2017.07.11
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第9回 驚きの性能?! Object Detection APIで物体認識に挑戦
連載第9回では、TensorFlowの開発コミュニティによって公開されている「Object Detection API」を用いて、画像内の複数の物体を認識するアプリを作成します。この後の実行例にあるように、さまざまな物体が含まれた画像に対して、それぞれの物体の位置を的確に検出することが可能になります。
1. はじめに
TensorFlowを用いると、さまざまな機械学習のモデルを自分で作成することが可能です。しかしながら、実用レベルのモデルを作り上げるには、学習データの収集やモデルのチューニングに時間をかける必要があり、それほど簡単に行かないこともあります。このような時に役立つのが、一般公開されている学習済みモデルの再利用です。
ディープラーニングの世界では、研究者が新たに作り出したモデルの構造が論文で公開されると、TensorFlowなどのライブラリを用いて、実際にそのモデルを実装したコードが公開されることがあります。さらに、大量データを用いて学習して得られたモデルのパラメーターもあわせて公開されることがあります。このような学習済みモデルを利用すると、自分で学習処理を行わずにディープラーニングを活用することができます。さらに、転移学習と呼ばれる手法を用いて、独自のデータで追加学習することも可能です。
今回は、TensorFlowのGitHubリポジトリで公開されている、TensorFlow Object Detection APIを利用して、物体認識の学習済みモデルを活用したアプリを作成していきます。
2. Object Detection APIについて
Object Detection APIを利用すると、図1のように、画像ファイルに含まれる物体の種類と、画像内の位置を検出することができます。もう少し正確に言うと、このような機能を実現する機械学習モデルを作成・学習するためのフレームワークを提供することが、Object Detection APIの役割になり、実際にこのフレームワークを用いて学習を行ったモデルのデータがあわせて公開されています。

本記事の執筆時点で公開されているデータは、表1の通りです。それぞれ、COCO(Common Objects in Context)と呼ばれる公開データセットを用いて学習されており、80種類の物体を認識することが可能です。COCO mAPは、学習済みモデルの精度を示す指標で、値が大きいほど、より正確な認識ができることを表します。Speedは、1枚の画像に対する認識処理の速度を表します。
| Model name | Speed | COCO mAP |
|---|---|---|
| ssd_mobilenet_v1_coco | fast | 21 |
| ssd_inception_v2_coco | fast | 24 |
| rfcn_resnet101_coco | medium | 30 |
| faster_rcnn_resnet101_coco | medium | 32 |
| faster_rcnn_inception_resnet_v2_atrous_coco | slow | 37 |
3. サンプルアプリのインストール手順
それでは、さっそくサンプルアプリをインストールして利用してみましょう。今回のアプリは、Webブラウザから利用可能なWebアプリケーションになっており、Google Compute Engine(GCE)の仮想マシン上で実行します。PythonのWebアプリケーションフレームワークである、Flaskを用いて作成されており、Flaskのコードの中からTensorFlowによる認識処理を実行する形になります。
仮想マシンインスタンスの作成
はじめに、準備として、Google Cloud Platform(GCP)にアカウントを登録して、新しいプロジェクトを作成します。この手順については、第0回の記事を参考にしてください。プロジェクトが作成できたら、コンソール画面の「Compute Engine」メニューから「VMインスタンス」を選び、新しい仮想マシンインスタンスを次のような構成で作成します。画像認識の処理にはCPU負荷がかかるので、仮想CPUの個数を多めに設定しています。
・仮想CPUコア:8個
・メモリー容量:8GB
・ゲストOS:Debian GNU/Linux 8 (jessie)
・「HTTPトラフィックを許可する」にチェックを入れる
・「静的IPアドレス」を割り当て
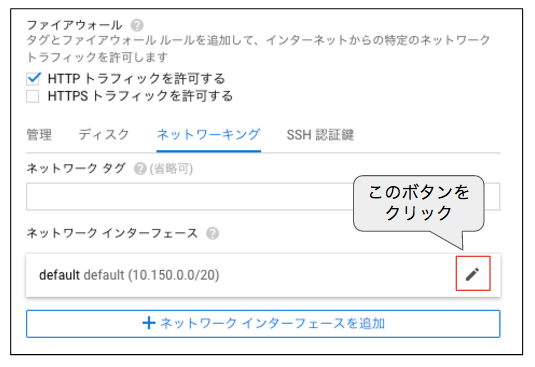
最後の静的IPアドレスを割り当てる際は、インスタンス作成のメニューで「管理、ディスク、ネットワーク、SSH認証鍵」を開いて、「ネットワーキング」のタブから「default」インターフェースの編集ボタン(鉛筆のアイコン)をクリックします(図2)。その後、「外部IP」のプルダウンメニューから「IPアドレスを作成」を選択して、任意の名前を指定します。この時に割り当てられるIPアドレスは、仮想マシンインスタンスを停止しても変化することがなく、外部からアプリにアクセスする際の固定的なIPアドレスとして使用することができます。
コンソール画面の「Compute Engine」→「VMインスタンス」から仮想マシンインスタンスの一覧が確認できます。仮想マシンインスタンスが起動したら、右にある「SSH」ボタンを押します。新しいウィンドウでSSH端末の画面が開いて、自動的にゲストOSへのログインが行われます。ログインした後は、次のコマンドで作業ユーザーをrootに切り替えておきます。
# sudo -i |
この後の作業は、すべてrootユーザーの状態で行います。
前提パッケージとObject Detection APIのインストール
まず、次のコマンドで前提パッケージをインストールします。3行目のpipコマンドでは、実行中にエラーメッセージが表示される場合がありますが、最後に「Successfully installed Flask WTForms Flask-WTF Werkzeug itsdangerous Jinja2 click MarkupSafe」と表示されれば問題ありません。
# apt-get update# apt-get install -y protobuf-compiler python-pil python-lxml python-pip python-dev git# pip install Flask==0.12.2 WTForms==2.1 Flask_WTF==0.14.2 Werkzeug==0.12.2# pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.1.0-cp27-none-linux_x86_64.whl |
続いて、次のコマンドでObject Detection APIのライブラリをインストールします。
# cd /opt# git clone https://github.com/tensorflow/models# cd models/research# protoc object_detection/protos/*.proto --python_out=. |
そして最後に、次のコマンドを実行して、学習済みモデルのバイナリファイルをダウンロードします。
# mkdir -p /opt/graph_def# cd /tmp# for model in \ ssd_mobilenet_v1_coco_11_06_2017 \ ssd_inception_v2_coco_11_06_2017 \ rfcn_resnet101_coco_11_06_2017 \ faster_rcnn_resnet101_coco_11_06_2017 \ faster_rcnn_inception_resnet_v2_atrous_coco_11_06_2017 do \ curl -OL http://download.tensorflow.org/models/object_detection/$model.tar.gz tar -xzf $model.tar.gz $model/frozen_inference_graph.pb cp -a $model /opt/graph_def/ done |
ここでは、表1に示した5種類のモデルをすべてダウンロードしています。実際にアプリを起動する際は、この中から1つを選択して使用する必要がありますが、ここでは、「faster_rcnn_resnet101_coco_11_06_2017」を使用することにします。次のコマンドを実行すると、このモデルがアプリから参照されるようになります。
# ln -sf /opt/graph_def/faster_rcnn_resnet101_coco_11_06_2017/frozen_inference_graph.pb /opt/graph_def/frozen_inference_graph.pb |
アプリのインストールと起動
いよいよ、アプリをインストールして、起動していきます。次のコマンドで、アプリのコードをダウンロードしてインストールします。
# cd $HOME# cp -a tensorflow-object-detection-example/object_detection_app /opt/# cp /opt/object_detection_app/object-detection.service /etc/systemd/system/# systemctl daemon-reload |
このアプリでは、Webブラウザから接続した際に簡易的な認証処理が行われるようになっています。ファイル /opt/object_detection_app/decorator.py をエディタで開いて、次の 'username' と 'passw0rd' の部分を書き換えることで、認証用のユーザー名とパスワードを変更することができます。このままのユーザー名/パスワードで使用する場合は、書き換えなくても構いません。
USERNAME = 'username'PASSWORD = 'passw0rd' |
最後に次のコマンドを実行すると、アプリが起動します。
# systemctl enable object-detection# systemctl start object-detection# systemctl status object-detection● object-detection.service - Object Detection API Demo Loaded: loaded (/opt/object_detection_app/object-detection.service; linked) Active: active (running) since Wed 2017-06-21 05:34:10 UTC; 22s ago Process: 7122 ExecStop=/bin/kill -TERM $MAINPID (code=exited, status=0/SUCCESS) Main PID: 7125 (app.py) CGroup: /system.slice/object-detection.service └─7125 /usr/bin/python /opt/object_detection_app/app.pyJun 21 05:34:10 object-detection systemd[1]: Started Object Detection API Demo.Jun 21 05:34:26 object-detection app.py[7125]: 2017-06-2105:34:26.518736: W tensorflow/core/platform/cpu_fe...ons.Jun 21 05:34:26 object-detection app.py[7125]: 2017-06-2105:34:26.518790: W tensorflow/core/platform/cpu_fe...ons.Jun 21 05:34:26 object-detection app.py[7125]: 2017-06-2105:34:26.518795: W tensorflow/core/platform/cpu_fe...ons.Jun 21 05:34:26 object-detection app.py[7125]: * Running on http://0.0.0.0:80/ (Press CTRL+C to quit)Hint: Some lines were ellipsized, use -l to show in full. |
最後のコマンドは、アプリの稼動状態をチェックするものです。アプリを起動した直後にモデルのデータを読み込む処理が実施されますが、読み込みが完了するまで1分程度かかります。読み込みが完了してアプリが使用可能になると、上記のように「Running on http://0.0.0.0:80/ (Press CTRL+C to quit)」というメッセージが確認できます。
この後は、Webブラウザから、最初に設定した静的IPアドレスにアクセスすることで、アプリを使用することができます。画面上のボタンから拡張子が「jpeg」「jpg」「png」のいずれかのカラー画像ファイルをアップロードすると、画像の認識処理が行われた後に、図3のような結果が表示されます。認識処理には、30秒程度かかることがあるので、すこし気長にお待ち下さい。
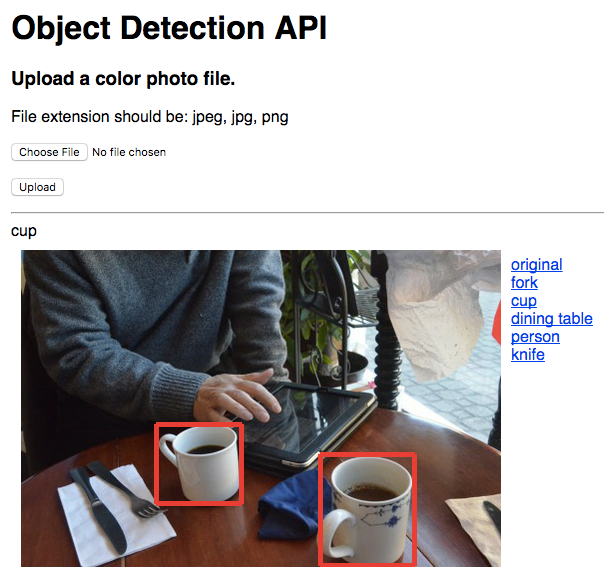
結果表示の画面では、アップロードした画像の右に、認識された物体の名前が表示されます。それぞれの名前をクリックすると、対応する物体の位置が画像内に枠囲みで表示されます。この際、認識の信頼度が高いものほど、太い線で表示されます。図3では、「fork」「cup」「dining table」「person」「knife」などの物体が認識されており、ここでは、「cup」をクリックした状態が示されています。「original」をクリックすると、枠囲みのない、元の画像が表示されます。
この例では、フォークとナイフを区別するなど、かなり正確な認識が行われていることがわかります。小さな物体も識別することができますので、さまざまな種類の物体が写った画像をアップロードして、認識の精度を確かめてみてください。
4. サンプルアプリの解説
サンプルアプリのメインの処理は、ファイル /opt/object_detection_app/app.py で行われています。ここでは、このファイル内のコードの主なポイントを解説します。
クライアントオブジェクトの取得とモデルの初期化
まず、画像認識の処理を行う部分は、専用のクラス「ObjectDetector」としてまとめてあります。次のように、このクラスのインスタンスを作成すると、画像認識を行うためのクライアントオブジェクトが取得されます。
192 | client = ObjectDetector() |
上記のようにクライアントオブジェクトを取得すると、インスタンスの初期化処理の中で、次の関数 _build_graph が実行されて、TensorFlowの「グラフ」の作成が行われます。
91 92 93 94 95 96 97 98 99 100 | def _build_graph(self): detection_graph = tf.Graph() with detection_graph.as_default(): od_graph_def = tf.GraphDef() with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid: serialized_graph = fid.read() od_graph_def.ParseFromString(serialized_graph) tf.import_graph_def(od_graph_def, name='') return detection_graph |
これは、TensorFlowが使用するニューラルネットワークの構造を表わすものになります。少し複雑なコードですが、Object Detection APIで学習したモデルを使用する際のテンプレートのようなものと考えておけばよいでしょう。95行目の変数 PATH_TO_CKPT に学習済みのモデルの構造を保存したバイナリファイルを指定しますが、今回のコードでは、次のように指定がなされています。
55 | PATH_TO_CKPT = '/opt/graph_def/frozen_inference_graph.pb' |
ちなみに、先ほどのアプリをインストールする手順の中で、次のコマンドを実行しました。
# ln -sf /opt/graph_def/faster_rcnn_resnet101_coco_11_06_2017/frozen_inference_graph.pb /opt/graph_def/frozen_inference_graph.pb |
これは、PATH_TO_CKPT で指定されたファイル /opt/graph_def/frozen_inference_graph.pb を /opt/graph_def/faster_rcnn_resnet101_coco_11_06_2017/frozen_inference_graph.pb に対するシンボリックリンクとして作成するもので、ここで、実際に使用されるモデルが決まることになります。言い換えると、一度、アプリを停止して、このシンボリックリンクを修正すれば、他のモデルに切り替えることも可能です。具体的には、次のコマンドを実行していきます。
# systemctl stop object-detection# ln -sf /opt/graph_def/[MODEL NAME]/frozen_inference_graph.pb /opt/graph_def/frozen_inference_graph.pb# systemctl start object-detection |
上記の [MODEL NAME] の部分には、次の中から1つを選んで指定することができます。
・ssd_mobilenet_v1_coco_11_06_2017
・ssd_inception_v2_coco_11_06_2017
・rfcn_resnet101_coco_11_06_2017
・faster_rcnn_resnet101_coco_11_06_2017
・faster_rcnn_inception_resnet_v2_atrous_coco_11_06_2017
クライアントオブジェクトの使用方法
取得したクライアントオブジェクトを用いて、画像認識を行う部分は次のコードになります。
147 148 | image = Image.open(image_path).convert('RGB')boxes, scores, classes, num_detections = client.detect(image) |
変数 image_path には、サーバー上にアップロードして保存したファイルのパスを指定します。認識処理が行われると、次の情報が返却されます。
・boxes : 物体の位置を表わす座標(枠囲みの4隅の相対座標)
・scores : 認識の信頼度(%)
・classes : 認識した物体の種類(ID番号)
・num_detections : 認識した物体の数
一般に複数の物体が認識されるので、box、scores、classes は複数の情報を格納したリストになります。classes に格納されたID番号は、次のコードで物体の名前に変換することができます。ここでは、変数 cls にID番号が格納されています。
164 | category = client.category_index[cls]['name'] |
今回のアプリでは、このようにして取得した情報を用いて、アップロードした画像に枠囲みを書き込むなどの画像処理を行っています。枠囲みの部分を切り出した後に、Cloud Vision APIでさらに詳細な情報を取得するなどの「合わせ技」を利用することもできるでしょう。
5. 後片付け
サンプルアプリの動作確認ができたら、公開中のアプリは停止しておきましょう。アプリの起動/停止処理は、次のコマンドで行うことができます。
# systemctl stop object-detection ← アプリの停止# systemctl start object-detection ← アプリの起動 |
ただし、アプリを停止しても、仮想マシンインスタンスや固定IPアドレスに対する課金は継続します。作成したプロジェクトを削除すれば、課金を完全に停止することができます。プロジェクトを削除する際は、Cloud Consoleの「IAMと管理」→「設定」メニューで、「削除」ボタンを押します。この時もプロジェクトIDの入力を求められるので、該当のIDを入力すると削除処理が行われます。
なお、今回のアプリでは、学習済みのモデルをそのまま使用しましたが、冒頭で触れたように、Object Detection APIでは、独自のデータを用いた追加学習を行うことも可能です。「Quick Start: Distributed Training on the Oxford-IIIT Pets Dataset on Google Cloud」では、Google Cloud Machine Learning Engineを用いた手順が紹介されているので、興味のある方は参考にすると良いでしょう。

