2017.11.07
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第14回 転移学習で花の種類を見分けるWebアプリをつくろう
今回は、学習済みモデルを使って独自データを追加学習させる「転移学習」を使ってアプリケーションを作成します。画像認識の学習済みモデルであるInception‐v3をもとに、収集した画像を追加学習させてあらたな学習モデルを作成し、花の種類を見分けられるアプリケーションを作ってみましょう。
1.はじめに
TensorFlowで実用レベルの画像認識を行うには、学習データの収集やモデルのチューニングが必要で、必ずしも思った通りの精度が出ない事もあります。そこで今回は学習済みモデルを使って独自データを追加学習させる「転移学習」を使い、花の種類を推測するWebアプリケーションを作ってみましょう。
2.転移学習とは
まず、おさらいをしておきましょう。機械学習をアプリケーションに組み込む場合、大きく分けて次のパターンが考えられます。

連載[第1回]~[第5回]では、Google Cloud Platformが提供する機械学習APIをつかったアプリケーションをあつかいました。画像認識をおこなうVision APIや、自然言語に対して感情分析や構文解析ができるNatural Language APIを使えば、アプリケーションからはAPIを呼び出すだけです。このように、導入がしやすく、要件に合うものがあればすぐに活用できるという例を紹介しました。また機械学習についての特別な知識が必要ないというのもメリットに上げられます。
次に、連載[第9回]~[第10回]では、学習済みモデルを使ったアプリを実装する例をあつかいました。ここでは、あらかじめ大量のデータをもとにチューニングされた、精度の高いモデルを手軽に活用できる例を紹介しました。一般に機械学習では、学習に適したデータを大量に集めることが困難で、工数のかかる部分になります。そのため、特に画像認識などの分野では、学習済みモデルの活用が有効です。しかし、これらはすでに学習済みのラベルにしか適用できず、たとえば「我が家の猫の判別」「自社工場での製品の不良品を判別」などの独自データに関してはうまく推論できません。そこで今回は「転移学習」をつかって、学習済みモデルと独自の画像をもとに新しい学習モデルを作ります。
転移学習とは、ある領域における問題を効果的かつ効率的に解くため、別の関連したデータや学習結果を再利用する手法のことです。この「ある領域」を転移学習ではドメインと呼びます。画像認識の世界では、多くの事前学習済みのモデルが公開されていますが、これを利用することで新しいドメインへの転移が可能なことが実証されています。たとえば、120万枚/1000クラスからなるImageNetを使って学習させると多くの時間がかかります。そこで、公開されている学習済みの重みを使って再学習させようというのが転移学習です。転移学習では入力に近い部分の重みを固定し、出力に近い部分だけ学習させることで新しいドメインへの適用を行います。転移学習には、少ない学習データと計算時間で、比較的精度の良い独自モデルを作ることができるメリットがあります。
[参考資料]
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture7.pdf
ただし、知識を転移する元のドメインと転移する先のドメインがあらゆるパターンでうまくいくというわけでないため、現在さまざまな研究や取り組みが行われています。
この後は、機械学習をアプリケーションに組み込む際の3つの基本ステップに沿って手順を説明します。

①学習用画像データの収集/前処理
機械学習の精度を決める最も重要なタスクは、学習用データの準備です。今回は、インターネット上で公開されている花の画像を収集し、それを学習データとして用います。
②学習モデルの生成
画像認識の学習済みモデルであるInception‐v3を用いて、①で収集した画像を追加学習させてあらたな学習モデルを作成します。
③Webアプリのデプロイと動作確認
②で作成した学習モデルをWebアプリケーションに組み込み、Google Compute Engine上にデプロイしてサービスを公開します。
3.サンプルアプリのインストール手順
事前準備として、追加学習に使用するスクリプトと、学習後のモデルを使用するサンプルアプリをダウンロードします。今回のアプリは、Webブラウザから利用可能なWebアプリケーションになっており、Google Compute Engine(GCE)の仮想マシン上で実行します。PythonのWebアプリケーションフレームワークであるFlaskを用いて作成されており、Flaskのコードの中からTensorFlowによる画像認識処理を実行します。仮想マシンの作成方法は第9回を参考にして下さい。
コンソール画面の「Compute Engine」→「VMインスタンス」から仮想マシンインスタンスの一覧が確認できます。仮想マシンインスタンスが起動したら、右にある「SSH」ボタンを押します。新しいウィンドウでSSH端末の画面が開いて、自動的にゲストOSへのログインが行われます。ログインした後は、次のコマンドで作業ユーザーをrootに切り替えておきます。
$ sudo -i |
この後の作業は、すべてrootユーザーの状態で行います。まず、次のコマンドで前提パッケージをインストールします。
# apt-get update# apt-get install -y build-essential python3-pip git |
次にサンプルアプリケーションをGutHubからダウンロードし、サンプルアプリケーションで必要なパッケージを次のコマンドでインストールします。
# cd mynavi-transfer-learning/# pip3 install -r requirements.txt |
これで、準備が整いました。
4.学習用画像データの収集/前処理
機械学習において高い精度を出すためには、学習に適したデータを大量に収集し、適切な前処理することが重要です。今回は花の種類を推論するアプリを作成するため、Flickr(フリッカー)という写真の共有のためのサービスを使って画像データを収集します。
まず、次のサイトにアクセスして、[Sign Up]をクリックしアカウント登録します。Flickrの アカウント登録にはYahoo.comのアカウントが必要です。すでにFlickrのアカウントをお持ちの方はログインしてください。
[公式サイト]
https://www.flickr.com/
ログインしたら、以下のURLにアクセスします。
https://www.flickr.com/services/apps/create/
ここで新しくアプリケーションを作成します。商用または非商用かを選択してください。

アプリケーション登録画面で、アプリケーション名を問われますので、任意の名前を入力し[Submit]ボタンをクリックします。すると、APIのアクセスに必要な「Key」と「Secret」が表示されます。このキーがあればAPIに自由にアクセスできますので、GitHubなどのリポジトリに誤ってアップロードしないよう厳重に管理してください。

なお、学習に使う画像データをすでに大量に持っている場合は、そちらを活用しても構いません。
次にGCPのクラウドコンソールでサンプルアプリケーションに含まれる「 image_download.py」を開き、Flickrで取得した「Key」と「Secret」を登録してください。次の例は、APIキーが「ABCDEF」Secretが「xyz」の例です。
# vi image_download.py~中略~# config - FileckrAPI APIKey key = "ABCDEF"secret = "xyz"~中略~ |
このコードは、Fileckrから任意のキーワードに該当する画像をダウンロードします。変数keywordsに検索したいキーワードを設定します。今回は、花の種類を識別するアプリを作成するため次の値をラベルとして設定しています。また、取得する画像の数は変数image_countで指定しています。
・rose バラ
・sunflower ひまわり
・lilium ゆり
# config - search keywordkeywords = ['rose', 'sunflower', 'lilium'] |
次のコマンドを実行すると、datasetディレクトリ配下にバラ、ひまわり、ゆりのそれぞれの画像が20枚ずつ保存されます。学習データの良し悪しは認識精度に影響するため、ダウンロードした画像を確認し、不鮮明なものやラベルで指定した花の写真でないものが含まれている場合は取り除いてください。学習データが不足している場合は、オリジナル画像を反転させたり回転させたりして水増しすることも有効です。このような作業を「データの前処理」と呼びます。
# python3 image_download.pydownload now ... rose~中略~ |
ディレクトリを確認すると次のようになっています。キーワードがフォルダ名になっており、これが学習時のラベルとして使用されます。
dataset/├── lilium│ ├── 11758134974.jpg│ ├── 14152702487.jpg~中略~│ ├── 6934991414.jpg│ └── 8638023406.jpg├── rose│ ├── 11563567033.jpg│ ├── 13463664043.jpg~中略~│ ├── 9341357294.jpg│ └── 97155483.jpg└── sunflower ├── 11779438744.jpg ├── 14345338449.jpg |
これで学習に必要な画像の準備が整いました。今回のスクリプトではFileckrからダウンロードする画像の数を以下の変数で定義しています。ダウンロードする学習データの数によって学習精度がどのように変わるかを比較してみると良いでしょう。
# config - number of images to searchimage_count = 20 |
なお、ダウンロードした画像を確認したいときは次のコマンドを実行して/tmp/dataset.tarというファイルにまとめ、コンソールメニューの[ファイルをダウンロード]を選択し、クライアントPCにダウンロードしてください。同様の手順でクライアントPCからファイルのアップロードも可能です。
# tar cvf /tmp/dataset.tar dataset/ |
5.学習モデルの生成/性能評価
TensorFlowには、画像認識の学習済みモデルであるInception‐v3をもとにして転移学習ができるチュートリアルが用意されており、今回はこれを利用します。Inception‐v3の説明は[第10回]を参照してください。
[公式サイト]
https://www.tensorflow.org/tutorials/image_retraining
再学習を行うretrain.pyは、Inception-v3またはMobilenetによる転移学習のサンプルです。手順3で用意した画像(ラベル名となるフォルダに入れて整理したもの)を入力画像として使用します。ソースコードはこちらで公開されています。
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/image_retraining
このサンプルコードでは、まず、入力画像から特徴量を抽出します。デフォルトではInception-v3の最終層以外の部分を利用して、入力画像を特徴量(ボトルネック値)に変換します。これをディスク上にキャッシュして処理を高速化しています。その後、ボトルネック値を入力として、識別処理を行う部分を再学習します。
コマンドを実行すると学習過程での訓練精度(Train accuracy)/交差エントロピー(Cross entropy)/検証精度(Validation accuracy)が表示されます。Train accuracyが高くValidation accuracyが低いときは、ネットワークが過学習をしていることになります。過学習とはトレーニングセットにだけ特化したチューニングが行われていることです。
retrain.pyは、コマンド引数で学習のためのいくつかのパラメータを設定できますが、今回は次の値を指定します。
| コマンド引数 | 説明 | 今回の設定値 |
|---|---|---|
| image_dir | 学習用の画像データの場所 | dataset |
| how_many_training_steps | 学習の回数 | 500(デフォルトは4000) |
| bottleneck_dir | ボトルネック値のキャッシュを格納するディレクトリ | retrain/bottlenecks |
| model_dir | 転移学習のもとになるモデルを格納するディレクトリ | retrain/inception |
| output_graph | 学習済みのモデルのファイル | webapps/model/retrained_graph.pb |
| output_labels | 学習済みモデルのラベル | webapps/model/retrained_labels.txt |
次のコマンドを実行すると、「dataset」ディレクトリの画像データを用いて、最適化ステップを500回実行し、学習結果をwebapps/modelディレクトリのretrained_graph.pbとretrained_labels.txtに保存します。
# python3 retrain.py \ --image_dir=dataset \ --how_many_training_steps 500 \ --bottleneck_dir=retrain/bottlenecks \ --model_dir=retrain/inception \ --output_graph=webapps/model/retrained_graph.pb \ --output_labels=webapps/model/retrained_labels.txt>> Downloading inception-2015-12-05.tgz 100.0%~中略~INFO:tensorflow:Creating bottleneck at retrain/bottlenecks/sunflower/369121439.jpg_inception_v3.txt~中略~INFO:tensorflow:2017-10-23 04:21:46.460867: Step 0: Train accuracy = 45.0%INFO:tensorflow:2017-10-23 04:21:46.461172: Step 0: Cross entropy = 0.975200INFO:tensorflow:2017-10-23 04:21:46.535274: Step 0: Validation accuracy = 40.0% (N=100)~中略~INFO:tensorflow:2017-10-23 05:31:04.008391: Step 499: Train accuracy = 100.0%INFO:tensorflow:2017-10-23 05:31:04.008590: Step 499: Cross entropy = 0.014764INFO:tensorflow:2017-10-23 05:31:04.084063: Step 499: Validation accuracy = 100.0% (N=100)INFO:tensorflow:Final test accuracy = 100.0% (N=6)INFO:tensorflow:Froze 2 variables.Converted 2 variables to const ops. |
コマンド実行結果のログを確認すると、元になる学習済みモデルをダウンロードし、手順4で収集した画像データをもとに学習が進んでいることが分かります。
学習が終わると、次のようにwebapps/modelディレクトリに学習済みモデルが生成されます。この2つのファイルをWebアプリケーションで使用します。
webapps/├── app.py├── image_rec.py├── model│ ├── retrained_graph.pb <- 学習済みモデルのファイル│ └── retrained_labels.txt <- 学習済みモデルのラベル├── start_app.sh├── static│ └── css│ └── bootswatch.css├── stop_app.sh└── templates └── index.html |
機械学習のモデルの精度については、学習データの数や質、学習の回数などによって変わります。これらのパラメータを変えて精度がどのように変わるかを確認してみてください。
6.Webアプリのデプロイと動作確認
これで準備が整いましたので、サンプルアプリ(Webアプリ)をデプロイします。次のコマンドで、アプリを/optにコピーしてください。また、クライアントがWebアプリにアップロードした画像ファイルを格納するフォルダを/uploadsに作成します。アップロードしたファイルを管理したいときは、Cloud Storageなどのオブジェクトストレージに保存するようコードを修正してください。
# cp -a webapps /opt/# mkdir /uploads |
最後に次のコマンドを実行すると、アプリが起動します。
# cp imagerec.service /etc/systemd/system/# systemctl daemon-reload# systemctl enable imagerec# systemctl start imagerec# systemctl status imagerec● imagerec.service - Flower Image Recognition Loaded: loaded (/etc/systemd/system/imagerec.service; enabled; vendor preset: enabled) Active: active (running) since Mon 2017-10-23 05:33:59 UTC; 1s ago Main PID: 9050 (start_app.sh) Tasks: 3 (limit: 4915) CGroup: /system.slice/imagerec.service ├─9050 /bin/bash /opt/webapps/start_app.sh └─9051 /usr/bin/python3 /opt/webapps/app.pyOct 23 05:33:59 imagerec systemd[1]: Started Flower Image Recognition. |
この後は、ブラウザから、GCEの仮想マシンに設定した静的IPアドレスにアクセスすることで、Webアプリを使用できます。
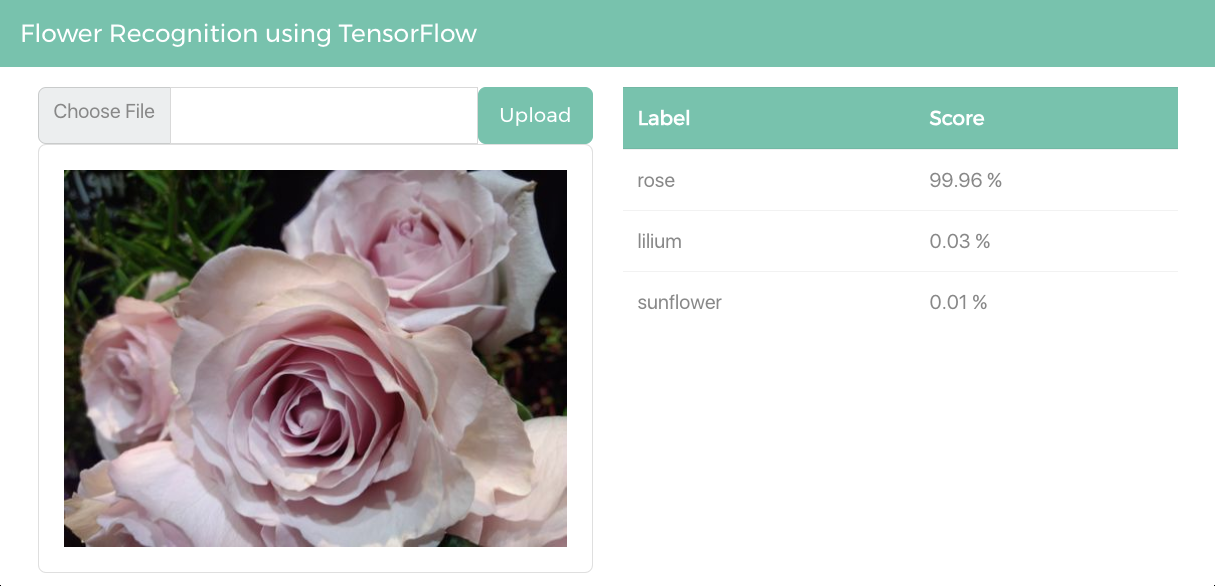
[Choose File]ボタンをクリックし、バラ、ひまわり、ゆりのいずれかの写真をアップロードすると、花の種別を推論して確率を表示します。図の例では、ピンクのバラの写真をアップロードしたところ[rose]である確率が99.96%であると推論されました。
7.サンプルアプリの解説
クライアントからのリクエストを受け付けるWebアプリの処理はwebapps/app.py、機械学習による画像認識の処理はwebapps/image_rec.pyが行います。ここでは、これらのファイル内のコードの主なポイントを解説します。
クライアントからのリクエスト処理
サービスを提供するWebアプリ/opt/webapps/app.pyは、PythonのFlaskフレームワークを使って実装しています。
まず、クライアントからのPOST処理を受け付けると、リクエストに画像ファイルがあればそれをサーバ上の変数UPLOAD_FOLDERに指定したフォルダに保存します。そして、この画像を関数image_recognitionに渡します。この関数image_recognitionは、後述するimage_recのrunメソッドを呼び出して、画像認識を行います。runメソッドの戻り値は、アップロードされた画像から推論されたラベルの値と確率になります。
この値とアップロードした画像のファイルパスをindex.htmlに渡し、推論結果を整形してブラウザに表示します。
def image_recognition(file_path): labels = app.image_rec.run(file_path) return labels~中略~@app.route('/', methods=['POST'])def post(): # file upload and image recognition file = request.files['file'] if (file): file_path =upload_file(file) image_result = image_recognition(file_path) return render_template('index.html',result=image_result, file_path=file_path) return render_template('index.html') |
画像認識の処理
転移学習で生成した学習モデルを使って、画像を推論する処理は/opt/webapps/image_rec.pyで実装しています。
まず、学習済みモデルのラベルとグラフはそれぞれ変数LABELと変数GRAPHに定義します。これは、手順4で生成したものを指定します。変数GRAPHに指定したグラフは、学習済みのモデルの構造を保存したバイナリファイルです。
# config - TensorFlow model fileLABEL = "model/retrained_labels.txt"GRAPH = "model/retrained_graph.pb" |
ImageRecクラスのコンストラクタでは、TensorFlowのグラフの作成が行われます。ここで変数LABELと変数GRAPHで定義したラベルおよびモデルがファイルから読み込まれます。
class ImageRec(): def __init__(self): self.dir_path = os.path.dirname(os.path.realpath(__file__)) self.label_lines = [line.rstrip() for line in tf.gfile.GFile(os.path.join(self.dir_path, LABEL))] self.create_graph() self.sess = tf.Session() def create_graph(self): with tf.gfile.FastGFile(os.path.join(self.dir_path, GRAPH), 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def, name='') |
画像の推論を行う処理は、runメソッドで行います。ここでsess.run(softmax_tensor) で、定義したグラフの出力を計算しますが、その際には入力データを指定する必要があります。DecodeJpeg/contents:0 というkeyに対応するJPEGのバイナリデータを持つ辞書オブジェクトを引数に指定することで、その画像データに対する推論結果を変数predictionsとして得られます。サンプルコードでは、この推論結果をソートしてscoreおよびlabelが格納された辞書をリストに格納し、呼び出し元のWebアプリケーションに返しています。
def run(self, image_path): image_data = tf.gfile.FastGFile(image_path, 'rb').read() # feed the image_data as input to the graph and get first prediction softmax_tensor = self.sess.graph.get_tensor_by_name('final_result:0') predictions = self.sess.run(softmax_tensor, \ {'DecodeJpeg/contents:0': image_data}) ~中略~ return image_info |
8.後片付け
サンプルアプリの動作確認ができたら、公開中のアプリは停止しておきましょう。アプリの起動/停止処理は、次のコマンドで行うことができます。
# systemctl stop imagerec ← アプリの停止# systemctl start imagerec ← アプリの起動 |
ただし、アプリを停止しても、仮想マシンインスタンスや固定IPアドレスに対する課金は継続します。作成したプロジェクトを削除すれば、課金を完全に停止することができます。プロジェクトを削除する際は、Cloud Consoleの「IAMと管理」→「設定」メニューで、「削除」ボタンを押します。この時、プロジェクトIDの入力を求められるので、該当のIDを入力すると削除処理が行われます。
今回は、機械学習を組み込んだ簡単なWebアプリを例として、機械学習に必要な基本ステップご紹介しました。手軽に試せる転移学習を通して、パラメータチューニングや学習用データの数、質の良し悪しで推論結果が変わることを知っていただけたと思います。これらこそが、機械学習における学習精度向上のカギとなります。さらに一歩進んで、「なぜ」を理解したいという方には、秋の夜長にディープラーニングの書籍をひも解いてじっくり読み、手を動かしてみることをお勧めします。


{kind=link}
{kind=link}
{kind=link}
{kind=link}