
ビッグデータ分析・活用のためのSQLレシピ
- 著作者名:加嵜長門、 田宮直人
- 編集者名:丸山弘詩
-
- 書籍:4,180円
- 電子版:4,180円
- B5変型判:496ページ
- ISBN:978-4-8399-6126-8
- 発売日:2017年03月27日
- 備考:Win/Mac、中~上級
- Tweet

内容紹介
ビッグデータ時代のSQL活用術・レシピ集
本書は、著者が普段の業務で実際に作成しているレポートやSQLのコードをより汎用化し、レシピ集としてまとめたものです。「データの加工」「売上の把握」「ユーザーの把握」「Webサイト内のユーザー行動の把握」「異常値の検出」「検索機能の評価」「レコメンド」など、具体的なシーン別に、実践的な手法とノウハウを解説しています。
●読者対象
本書では、アクセス解析等を担当する社内の分析担当者と、実装を行うエンジニアの双方を対象として、下記の情報を提示します。
・データ加工の手法
・分析に使用するSQL
・レポーティング・分析の手法
分析担当者であれば、アクセス解析ツールが提供する指標やフィルタがなくても、それ以上のことを自らで実践できるようになること、エンジニアであれば、分析業務を十分に理解して、分析担当者や経営層に対して、適切な情報提供やレポート提出、そして助言できるようになることを、目指しています。
●構成
1 ビッグデータ時代に求められる分析力とは
2 本書で扱うツールとデータ群
3 データ加工のためのSQL
4 売上を把握するためのデータ抽出
5 ユーザーを把握するためのデータ抽出
6 Webサイトでの行動を把握するためのデータ抽出
7 データ活用の精度を高めるための分析術
8 データを武器にするための分析術
9 知識に留めず行動を起こす
Chapter1~2は導入部で、Chapter1は基本を解説し、Chapter2で本書で扱うデータやミドルウェアについて説明しています。
Chapter3~8では、具体的なSQLを用いたコード例とともに、ビッグデータ活用の手法について紹介します。
Chapter3では基礎的なSQLの記述やデータ加工の手法について解説し、続くChapter4~8でデータ活用における具体的なシーン別に実践的な「分析手法」と「SQL」を解説しています。
Chapter9ではまとめとして、本書の提供する内容が知識で留まらないよう、データの活用の事例やヒントを紹介します。
●本書で扱うミドルウェア
PostgreSQL、Apache Hive、Amazon Redshift、Google BigQuery、SparkSQLで動作確認を行っています。
充実のラインナップに加え、割引セールも定期的に実施中!
商品を選択する
| フォーマット | 価格 | 備考 | |
|---|---|---|---|
| 書籍 | 4,180円 | ||
| 4,180円 | ※ご購入後、「マイページ」からファイルをダウンロードしてください。 ※ご購入された電子書籍には、購入者情報、および暗号化したコードが埋め込まれております。 ※購入者の個人的な利用目的以外での電子書籍の複製を禁じております。無断で複製・掲載および販売を行った場合、法律により罰せられる可能性もございますので、ご遠慮ください。 |
||














備考
加嵜 長門(カサキ ナガト)
株式会社DMM.comラボ所属。慶應義塾大学大学院 政策・メディア研究科修士課程修了。大学院や学生ベンチャーにて、マルチメディアデータベースを対象とした検索やレコメンドアルゴリズムの研究およびサービス開発に従事し、現在DMM.comラボではビッグデータ活用基盤の構築に携わり、SparkやSQL on Hadoopを用いたレコメンド機能、ビッグデータ活用の研究開発を担当。 共著に『詳解Apache Spark』(技術評論社)。
田宮 直人(タミヤ ナオト)
データコンサルタント。エンジニアとして大手新聞社の関連サービス、求人サービス、コミュニティサービスの開発に携わり、株式会社サイバーエージェント在籍時にデータアナリストへ転身、株式会社DMM.comラボではマーケティング開発部マネージャーとしてビッグデータ部を立ち上げる。現在はフリーランスとして、データの解析のみならず、データ解析環境の設計・構築、ログの設計、レコメンドAPIの作成など、データに関連する業務全般を担当している。
編集者プロフィール:
丸山 弘詩(マルヤマ ヒロシ)
書籍編集者。早稲田大学政治経済学部経済学科中退。国立大学大学院博士後期課程(システム生産科学専攻)編入、単位取得の上で満期退学。大手広告代理店勤務を経て、現在は書籍編集に加え、さまざまな分野のコンサルティング、プロダクトディレクション、開発マネージメントなどを手掛ける。著書は『スマートフォンアプリマーケティング 現場の教科書』(マイナビ出版刊)など多数。
目次
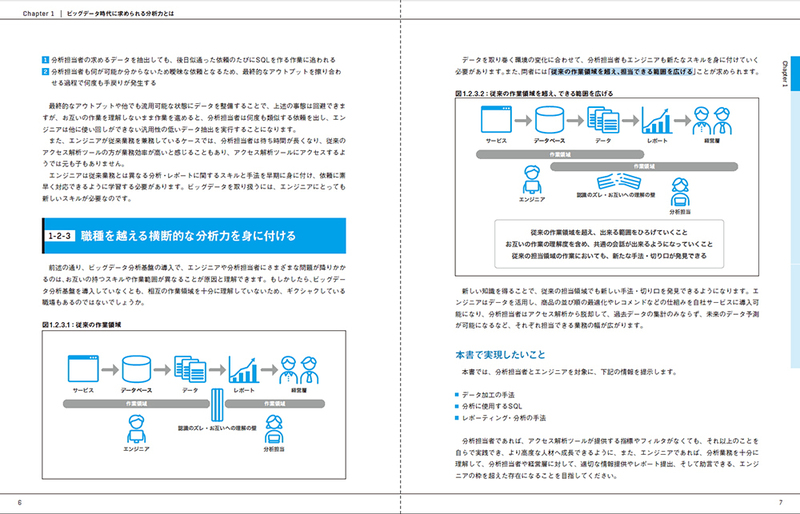
Chapter1 ビッグデータ時代に求められる分析力とは1 データを取り巻く環境の変化
2 さまざまな課題
分析担当者の課題
エンジニアの課題
職種を越えた横断的な分析力を身につける
Chapter2 本書で扱うツールとデータ群
1 システム
PostgreSQL
Apache Hive
Amazon Redshift
Google BigQuery
SparkSQL
2 データ
データの種類
業務データ
ログデータ
2つのデータを利用することで生まれる価値
Chapter3 データ加工のためのSQL
1 一つの値に対する操作
コード値をラベルに置き換える
URLから要素を取り出す
文字列を配列に分解する
日付やタイムスタンプを扱う
欠損値をデフォルト値に置き換える
2 複数の値に対する操作
文字列を連結する
複数の値を比較する
2つの値の比率を計算する
2つの値の距離を計算する
日付/時刻の計算をする
IPアドレスを扱う
3 1つのテーブルに対する操作
グループの特徴を捉える
グループの中での順序を扱う
縦持ちのデータを横持ちに変換する
横持ちのデータを縦持ちに変換する
4 複数のテーブルに対する操作
複数のテーブルを縦に並べる
複数のテーブルを横に並べる
条件のフラグを0と1で表現する
計算したテーブルに名前を付けて再利用する
擬似的なテーブルを作成する
Chapter4 売上を把握するためのデータ抽出
1 時系列に沿ってデータを集約する
日別の売上を集計する
移動平均を用いて日別の推移を見る
日別の売上を集計して、当月売上の累計を求める
月別の売上を集計し、昨対比を求める
Zチャートで業績の推移を見る
売上を把握するための大事なポイント
2 多面的な軸を使ってデータを集約する
カテゴリ別の売上と小計を計算する
ABC分析で売れ筋とそうでないものを分ける
ファンチャートで商品の売れ行きの伸び率を見る
購入価格帯を集計する
Chapter5 ユーザーを把握するためのデータ抽出
1 ユーザー全体の特徴・傾向を見つける
ユーザーのアクション数を集計する
年齢別区分を集計する
年齢別区分ごとの特徴を抽出する
ユーザーの訪問頻度を集計する
ベン図でユーザーのアクションを集計する
デシル分析でユーザーを10段階のグループに分ける
RFM分析でユーザーを3つの視点でグループ分けをする
2 時系列に沿ったユーザー全体の状態変化を見つける
登録数の推移、傾向を見る
継続率、定着率を算出する
継続、定着に影響すると見られるアクションを集計する
アクション回数に応じた定着率を集計する
利用日数に応じた定着率を集計する
ユーザーの残存率を集計する
訪問頻度からユーザーの属性を定義し集計する
訪問種別を定義し、成長指数を集計する
指標を改善する手順を身につける
3 時系列に沿ったユーザー個別のアクションを分析する
ユーザーのアクション間隔を集計する
カートに追加後、購入されているか把握する
登録からの売上を経過日数別に集計する
Chapter6 Webサイトでの行動を把握するためのデータ抽出
1 サイト全体の特徴・傾向を見つける
日次の訪問回数・訪問者数・ページビューを集計する
ページ毎の訪問回数・訪問者数・ページビューを集計する
流入元別に訪問回数やCVRを集計する
アクセスされる曜日、時間帯を把握する
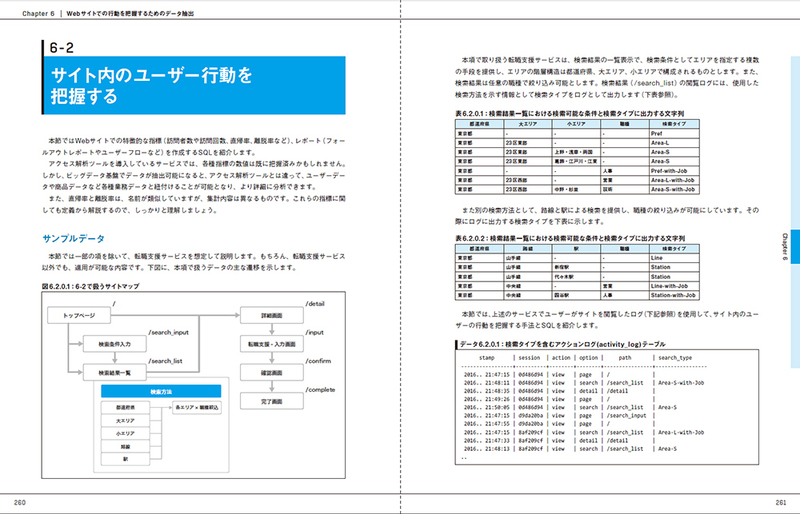
2 サイト内のユーザーの行動を把握する
入口ページと出口ページを把握する
離脱率、直帰率を計算する
成果に結びつくページを把握する
ページの価値を調べる
検索条件毎のユーザー行動を可視化する
フォールアウトレポートを用いてページ遷移を可視化する
サイト内のユーザーフローを把握する
ページを最後まで見ている割合を集計する
ユーザー行動の全体像を可視化する
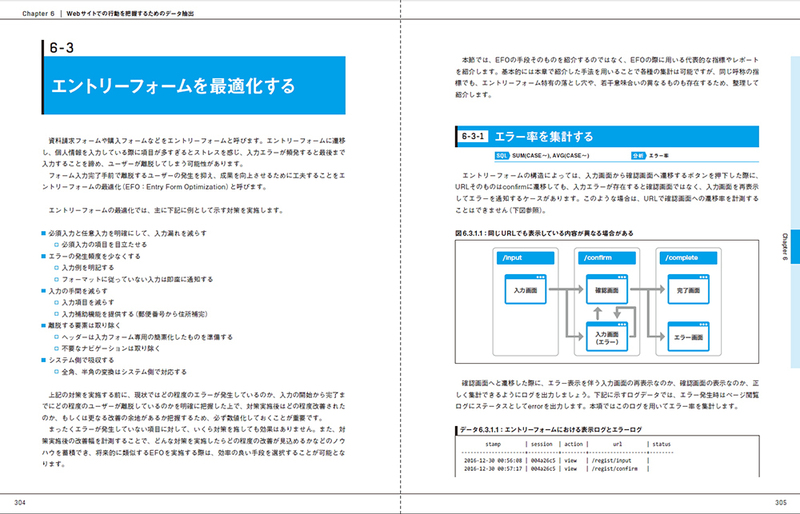
3 エントリーフォームを最適化する
エラー率を集計する
入力~確認~完了までの遷移率を集計する
フォーム直帰率を集計する
エラーが発生している項目、内容を集計する
Chapter7 データ活用の精度を高めるための分析術
1 データ加工による新たな切り口を作る
IPから国、地域を補完する
都道府県に隣接都道府県情報を付与する
土日・祝日を判断できるようにする
一日の集計範囲を変更する
2 異常値を検出する
データの分布を計算する
クローラーを除外する
データの妥当性を確認する
特定のIPからのデータを除外する
3 データの重複を検出する
マスタデータの重複を検出する
ログの重複を検出する
4 複数のデータセットを比較する
データの差分を抽出する
2つのランキングの類似度を計算する
Chapter8 データを武器にするための分析術
1 検索機能を評価する
NoMatch率とそのワードを集計する
再検索率とそのワードを集計する
再検索ワードを分類して集計する
検索離脱率とそのワードを集計する
検索に関する指標を集計しやすくする
検索結果の網羅性を指標化する
検索結果の妥当性を指標化する
検索結果の順位を考慮した指標を計算する
2 データマイニング
アソシエーション分析
3 レコメンド
レコメンドシステムを広義に捉える
このアイテムに興味がある人はこんなアイテムも見ています
あなたにオススメの商品
レコメンドシステムを改善するポイント
レコメンド表示時の改善ポイント
レコメンドに関するその他の指標を知る
4 スコアの計算
複数の値をバランスよく組み合わせてスコアを計算する
値の範囲が異なる指標を正規化して比較可能な状態にする
各データの偏差値を計算する
巨大な数値の指標を直観的にわかりやすく加工する
独自のスコアリング方法を定義してランキングを作成する
Chapter9 知識に留めず行動を起こす
1 データ活用の現場
データの活用方法を考える
データに関わる登場人物を知る
ログフォーマットを考える
データを活用しやすい状態に整える
データ分析のプロセスを習得する
分析のはじめの一歩を踏み出す
相手の職種・役職に応じたレポートを作成する
さらなるデータ活用のスキルを磨く
ビッグデータ時代のデータ分析者に向けて
