2018.11.05
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第16回 TensorFlow.jsで「じゃんけん」を判別してみよう
今年2018年4月にJavaScriptライブラリTensorFlow.jsがGoogleによって公開され、ブラウザ上で機械学習のモデルの構築・学習や学習済みモデルの実行などが可能になりました。
以前と比べて機械学習がより身近なものになっています。
TensorFlow.jsを使い独自データを利用して、Webカメラからリアルタイムで「じゃんけん」を判定するWebアプリケーションを作ってみましょう。
TensorFlow.jsで「じゃんけん」を判別してみよう

1.はじめに
TensorFlow.jsでは学習済みモデルを使った様々なデモが公開されています。学習済みモデルはGoogleのAPIを通じて利用することができます。
- TensorFlow.js
しかし独自で学習した学習済みモデルを使用する際、少し注意が必要な点がありますので実際にアプリケーションを作成しながらポイントを解説していきましょう。
今回のアプリケーションでは学習はPython 3とKerasを使用し、学習済みモデルを使った推論はNode.jsとTensorFlow.jsを使用します。ライブラリのバーションは以下の通りです。
- Python 3.5.2 / keras 2.1.5 / tensorflow 1.7.0 / tensorflowjs 0.1.1
- Node.js 8.11.1 / tensorflow.js 0.12.0
Pythonの実行環境はGPUが利用できる環境が望ましいです。ハードウェアとしてのGPUを利用できない場合は、クラウドサービスGoogle Colabが無料で利用できるためおすすめです。
- クラウドサービスGoogle Colab
2. サンプルアプリのダウンロード方法
今回作成するアプリは以下のGitHubレポジトリ PonDad/manatee に公開しています。
- PonDad/manatee
こちらに独自データを学習するための「pythonフォルダ」と学習済みモデルを使用したアプリケーションを実行する「nodejsフォルダ」が格納されています。
以下の通り実行すればアプリケーションを試すことができます。
$ git clone https://github.com/PonDad/manatee.git
$ cd manatee/1_sign_language_digits_classification-master/nodejs/
$ npm install
$ npm start
「Start」ボタンで学習済みモデルをTensorFlow.jsを使って読み込み、Webカメラを起動させます。
「Predict」ボタン(推論ボタン)でWebカメラの画像をクリップしcanvas要素へと変換します。画像はTensorFlow.jsを使いテンソル形式へ変換し、学習済みモデルを使って10クラスの分類を行います。
「推論」はsetInterval()メソッドを使って0.1秒ごとに実行します。終了する際は「Clear」ボタンで画面をリロードします。
TensorFlow.jsを実行するブラウザにはGoogle Chromeが一番最適化されています。背景は白い壁などで試してみてください。
3. 画像の前処理
「じゃんけん」の「グー」「チョキ」「パー」の判別を行うため学習用の画像を用意します。
今回はGitHubにApacheライセンス2.0で公開されているデータセット「ardamavi/Sign Language Digits Dataset」を使用します。トルコのANKARA高校の皆さんで作成したデータセットです。
- ardamavi/Sign Language Digits Dataset
github.com/ardamavi/Sign-Language-Digits-Dataset

画像サイズ100x100ピクセルのカラー画像でハンドサイン「0」から「9」まで各228枚用意されています。
最終的には10クラスの分類を行い、「0」なら「グー」、「2」なら「チョキ」、「5」なら「パー」と判別します。
画像データセットは数字ごと学習データ100枚・検証データ50枚・テストデータ50枚に事前に分けておき、学習データ・検証データはKerasのImageDataGeneratorメソッドを使って自動的にKerasに読み込ませます。
「pythonフォルダ」にある rename.py を使って各クラスの画像を連番にし、datagen.py を使って各クラスの画像を学習データ・検証データ・テストデータへ振り分けます。
.hand_sign_digit_data
├── test
│ ├── 0
│ ├── ~中略~
│ └── 9
├── train
│ ├── 0
│ ├── ~中略~
│ └── 9
└── validation
├── 0
├── ~中略~
└── 9この様な階層で画像をフォルダ分けします。
4. 画像の学習
画像の学習はKerasの作者François Cholletさんの著書『PythonとKerasによるディープラーニング』の5.2章「小さなデータセットでCNNを一から訓練する」を参考にします(sign_language_vgg16.py)。
書籍のサンプルは犬猫の2クラス分類でしたが、今回は他クラス分類のため、ImageDataGeneratorのclass_modeをcategoricalで指定します。拡張機能を使い訓練データ1,000枚から32バッチごとに水増しした新たな画像を生成するように指定しました。
全結合層はlayers.Dense(10, activation='softmax')とし、10クラスを活性化関数softmaxで分類します。過学習を防ぐため結合層の前にmodel.add(layers.Dropout(0.5))でドロップアウト層を追加しています。
モデルの損失関数lossはcategorical_crossentropy、オプティマイザoptimizerはadamとしました。
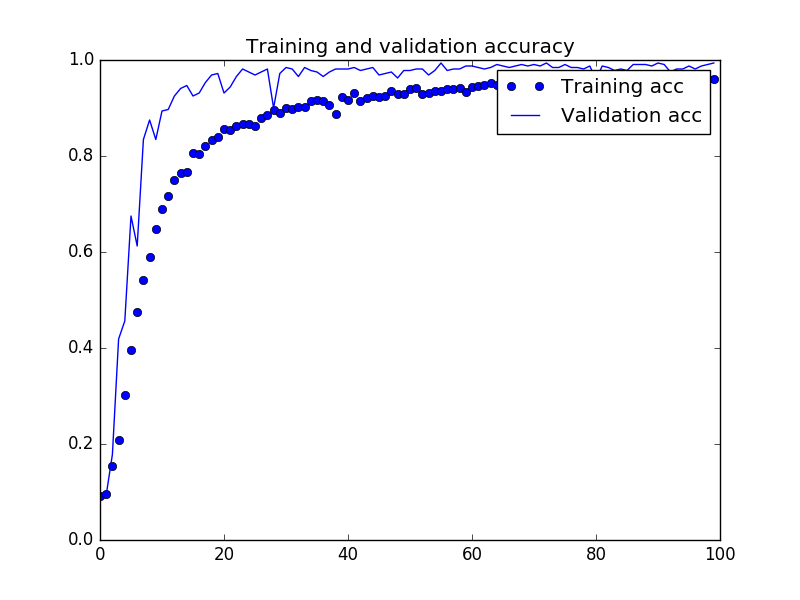
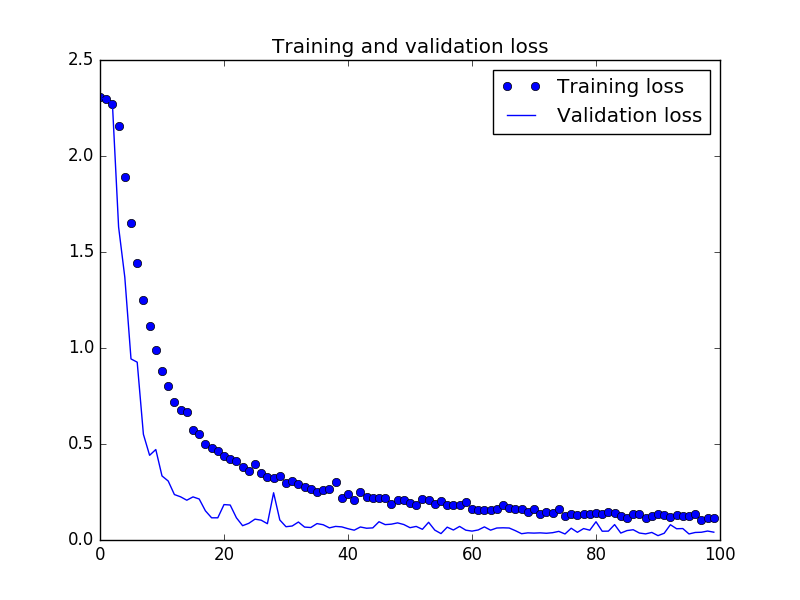
モデル訓練はsteps_per_epoch=100(バッジサイズ32で1エポック当たり100枚の訓練画像生成)、validation_steps=10(バッジサイズ32で1エポック当たり10枚の検証画像)と指定し、epochs=100(100エポック学習)で学習します。
5. TensorFlow.jsモデルへのコンバート
さて、ここからが本番となります。学習したモデルをTensorFlow.jsで読み込み可能な形式に変換します。
コンバート用のPythonモジュールが用意されているので事前にモジュールをインストールしておきます。
$ pip3 install tensorflowjsここでは以下のように記述しモデルのコンバートを行います。
sign_language_vgg16.pyより抜粋
import tensorflowjs as tfjs
save_path = '../nodejs/static/sign_language_vgg16' tfjs.converters.save_keras_model(model, save_path)
tfjs.converters.save_keras_model(model, tfjs_target_dir)メソッドを利用すれば自動的にコンバートを行ってくれます。1
重みファイル、それを読み込むためのjsonファイルと一緒にフォルダに生成されます。階層は以下のようになります。
.sign_language_vgg16
├── group1-shard1of1
├── group2-shard1of1
├── group3-shard1of1
├── group4-shard1of1
├── group5-shard1of2
├── group5-shard2of2
├── group6-shard1of1
└── model.jsongroup1-shard1of1 などとあるのが重みファイルです。1つ目の注意点は、クライアントサイドで読み込む際、これらの重みファイルとjsonファイルを一緒に読み込む必要があります。
6.TensorFlow.jsをクライアントサイドで使う注意点
TensorFlow.jsをクライアントサイドで使用するには静的ファイルにcdnなどを使って読み込めば簡単に使用することができます。2
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js"> </script>これで様々なメソッドを利用できるようになります。しかし2つ目の注意点があります。学習済みモデルはホストされた状態でないと読み込めません。
今回は、Node.jsのフレームワークExpressを利用してローカルサーバーを立て、学習済みモデルをhttp://localhost:8080/sign_language_vgg16/model.jsonとホストされた状態で読み込むようにします。
具体的には以下の通りです。
server.js より抜粋
let express = require("express");
let app = express();
app.use(express.static("./static"));
app.listen(process.env.PORT || 8080, function(){
console.log("Serving at 8080")
});
ローカルサーバーを立てるためNode.jsにサーバーサイドのJavaScript(ここではserver.js)を用意します。
$ npm init
$ npm install express
$ npm startこれでローカルサーバーhhtp://localhost:8080が立てられました。server.jsで静的リソースの格納フォルダをstaticで指定しているので、ここに先ほど作成した学習済みモデルフォルダsign_language_vgg16を格納します。
7.画像データを推論可能な形式に変更する
Pythonで画像処理をする際はOpenCVとNumpyを使うことが多いかと思いますが、JavaScriptとブラウザで同様の処理をする際、有利な点と少し処理が面倒になる点の両方があります。
有利な点としては、HTML5の画像処理に関する様々なメソッドが利用できることです。特にWebカメラの画像処理に関してはnavigator.mediaDevices.getUserMedia()メソッドを利用することでカメラから簡単に画像を取得することが可能です。
また、動画をcanvasとしてキャプチャすることで推論用の画像生成が簡単に行なえます。
処理が少し面倒になるのはNumPyが使えないためPythonと比較するとテンソル処理の記述が冗長になります。
今回のサンプルアプリケーションでの画像処理の流れは以下の通りです。
- Webカメラを使い画像をストリーミングしブラウザに表示する。
- ブラウザに表示された
video要素からcanvas要素を切り出す。 canvasデータを推論可能なテンソルへ変換する。TensorFlow.jsに画像の大きさ変更や次元の追加、テンソルの演算など様々なメソッドがあるのでそれを使う。- 推論可能なテンソルを元に学習済みデータを使い推論を行う。
記述自体はJavaScriptの基本的な処理を組み合わせれば可能です。TensorFlow.jsのメソッドとPython/Kerasの処理を比較しながら中身を解説します。
7-1. Webカメラのストリーミング
predict.jsより抜粋
var video;
function startWebcam() {
video = $('#main-stream-video').get(0);
vendorUrl = window.URL || window.webkitURL;
navigator.getMedia = navigator.getUserMedia ||
navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia ||
navigator.msGetUserMedia;
navigator.getMedia({
video: true,
audio: false
}, function(stream) {
localStream = stream;
video.srcObject = stream;
video.play();
}, function(error) {
alert("Something wrong with webcam!");
});
}
Webカメラの操作はnavigator.mediaDevices.getUserMedia()のドキュメントに沿って記述します。3
7-2. video要素からcanvas要素を切り出す
predict.jsより抜粋
function captureWebcam() {
var canvas = document.createElement("canvas");
var context = canvas.getContext('2d');
canvas.width = video.width;
canvas.height = video.height;
context.drawImage(video, 0, 0, video.width, video.height);
tensor_image = preprocessImage(canvas);
return tensor_image;
}
空要素canvasを生成し、video要素からcanvasの切り出し位置を指定して切り出します。4
7-3. canvasデータを推論可能なテンソルへ変換する
predict.jsより抜粋
function preprocessImage(image){
let tensor = tf.fromPixels(image).resizeNearestNeighbor([100,100]).toFloat();
let offset = tf.scalar(255);
return tensor.div(offset).expandDims();
}
TensorFlow.jsのメソッドで書かれていて最初は少し迷いますが、良く見るとPythonの推論と同じ処理をしていることがわかると思います。
まずtf.fromPixels().toFloat()メソッドでcanvasの画像をNumpy形式のテンソルに変換しています。デフォルトはカラー3チャンネルですが指定をすれば白黒画像にすることも可能です。ここではresizeNearestNeighbor()メソッドで画像サイズ100x100の指定をしています。
続いてtf.scalar()メソッドとtf.div()メソッドを使い画像のRGB階調値255を0~1の値へと正則化します。
最後に.expandDims()メソッドで読み込み画像のチャンネル1を追加し4次元テンソルに変換します。
各メソッドはTensorFlow.jsのリファレンスにて確認することができます。5
predict.pyより抜粋
img = image.load_img(img_path, target_size=(100, 100)) img_array = image.img_to_array(img) pImg = np.expand_dims(img_array, axis=0)/255
Python/Kerasの推論を見てみましょう。画像を100x100サイズのNumPy形式に変換し、推論と同じ4次元にするため、1次元チャンネルを追加しています。最後にRGBのパラメータ数255で割り正則化しています。
処理はPythonでもJavaScriptでも変わりません。
7-4. 学習済みデータを使い推論を行う
predict.jsより抜粋
let model;
async function loadModel() {
model=await tf.loadModel(`http://localhost:8080/sign_language_vgg16/model.json`)
};
前述の通りモデルの読み込みはホストされた状態でなければなりません。tf.loadModel()メソッドを使い読み込みます。
predict.jsより抜粋
const CLASSES = {0:'zero', 1:'one', 2:'two', 3:'three', 4:'four',5:'five', 6:'six', 7:'seven', 8:'eight', 9:'nine'}
async function predict(){
let tensor = captureWebcam();
let prediction = await model.predict(tensor).data();
let results = Array.from(prediction)
.map(function(p,i){
return {
probability: p,
className: CLASSES[i]
};
}).sort(function(a,b){
return b.probability-a.probability;
}).slice(0,5);
results.forEach(function(p){
console.log(p.className,p.probability.toFixed(6))
});
};
推論はmodel.predict()メソッドを使って行います。戻り値の推論値とクラス名を紐付けるのにArray.from()メソッドとmap()関数を使います。6
戻り値の高い順にソートするためsort()メソッド7とslice()メソッド8を利用します。
predict.pyより抜粋
classes = ['zero', 'one', 'two', 'three', 'four','five', 'six', 'seven', 'eight', 'nine']
prediction = sign_language_vgg16.predict(pImg)[0]
top_indices = prediction.argsort()[-5:][::-1]
result = [(classes[i] , prediction[i]) for i in top_indices]
for x in result:
print(x)
Pythonの記述を見てみましょう。この当たりの記述はPythonの方が直感的で分かりやすいですね。
8.リアルタイムで推論する
predict.jsより抜粋
$("#predict-button").click(function(){
setInterval(predict, 1000/10);
});
以上の推論をsetInterval()を使って0.1秒ごとに実行します。
ループの終了は画面のリロードにより行います。
9. まとめ
いかがでしたでしょうか。思ったより複雑な処理はせずにJavaScriptへの置き換えができたのではないでしょうか。
今回のサンプルアプリは低出力PCのローカル環境でも動作させることができますし、HerokuなどのPaaSに簡単にデプロイすることができます(Herokuにデプロイしたサンプルアプリケーションはこちら)。
ブラウザで動作できることで組み合わせ次第で様々なことができそうです。Let's Play機械学習!是非試してみてください。


