「[行範囲:列範囲]」のように表記します。それぞれの範囲は、「開始インデックス,終了インデックス」のように、…
正: 行列から、行や列のみを抜き出したいときは、「[行範囲,列範囲]」のように表記します。それぞれの範囲は、「開始インデックス:終了インデックス」のように、…
● P.072のページ上部の「入力」の2行目 ※5刷で修正
誤: url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00356/student.zip'
正: url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/00356/student.zip'
● P.072のページ半ばの「出力」 ※7刷で修正
誤: "chap3/ student-merge.R student.txt student-mat.csv student-por.csv wine_data.csv"
正: "chap3/ student-merge.R student.txt student-mat.csv student-por.csv (※wine_data.csvが不要でした)
● P.080の1つ目の最後の行 ※11刷で修正
誤: 標準偏差はstd()で計算できます。
正: 標準偏差はstd()で計算できます。std()のオプションは、デフォルトではddof=1となりn-1で割る方式で算出されますが、今回はnで割る方式で算出するためにddof=0を指定しています。
● P.080の「3-3-3 分散と標準偏差」の「入力」と「出力」 ※8刷で修正
誤:
入力: # 分散 student_data_math['absences'].var()
出力:64.050
正:
入力: # 分散 student_data_math['absences'].var(ddof=0)
出力:63.887
● P.081のページ最初の「入力」と「出力」 ※8刷で修正
誤:
入力: # 標準偏差 σ student_data_math['absences'].std()
出力:8.008
正:
入力: # 標準偏差 σ student_data_math['absences'].std(ddof=0)
出力:7.993
● P.081の2つ目の「入力」と「出力」 ※11刷で修正
誤:
「入力」:np.sqrt(student_data_math['absences'].var())
「出力」:8.003095687108177
正:
「入力」:np.sqrt(student_data_math['absences'].var(ddof=0))
「出力」:7.992958766400057
● P.081の「3-3-4 要約統計量とパーセンタイル値」の4行目 ※11刷で修正
誤: …最大値を計算できます。
正: …最大値を計算できます。describeにはddofのオプションが指定できませんので、結果の標準偏差(std)はn-1で割る方式(不偏分散の平方根)で算出されます。先に算出したstd()と結果が異なりますので注意しましょう。
● P.084の「3-3-6 変動係数」の「入力」と「出力」 ※11刷で修正
誤:
「入力」:student_data_math['absences'].std() / student_data_math['absences'].mean()
「出力」:1.402
正:
「入力」:student_data_math['absences'].std(ddof=0) / student_data_math['absences'].mean()
「出力」:1.400
● P.085の1つ目の「入力」と「出力」 ※11刷で修正
誤:
「入力」:student_data_math.std() / student_data_math.mean()
「出力」:
age 0.076427
Medu 0.398177
Fedu 0.431565
traveltime 0.481668
studytime 0.412313
failures 2.225319
famrel 0.227330
freetime 0.308725
goout 0.358098
Dalc 0.601441
Walc 0.562121
health 0.391147
absences 1.401873
G1 0.304266
G2 0.351086
G3 0.439881
dtype: float64
正:
「入力」:student_data_math.std(ddof=0) / student_data_math.mean()
「出力」:
age 0.076330
Medu 0.397673
Fedu 0.431019
traveltime 0.481058
studytime 0.411791
failures 2.222501
famrel 0.227042
freetime 0.308334
goout 0.357645
Dalc 0.600679
Walc 0.561409
health 0.390651
absences 1.400097
G1 0.303881
G2 0.350641
G3 0.439324
dtype: float64
● P.086の1つ目の「入力」と「出力」 ※11刷で修正
誤:
「入力」:np.cov(student_data_math['G1'], student_data_math['G3'])
「出力」:array([[11.017, 12.188],
[12.188, 20.99]])
正:
「入力」:np.cov(student_data_math['G1'], student_data_math['G3'],ddof=0)
「出力」:array([[10.989, 12.157],
[12.157, 20.936]])
● P.086の2つ目の「入力」と「出力」 ※11刷で修正
誤: 「入力」:
print('G1の分散:',student_data_math['G1'].var())
print('G3の分散:',student_data_math['G3'].var())
「出力」:
G1の分散: 11.017053267364899
G3の分散: 20.989616397866737
正:
「入力」:
print('G1の分散:',student_data_math['G1'].var(ddof=0))
print('G3の分散:',student_data_math['G3'].var(ddof=0))
「出力」:
G1の分散: 10.989161993270304
G3の分散: 20.93647812850505
● P.086の2つ目の「入力」と「出力」の下の文章 ※15刷で修正
誤:
● G1とG3の共分散:共分散行列の(1,2)と(2,1)の要素です。上の例では、12.188という値です。
● G1の分散:共分散行列の(1,1)の要素です。上の例では11.017です
● G3の分散:共分散行列の(2,2)の要素です。上の例では20.99です。
正:
● G1とG3の共分散:共分散行列の(1,2)と(2,1)の要素です。上の例では、12.157という値です。
● G1の分散:共分散行列の(1,1)の要素です。上の例では10.989です
● G3の分散:共分散行列の(2,2)の要素です。上の例では20.936です。
● P.101の最終行 ※6刷で修正
誤: P(A|B)は、Aが観測されたときにBが原因であるだろう確率(これを尤度と…
正: P(A|B)は、B が起きた場合にA が起こるであろう確率(これを尤度と…
● P.140の「式5-3-1」 ※11刷で修正
| 誤: | 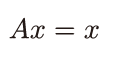 |
| 正: | 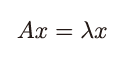 |
● P.176の1つ目の「入力」の10~11行 ※13刷で修正
誤:
df2.iloc[5:8,2] = NA
df2.iloc[7:9,3] = NA
正:
df2.iloc[5:9,2] = NA
df2.iloc[7:10,3] = NA
● P.208の【練習問題8-1】の1~2行目 ※6刷で修正
誤: このデータに対して、目的変数をpriceとし、説明変数にlengthとengine-sizeを使って重回帰のモデル構築をしてみましょう。
正: このデータに対して、目的変数をpriceとし、説明変数にwidthとengine-sizeを使って重回帰のモデル構築をしてみましょう。
● P.212の本文4~5行目 ※5刷で修正
誤: オッズ比とは、それぞれの係数が1単位増加したとき、正解率にどの程度影響があるかを示す指標です。
正: オッズ比とは、それぞれの係数が1単位増加したとき、予測確率にどの程度影響があるかを示す指標です(影響なし時は1.0となります)。
● P.212の2つ目の「入力」 と「出力」 ※5刷で修正
誤: 入力:model.coef_
出力:array([[-4.510e-03, -5.717e-06, -1.082e-03, 3.159e-04, 7.230e-04]])
正: 入力:np.exp(model.coef_)
出力:array([[0.996, 1. , 0.999, 1. , 1.001]])
● P.283の「入力」の最後の行 ※14刷で修正
誤: plt.legend(loc=\"best\")
正: plt.legend(loc="best")
● P.285の「入力」(ボストン住宅価格データセットの配布が終了したことで差し替え) ※22刷で修正
正:
# カリフォルニアの住宅価格データセットをインポート
from sklearn.datasets import fetch_california_housing
# カリフォルニアの住宅価格データを取得
california_housing_data = fetch_california_housing()
# 津築年数等の説明変数をDataFrameに格納
X = pd.DataFrame(california_housing_data.data, columns=california_housing_data.feature_names)
# 住宅価格を目的変数としてSeriesに格納
y = pd.Series(california_housing_data.target, name='HousingPrices')
# 説明変数と目的変数を結合し、先頭の5 行を表示
X.join(y).head()
● P.291の「入力」6、7~8行目(ボストン住宅価格データセットの配布が終了したことで差し替え) ※22刷で修正
誤:boston = load_boston()
X_train, X_test, y_train, y_test = train_test_split(
boston.data, boston.target, random_state=66)
正:
california_housing_data = fetch_california_housing()
X_train, X_test, y_train, y_test = train_test_split(
california_housing_data.data, california_housing_data.target, random_state=66)
● P.292の「入力」5、8~9行目(ボストン住宅価格データセットの配布が終了したことで差し替え) ※22刷で修正
誤:boston = load_boston()
X_train, X_test, y_train, y_test = train_test_split(
boston.data, boston.target, random_state=66)
正:
california_housing_data = fetch_california_housing()
X_train, X_test, y_train, y_test = train_test_split(
california_housing_data.data, california_housing_data.target, random_state=66)
● P.293の「入力」2~3行目(ボストン住宅価格データセットの配布が終了したことで差し替え) ※22刷で修正
誤:s = pd.Series(models['RandomForest'].feature_importances_,
index=boston.feature_names)
正:
s = pd.Series(models['RandomForest'].feature_importances_,
index=california_housing_data.feature_names)
● P.300の「11-1-6 総合練習問題(6)」 ※10刷で修正
書籍記載のURLからデータがダウンロードできなくなったため、以下よりダウンロードしてください。 https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/HG7NV7
ここで、「1987.csv.bz」「1988.csv.bz」「1999.csv.bz」をダウンロードしてください。 プログラムは使わず、手動でダウンロードしてください。またファイルが大きいので、時間がかかります。ダウンロード後、Lhaplusなどのツールで解凍し、csvファイルをすべて1つの作業用ディレクトリに集めてから進めてください。
● P.301のプログラム1行目 ※5刷で修正
誤: for year in range(1987,2000):
正: for year in range(1987,1990):
● P.312の【総合問題1-1 素数判定】1 の本文6~7行目 ※2刷で修正
誤: calc_prime_num(10)
正: なし(※最後の1行は不要でした)
● P.328の「式A2-3-1」の一番右の分子 ※10刷で修正
| 誤: | 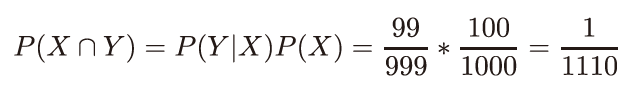 |
| 正: | 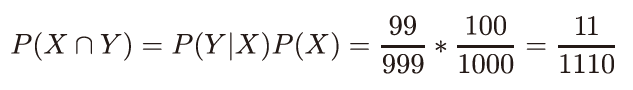 |
● P.328の「練習問題4-3」の「入力」 ※10刷で修正
誤: 0.99*0.001/(0.99*0.001+0.03*0.99)
正: 0.99*0.001/(0.99*0.001+0.03*0.999)
● P.341の最後の「練習問題6-1」の「入力」 ※13刷で修正
誤: hier_data_frame1['Kyoto']
正: hier_df1['Kyoto']
● P.342の「練習問題6-2」の「入力」 ※13刷で修正
誤: hier_data_frame1.mean(level='city', axis=1)
正: hier_df1.mean(level='city', axis=1)
● P.342の「練習問題6-3」の「入力」 ※13刷で修正
誤: hier_data_frame1.sum(level='key2')
正: hier_df1.sum(level='key2')
● P.342の「練習問題6-4」の「入力」 ※13刷で修正
誤: pd.merge(df4, df5, on='id')
正: pd.merge(df4, df5, on='ID')
● P.344の【練習問題6-8】 の「出力」 ※9刷で修正
誤: (5, 100] 146
(1, 5] 131
(0, 1] 3
Name: absences, dtype: int64
正: [5, 100) 151
[1, 5) 129
[0, 1) 115
Name: absences, dtype: int64
● P.368の「練習問題8-7」の「入力」15~16行目 ※11刷で修正
誤: plt.plot(neighbors_settings, training_accuracy,label='Training')
plt.plot(neighbors_settings, test_accuracy,label='Test')
正: plt.plot(neighbors_settings, scores_train,label='Training')
plt.plot(neighbors_settings, scores_test,label='Test')
● P.368の「練習問題8-7」の「出力」 ※11刷で修正
| 誤: | 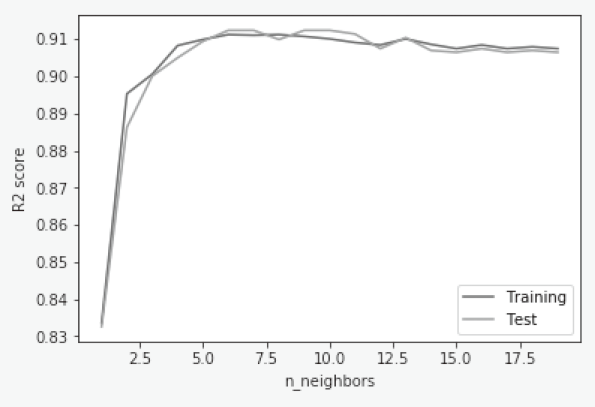 |
| 正: |  |
