
現場のプロが伝える前処理技術 基礎から実践まで学ぶ テーブルデータ/自然言語/画像データの前処理
- 著作者名:石井 大輔(Team AI 代表)、、 漆畑 充(株式会社Crosstab)、 及川大智、 大下健史(BCI)、 オング優也
-
- 書籍:3,762円
- 電子版:3,762円
- B5変型:360ページ
- ISBN:978-4-8399-7001-7
- 発売日:2020年08月31日
- Tweet
- mixiチェック

内容紹介
データ分析、機械学習に携わるすべてエンジニアのための必携書
昨今、データ分析や機械学習の手法は高度になり、また多くの分野で使われるようになってきています。しかし日常業務で扱っているデータは、複雑かつ不完全で、構造化されていないものも多くあり、そのままでは機械学習モデルに投入したり、適切に分析をすることができません。
本書では、そういった不完全なデータを、データ分析や機械学習で扱えるように整える、「前処理」に焦点を当てています。
「データサイエンティストの時間の90%はデータの前処理に費やされ、残りの時間は実際のモデルのトレーニングと展開に費やされる」とよく言われますが、それにもかかわらず、前処理をどのようにすれば良いかについては後回しにされがちです。
本書は、「テーブルデータ」「自然言語」「画像」の3種類のデータを取り上げ、それぞれについての前処理を詳細に説明しています。データに対してどのようなコードを書いて処理するか、ということだけにとどまらず、「現場ではまず何を行うか」「複数のアプローチがあり得る場合、どれを選ぶべきか」といった、プロならではの知恵も多く詰め込みました。
データ分析をこれから仕事にしたい人、すでに現場にいるけれども迷うことが多い方にとって、心強い助けとなる1冊です。
<本書の構成>
Chapter1 本書の概要
Chapter2 テーブルデータの前処理
2-1 テーブルデータの前処理
2-2 テーブルデータの前処理
2-3 データの結合と集約
2-4 テーブルデータの理解
2-5 カテゴリカル変数の処理
2-6 欠損値の処理
2-7 データスケーリング
2-8 データ変換
2-9 次元削減法
2-10 特徴量選択
Chapter3 自然言語の前処理
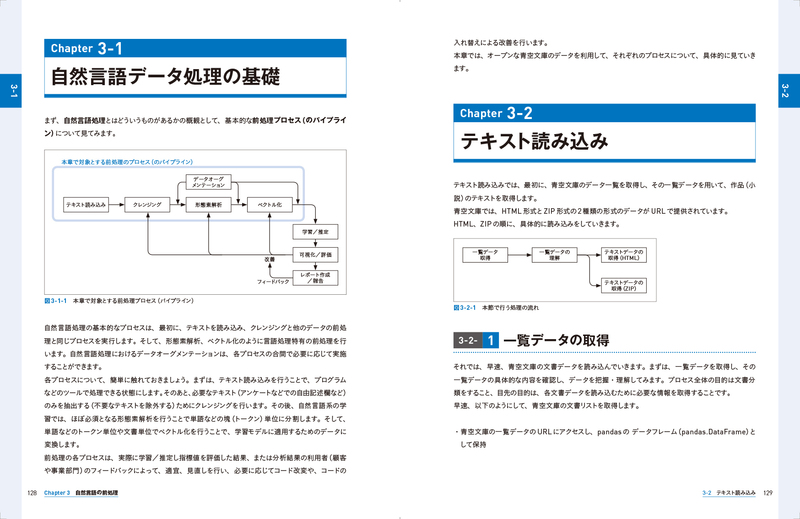
3-1 自然言語データ処理の基礎
3-2 テキスト読み込み
3-3 クレンジング
3-4 形態素解析
3-5 ベクトル化
3-6 オーグメンテーション
Chapter4 画像データの前処理
4-1 画像認識の流れ
4-2 ディレクトリ構成
4-3 画像の撮影
4-4 アノテーション
4-5 画像の読み込みと表示
4-6 切り抜きとリサイズ
4-7 画像の結合とスケーリング
4-8 データの分割
4-9 「データ拡張」で過学習を防ぐ
Chapter5 業界別データ活用動向
5-1 製造業におけるデータ取得と活用
5-2 金融業界におけるデータ取得と活用
5-3 マーケティングにおけるデータ取得と活用
5-4 小売データの取得と活用
※本書のプログラムは、Google Colaboratoryを使って実際に試しながら学べるようになっています。
充実のラインナップに加え、割引セールも定期的に実施中!
商品を選択する
| フォーマット | 価格 | 備考 | |
|---|---|---|---|













備考
■ 石井大輔(いしい だいすけ)
株式会社Kiara(キアラ)代表取締役、Team AI代表
1975年岡山県生まれ。京都大学 総合人間学部ではフランス史と数学(線形代数)ダブル専攻。伊藤忠商事のミラノとロンドンに駐在後、起業。
2016年、機械学習の研究会コミュ二ティTeam AI を立ち上げる。現在メンバー8000人。
FinTech、医療などデータ分析ハッカソンなど700回のイベントを実施。グループチャットのAI 自動化ツールKiara を自社サービスとして構築。
『機械学習エンジニアになりたい人のための本 - AI を天職にする』
(翔泳社)
『データ分析の進め方 及び AI・機械学習 導入の指南』(情報機構)
『AI共存ラジオ 好奇心家族』( TBSラジオ)レギュラー
Twitter:@ishiid
Chapter 5を担当。
■ 漆畑 充(うるしばた みつる)
株式会社Corsstab 代表取締役
2005年慶應義塾大学理工学部卒業、2007年同大学院理工学研究科修士課程修了。
2007年株式会社金融エンジニアリング・グループ入社。金融機関向けデータ分析業務に従事。与信及びカードローンのマーケテイングに関する数理モデルを作成。その後大手ネット広告会社デジタル・アドバタイジング・コンソーシアム株式会社にてアドテクノロジーに関するデータ解析を行う。またクライアントに対してデータ分析支援及び提言/コンサルティング業務を行う。
統計モデルの作成及び特にビジネスアウトプットを重視した分析が得意領域である。その他開発実績としてデータ解析に関する特許を複数取得。
2019年に株式会社Corsstabを創業し今に至る。
Chapter 2を担当。
■ 及川大智(おいかわ だいち)
岩手大学工学院デザイン・メディア工学専攻主席卒業。
国際会議ICISIP2014にて最優秀学生論文賞を受賞するなど国内外で多くの論文を発表。
人工知能やデータ分析の分野で開発会社において新人優秀賞を受賞、データサイエンティストとして独立した後、現在は総合コンサルティングファームに勤務。
大手企業向けのデータ分析や画像認識等のプロジェクトのコンサルティングや業務デザインなどを担当している。趣味は食べ歩きと栄養学の勉強、スキンケア。
Chapter 4を担当。
■ 大下健史(おおした たけひと)
ブレインズコンサルティング株式会社(Brains Consulting, Inc./略記BCI) 最高数理責任者(CMO)
1979年岐阜県飛騨市生まれ。富山大学 理学部 数学科卒。
北陸先端科学技術大学院大学 情報科学研究科 修了。
大学院では、数理論理学領域における一般位相を使った意味論について研究を行う。その後、約10年間システムエンジニアとして職務に従事。
2014年 ブレインズコンサルティング入社。2年後、最高数理責任者に就任、現在に至る。
需要予測システムのエンジン開発、文章生成モデルの検証・プロトタイプ開発など、データによらず各種PoC、プロトタイプ開発の推進などAI/ データ分析に関する案件に幅広く携わる。
Chapter 3を担当。
■ オング優也(おんぐ ゆうや)
シリコンバレーで機械学習、ディープラーニング、確率的最適化やフェデレーテッド ラーニング関連の研究開発を行っているリサーチソフトウェアエンジニア。
ペンシルベニア州立大学情報科学部でデータサイエンスを専攻し、2019に卒業。
過去には感情認識と感情表現の研究や、画像処理などの開発なども行っていた。
Twitter: @YuyaOng
Github: https://github.com/yutarochan
ホームページ: yutarochan.github.io
Chapter 1を担当。
目次
Chapter 1 本書について1-1 本書の内容
1-2 本書の読者対象
1-3 本書の構造
Chapter 2 テーブルデータの前処理
2-1 テーブルデータの前処理
2-1-1 テーブルデータとは
2-1-2 前処理の過程
2-2 テーブルデータの前処理
2-3 データの結合と集約
2-3-1 縦結合
2-3-2 ID単位で値を集約
2-3-3 横結合
2-3-4 まとめ
2-4 テーブルデータの理解
2-4-1 探索的データアナリシス(EDA)
2-4-2 テーブル全体の理解
2-4-3 数値変数の分布
2-4-4 カテゴリカル変数の分布
2-4-5 変数間の相関
2-4-6 まとめ
2-5 カテゴリカル変数の処理
2-5-1 順序ラベルエンコーディング
2-5-2 ワンホットエンコーディング
2-5-3 ターゲットエンコーディング
2-5-4 まとめ
2-6 欠損値の処理
2-6-1 欠損値発生のメカニズム
2-6-2 基本的な欠損処理
2-6-3 欠損を除去する
2-6-4 欠損に値を代入する
2-6-5 欠損カテゴリを新たに作成する
2-7 データスケーリング
2-7-1 Min-Max 法
2-7-2 Zスコア標準化
2-7-3 10進スケールの正規化
2-7-4 スケーリング手法比較
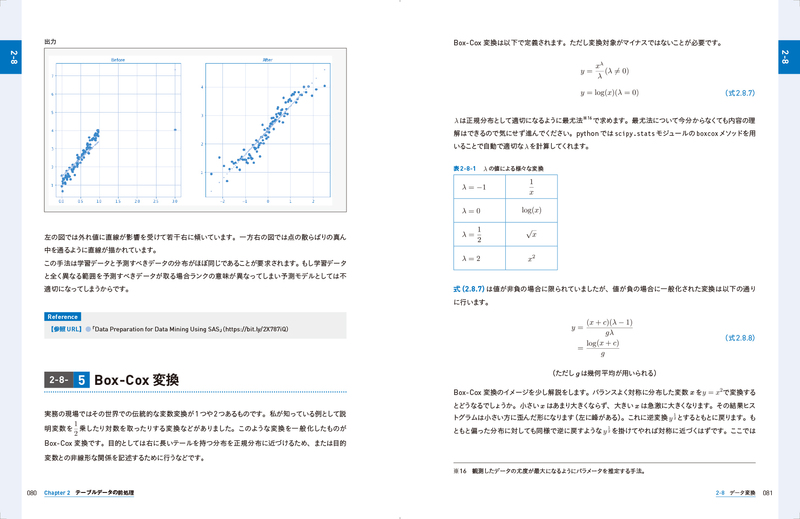
2-8 データ変換
2-8-1 線形変換
2-8-2 二次型変換
2-8-3 変換の非多項式近似
2-8-4 ランク変換
2-8-5 Box-Cox 変換
2-9 次元削減法
2-9-1 次元の呪い
2-9-2 主成分分析(PCA)
2-9-3 因子分析
2-9-4 多次元尺度構成法
2-9-5 局所線形埋め込み
2-9-6 t-SNE
2-10 特徴量選択
2-10-1 特徴量選択の3手法
2-10-2 Filter 法
2-10-3 Wrapper 法
2-10-4 Embedded 法
2-10-5 まとめ
Chapter 3 自然言語の前処理
3-1 自然言語データ処理の基礎
3-2 テキスト読み込み
3-2-1 一覧データの取得
3-2-2 一覧データの理解
3-2-3 テキストデータの取得(HTML)
3-2-4 テキストデータの取得(ZIP)
3-2-5 エンコーディング
3-2-6 ファイル形式
3-3 クレンジング
3-3-1 テキスト文書の不要文字の削除
3-3-2 HTML文書から本文のみ取得/抽出
3-4 形態素解析
3-4-1 MeCab
3-4-2 Janome
3-4-3 SudachiPy
3-4-4 nagisa
3-4-5 Sentence Piece
3-4-6 正規化
3-5 ベクトル化
3-5-1 単語のベクトル化
3-5-2 文書のベクトル化
3-6 オーグメンテーション
3-6-1 データ収集時のオーグメンテーション
3-6-2 形態素解析後のオーグメンテーション
3-6-3 ベクトル化後のオーグメンテーション
3-6-4 その他
Chapter 4 画像データの前処理
4-1 画像認識の流れ
4-1-1 画像認識システム開発の全体を把握する
4-1-2 本章で扱う範囲
4-2 ディレクトリ構成
4-2-1 src
4-2-2 test
4-2-3 model
4-2-4 data
4-2-5 notebook
4-2-6 ディレクトリを作成するコマンド
4-3 画像の撮影
4-3-1 CNNの特性を意識して撮影する
4-3-2 モデル開発者が撮影する
4-3-3 複数回撮影する
4-4 アノテーション
4-4-1 アノテーションの概要
4-4-2 アノテーションのコツ
4-5 画像の読み込みと表示
4-5-1 画像の読み込み
4-5-2 チャネルの順序を入れ変える
4-5-3 画像を表示する
4-6 切り抜きとリサイズ
4-6-1 画像を切り抜く
4-6-2 正方形を縮小する
4-6-3 アスペクト比を変えてリサイズする
4-7 画像の結合とスケーリング
4-7-1 データセットの準備
4-7-2 画像の結合
4-7-3 スケーリング
4-8 データの分割
4-8-1 データセットの準備
4-8-2 Hold out
4-8-3 KFold
4-9 「データ拡張」で過学習を防ぐ
4-9-1 データ拡張の目的:過学習の抑制
4-9-2 適用するデータ拡張手法
4-9-3 データ拡張の適用
Chapter 5 業界別データ活用動向
5-1 製造業におけるデータ取得と活用
5-1-1 概要
5-1-2 背景
5-1-3 例1:生産機器のダウンタイムを避ける目的での異常検知
5-1-4 例2: 画像認識による検品の自動化
5-2 金融業界におけるデータ取得と活用
5-2-1 金融相場のデータ活用
5-2-2 総合的なデータ利用
5-3 マーケティングにおけるデータ取得と活用
5-3-1 背景
5-3-2 ソーシャルメディアマーケティングにおけるデータの活用
5-3-3 Data Management Platform(DMP)
5-4 小売データの取得と活用
5-4-1 キャッシュレスサービスの台頭
Appendix
A-1 本書の実行環境について
