2017.12.14
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第15回 食べ物を見分ける分類器を自作してみよう
今回は、学習済みモデルなどを使わず独自に簡単な分類モデルを構築して学習させ、食べ物の種類を見分けるアプリケーションを作ってみましょう。
1.はじめに
第14回では、Inception-v3のモデルを利用して、転移学習によって花の種類を見分けるアプリケーションを作りました。今回は、Inception-v3のようなモデルを使わずにゼロから分類モデルを構築し、学習させてみます。
Inception-v3は非常に汎用的なモデルで、転移学習を利用すれば任意の独自データに対する画像分類も手軽に実現することができます。しかし分類タスクの対象データによっては、わざわざInception-v3などの既存モデルを利用しなくても、自分で分類モデルを作った方がより軽量のモデルで分類を実現できることもあります。
今回はTensorFlowによる分類モデルを自作して学習させ、それを使って第14回のような画像分類のアプリケーションを作ってみましょう。
2.サンプルアプリのインストール手順
第14回の「3.サンプルアプリのインストール手順」と同様に、Google Compute Engine(GCE)の仮想マシン上で実行します。仮想マシンの作成方法は第9回を参考にして下さい。
コンソール画面の「Compute Engine」→「VMインスタンス」から仮想マシンインスタンスの一覧が確認できます。仮想マシンインスタンスが起動したら、右にある「SSH」ボタンを押します。新しいウィンドウでSSH端末の画面が開いて、自動的にゲストOSへのログインが行われます。ログインした後は、次のコマンドで作業ユーザーをrootに切り替えておきます。
$ sudo -i ←$より右側を入力 |
この後の作業は、すべてrootユーザーの状態で行います。まず、次のコマンドで前提パッケージをインストールします。
# apt-get update# apt-get install -y build-essential python3-pip git |
# git clone https://github.com/sugyan/classifier-sample# cd classifier-sample# pip3 install -r requirements.txt |
これで、準備が整いました。
3.学習用画像データの収集/前処理
今回も、第14回と同様に、FlickrのAPIを利用して画像を収集します。第14回の「4.学習用画像データの収集/前処理」と同じ手順でアプリケーションを作成し、「Key」と「Secret」を取得してください。
classifier-sampleディレクトリ直下のconfig.ini.exampleファイルをconfig.iniにリネームし、中身を正しい「Key」と「Secret」に書き換えてから、download_images.pyを実行します。実際のコードはもう少し後で説明します。
第14回では花の画像を収集して識別アプリを作りましたが、今回は食べ物の種類を識別するアプリを作りたいと思います。画像検索したいキーワードを以下の3種類の麺類に設定しています。
・うどん
・ラーメン
・パスタ
KEYWORDS = { 'udon': 'うどん', 'ramen': 'ラーメン', 'pasta': 'パスタ', |
次のコマンドを実行すると、datasetディレクトリ配下にうどん、ラーメン、パスタのそれぞれの画像が300枚ずつ保存されます。学習データの良し悪しは認識精度に影響するため、ダウンロードした画像を確認し、不鮮明なものやラベルで指定した写真でないものが含まれている場合は取り除いてください(実際のところ、半分ちかくは鮮明でなかったりまったく検索キーワードとは関係ない写真だったりするようです…)。
# mv config.ini.example config.ini ← config.iniにリネーム# vi config.ini ←viでconfig.iniを編集 |
# python3 download_images.py... |
ディレクトリを確認すると次のようになっています。キーワードがフォルダ名になっており、これが学習時のラベルとして使用されます。
dataset/├──pasta│ ├── 10158056824.jpg│ ├── 10272581924.jpg~中略~│ ├── 9723043201.jpg│ └── 9836700865.jpg├── ramen│ ├── 10900220565.jpg│ ├── 11645671474.jpg~中略~│ ├── 9673953582.jpg│ └── 9763583263.jpg└── udon ├── 10145040686.jpg ├── 11773493484.jpg |
これで学習に必要な画像の準備が整いました。
4.モデルの学習
さて、学習用画像データが集まったので、いよいよ分類モデルを構築して学習させます。train.pyを実行すると、datasetディレクトリにある画像を使って学習を開始します。
step 1: loss: 1.389882 (accuracy: 33.333%)step 2: loss: 1.124809step 3: loss: 1.095186step 4: loss: 1.085402step 5: loss: 1.090325step 6: loss: 1.090474step 7: loss: 1.050861step 8: loss: 1.059907step 9: loss: 1.016715step 10: loss: 1.009219step 11: loss: 1.044796 (accuracy: 53.846%)step 12: loss: 1.010567step 13: loss: 0.999018step 14: loss: 1.008261step 15: loss: 0.903128... |
学習ステップが進むごとに少しずつlossの値が減少し、accuracyが上昇していくのが分かります(3クラス分類なので最初は当てずっぽうで当たる確率33%で、正しいですね)。
学習の実行は多少時間がかかりますが、1,000step程度なら小さなインスタンスでも数分程度で完了します。学習が終了すると、その分類モデルのパラメータなどの情報を含むmodel.pbというファイルが生成されます。
ただし、学習用画像を精査せずに「3.」の手順でダウンロードした画像をすべて使用すると、正しくないものも多数混ざってしまっているためあまり精度が上がらないようです。精査したデータのみを使って学習したモデルのファイルも用意してありますので、以下のURLからダウンロードして使っていただくこともできます。以下はダウンロードするためのコマンドです。
5.Webアプリのデプロイと動作確認
学習済みモデルのファイルmodel.pyができれば準備が整いましたので、サンプルアプリ(Webアプリ)をデプロイします。次のコマンドで、アプリを/optにコピーしてください。アップロードしたファイルを管理したいときは、Cloud Storageなどのオブジェクトストレージに保存するようコードを修正してください。
# cp -a webapp /opt/# cp model.pb /opt/webapp |
最後に次のコマンドを実行すると、アプリが起動します。
# cp recognizer.service /etc/systemd/system/# systemctl daemon-reload# systemctl enable recognizer# systemctl start recognizer# systemctl status recognizer● recognizer.service - Noodle Image Recognizer Loaded: loaded (/etc/systemd/system/recognizer.service; enabled; vendor preset: enabled) Active: active (running) since Fri 2017-12-08 10:41:42 UTC; 1s ago Main PID: 9050 (start.sh) Tasks: 3 (limit: 4915) CGroup: /system.slice/recognizer.service ├─9050 /bin/bash /opt/webapp/start.sh └─9051 /usr/bin/python3 /opt/webapp/app.pyDec 08 10:41:42 instance-1 systemd[1]: Started Noodle Image Recognizer. |
この後は、ブラウザからGCEの仮想マシンに設定した静的IPアドレスにアクセスすることで、Webアプリを使用できます。
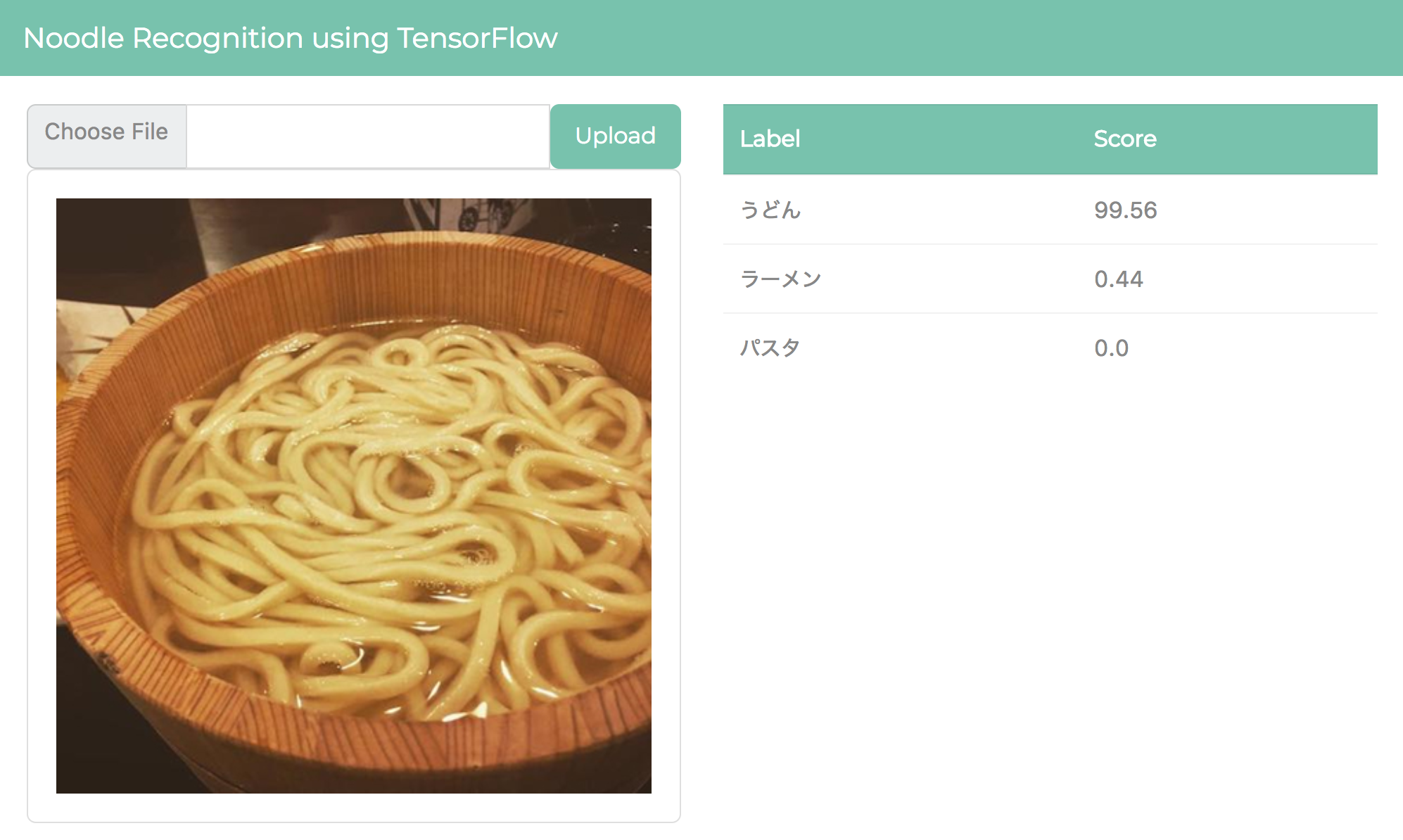
[Choose File]ボタンをクリックし、うどん、ラーメン、パスタいずれかの写真をアップロードすると、種別を推論して確度を表示します。以下の図は、第10回で使用した、Inception-v3に「カルボナーラ」と識別されてしまったうどんの写真(もちろん、これは今回の学習用データとしては使われていません)をアップロードしたところです。見事に99.56という高確度で[うどん]であると推論されました。リベンジ成功ですね。
6. サンプルアプリの解説
モデルの構築・学習はすべてtrain.pyで行っています。ここでは、コードの主なポイントを解説します。コードは、GCPのコンソールでも見られますが、https://github.com/sugyan/classifier-sampleでも確認できます。
まずはcreate_image_lists関数で、datasetディレクトリを走査し、ラベルごとに画像ファイルのパスをまとめています。学習用と評価用に9:1程度の割合で分割しています。
こうして作られた画像データのリストをget_inputs関数に渡すことで、TensorFlowで学習・評価を行うための「画像データ」と「ラベル」をセットにしたmini batchを作成します。学習用には元の画像から中央部分をランダムに切り抜いたり反転させたり、多少のaugmentation(水増し)を行っています。
これらを使ってモデルを学習させることになります。
まず肝心の分類モデルです。inference関数で推論を行います。
def inference(images, class_count, reuse=False, training=True): with tf.variable_scope('model', reuse=reuse): output = tf.identity(images) output = tf.layers.conv2d(output, 20, (3, 3), activation=tf.nn.relu, name='conv1') output = tf.layers.max_pooling2d(output, (3, 3), (2, 2)) output = tf.layers.conv2d(output, 40, (3, 3), activation=tf.nn.relu, name='conv2') output = tf.layers.max_pooling2d(output, (3, 3), (2, 2)) output = tf.layers.conv2d(output, 60, (3, 3), activation=tf.nn.relu, name='conv3') output = tf.layers.max_pooling2d(output, (3, 3), (2, 2)) output = tf.reshape(output, [-1, 5 * 5 * 60]) output = tf.layers.dense(output, 30, activation=tf.nn.relu) output = tf.layers.dropout(output, training=training) output = tf.layers.dense(output, class_count) return tf.identity(output, name='inference') |
細かい説明は省略しますが、64x64のサイズのカラー画像を入力として受け取り、畳み込み&プーリングの層を3回繰り返し、そこからdropoutを利用した全結合層を通して、3クラスへと分類しています。畳み込みネットワークを利用した画像の分類についての詳しい解説は、TensorFlowのチュートリアルを参照してください。
TensorFlowのチュートリアル
https://www.tensorflow.org/get_started/
今回は少し高レベルなAPIであるtf.layersを使用しています。このようにたった数行で分類モデルの定義を書けるので便利ですね。
inference関数に画像データを表すTensorを入力することで推論結果を得ることができますので、次にloss関数で誤差関数を定義します。画像データにひもづく正解ラベルに対し、モデルによる推論がどれくらい正しく行われているかを示し、この誤差の値が少なければ少ないほど正しく推論を行うことができている、ということになります。
def loss(labels, logits): cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits) return tf.reduce_mean(cross_entropy) |
単一分類のタスクに対しては、tf.nn.softmax_cross_entropy_with_logits関数を使うのが一般的です。ここに正解ラベルのTensorと推論結果のTensorを渡すことで、交差エントロピーを算出することができます。ここではその平均値を誤差として利用します。
最後に、学習のためのtraining関数です。モデルの学習とは「誤差」を減少させるように「推論」で利用するパラメータ変数を少しずつ変化させていくことになります。そのための様々なアルゴリズムを利用したOptimizerがTensorFlowには同梱されていますので、どのOptimizerを使ってどの値を減少させるか、を以下のように指定することで学習の手続きを定義することができます。
def training(losses): return tf.train.AdamOptimizer().minimize(losses) |
今回はAdamOptimizerを使用しています。
これでモデルの構築と学習の準備ができました。あとはその学習となる計算を繰り返すだけです。
import tensorflow as tf...def main(): image_lists = create_image_lists(FLAGS.dataset_dir) class_count = len(image_lists) image = get_image(jpeg_data, distortion=True), input_images = tf.placeholder(tf.float32, shape=[None, 64, 64, 3], name='input_images') input_labels = tf.placeholder(tf.int64, shape=[None]) # training training_logits = inference(input_images, class_count) losses = loss(input_labels, training_logits) train_op = training(losses) ... with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(FLAGS.training_steps): training_images, training_labels = get_inputs(...) loss_value, _ = sess.run([losses, train_op], feed_dict={ input_images: training_images, input_labels: training_labels, }) logging_message = 'step {:3d}: loss: {:.6f}'.format(i + 1, loss_value) print(logging_message) |
このようにして、tf.Session()を利用し、定義したtrain_opを繰り返し実行していくことで、少しずつloss_valueが減少するように学習が進んでいきます。
学習が終了したら、そのモデルの定義とパラメータ変数を含む情報を、ファイルに書き出します。
from tensorflow.python.framework import graph_util...def main(): ... with tf.Session() as sess: sess.run(tf.global_variables_initializer()) ... output = graph_util.convert_variables_to_constants(sess, sess.graph.as_graph_def(), ['inference_1']) with open(FLAGS.output_graph, 'wb') as f: f.write(output.SerializeToString()) |
こうして書き出されたファイルは、第14回で利用した学習済みモデルと同様にWebアプリで読み込んで利用することができます。
Webアプリの処理は、バックエンドの分類モデルが切り替わっているだけで 動作はすべて第14回と同じです。
7. 後片付け
サンプルアプリの動作確認ができたら、公開中のアプリは停止しておきましょう。アプリの起動/停止処理は、次のコマンドで行うことができます。
# systemctl stop recognizer ← アプリの停止# systemctl start recognizer ← アプリの起動 |
ただし、アプリを停止しても仮想マシンインスタンスや固定IPアドレスに対する課金は継続します。作成したプロジェクトを削除すれば、課金を完全に停止することができます。プロジェクトを削除する際は、Cloud Consoleの「IAMと管理」→「設定」メニューで、「削除」ボタンを押します。この時プロジェクトIDの入力を求められるので、該当のIDを入力すると削除処理が行われます。
8. まとめ
分類モデルを自作し学習させて画像識別アプリケーションを作る方法を紹介しました。既存のモデルを使わずにすべて自分で作るのは大変そうに思えますが、このように簡単なものであれば数十行~百数十行程度のプログラムで実現させることができます。また、Inception-v3のモデルは85MB程度のファイルになるのに対し、今回の自作モデルはたった300KB程度で、非常に軽いものになっています。精度とのトレードオフにはなりますが、モデルの構造や変数パラメータの数も柔軟に変更して試すこともできますので、転移学習を利用する以外にもこうして簡単なモデルを自作して試してみるのも良いかもしれません。


{kind=link}
{kind=link}
{kind=link}