2017.08.01
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第10回 学習済みInception-v3モデルを使った画像認識アプリケーションを作ろう
今回は第9回に続いて、公開されている「Inception-v3」のモデルを用いて、画像識別のWebアプリケーションを作成します。
1. 画像識別タスクと分類モデル
第9回では、画像内からの物体認識について紹介しました。 さまざまな物体が含まれた画像に対して、画像のどのあたりに物体が写っているかを検出し、その種類についても判断していました。一方、今回扱う画像識別とは、与えられた画像に対し「その画像には何が写っているか」を判別するタスクです。画像識別では、「与えられた画像そのもの」に対して、「写っているものが何か」を分類するということになります。
「何が写っているか」といってもその答えは無限にあり、実際には解決したい課題によって範囲や対象を絞ることになります。 例えば「この手書き文字はどの数字か」であったり「この顔画像はどのアイドルか」であったり「これは有毒なアリか そうではないか」であったり、対象とするドメインは様々です。
ところで 機械学習による画像認識のためのモデルをゼロから作ろうとすると、以下のような準備・作業が必要となります。
1. 解決したいタスクや対象ドメインを決定する
2. 学習モデルを設計・実装する
3. 教師用のデータセットを用意する
4. 集めたデータを使って学習を行う
5. 性能を評価し精度を確認する
大量のデータセットを自分で用意するのはとても大変ですし、そしてある程度のデータを集めたところで実際には良い結果を出せるモデルが簡単に出来上がるわけでもありません。 学習が上手く進まなかったり精度が予想以上に低かったりして 再びモデルの構造やパラメータ数を調整したり、より多くのデータセットを集めたり、2~5のプロセスを繰り返すことになったりします。
こういった苦労を考えると、画像識別のアプリケーションを動かして試してみるのも、とても大変そうです。 しかし幸いなことに、一般画像分類タスクのための学習済みのモデルのデータが各所で公開されていて、我々はそれを再利用することができます。 分類対象のドメインは決まっているため自身が考えるタスクに適するとは限らないですが、ある程度の精度が確認されている学習済みのモデル手軽に利用できる、という点ではとても有用です。 また、そういった一般画像分類タスク用に学習されたモデルのパラメータを一部そのまま利用しFine-Tuningすることで新しいタスクに対しても素早く学習を進められることが知られています。
今回はInception-v3というモデルを再利用することで、自分でデータセットを用意したり、モデルを学習させたりするプロセスを省いて画像識別のWebアプリケーションを作成します。
2. Inception-v3について
Googleによって開発されたInception-v3は、ILSVRCという大規模画像データセットを使った画像識別タスク用に1,000クラスの画像分類を行うよう学習されたモデルで、非常に高い精度の画像識別を達成しています。
TensorFlowで実装されたモデルもGithubで公開されています。
https://github.com/tensorflow/models/tree/master/inception
また、これを簡単に試せるよう モデルデータのダウンロードや展開、そしてサンプル画像を実際に入力して結果を得るところまで実行してくれるスクリプトも用意されています。
TensorFlowをインストールした状態で、以下のコマンドを実行してみましょう(TensorFlowのインストールなど環境の構築については、第7回 を参考にしてください)。
$ git clone https://github.com/tensorflow/models$ cd models/tutorials/image/imagenet$ python classify_image.py |
最初の実行時には、/tmp/imagenet/ディレクトリ以下にモデルデータなどを含めて圧縮したtar.gzファイルのダウンロードを行います(約200MBのディスク容量が必要ですので注意してください)。 一度ダウンロードが完了していれば、それが消されない限り次回以降の実行ではダウンロードを行いません。
classify_image.py は、ダウンロードしたデータを元にInception-v3の分類モデルを復元し、そのモデルに対し 同梱されているcropped_panda.jpgを入力した結果をテキストで出力します。

giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89107)indri, indris, Indri indri, Indri brevicaudatus (score = 0.00779)lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens (score = 0.00296)custard apple (score = 0.00147)earthstar (score = 0.00117) |
確かにパンダの画像である、と言い当てていますね。
3. Webアプリケーションの作成
それでは、このInception-v3を使ったWebアプリケーションを作ってみましょう。 今回も、第9回と同様に Google Compute Engine(GCE)の仮想マシン上で動かします。第9回の「3.サンプルアプリのインストール手順」と同じ手順で仮想マシンインスタンスを起動し、静的IPアドレスも設定します。そしてSSHログインしてrootユーザーの状態で作業していきましょう。
まず、次のコマンドで前提パッケージをインストールします。
# easy_install pip# apt-get update# apt-get install -y git |
アプリケーションをセットアップして、起動していきます。 次のコマンドで、アプリケーションのコードをダウンロードして必要なライブラリのインストールなどを行います。この中の pip install -r requirements.txt の中でTensorFlowもインストールされます。
# cd /opt# cd inception-app-example# pip install -r requirements.txt# cp etc/inception-app.service /etc/systemd/system/# systemctl daemon-reload |
最後に次のコマンドを実行すると、アプリケーションが起動します。
# systemctl enable inception-app# systemctl start inception-app# systemctl status inception-app● inception-app.service - Inception App Demo Loaded: loaded (/etc/systemd/system/inception-app.service; enabled) Active: active (running) since Sun 2017-07-23 08:23:03 UTC; 2s ago Process: 2899 ExecStop=/bin/kill -TERM $MAINPID (code=exited, status=1/FAILURE) Main PID: 2910 (python) CGroup: /system.slice/inception-app.service └─2910 python /opt/inception-app-example/app.pyJul 23 08:23:03 instance-1 systemd[1]: Started Inception App Demo. |
この後は、Webブラウザから設定した静的IPアドレスにアクセスすることで、アプリを使用することができます。 画面上のボタンからJPEGの画像ファイルをアップロードすると、画像の認識処理を行った結果が表示されます。 試しに、元々の学習データのラベルに「含まれていない」うどんの画像を入力してみましょう。

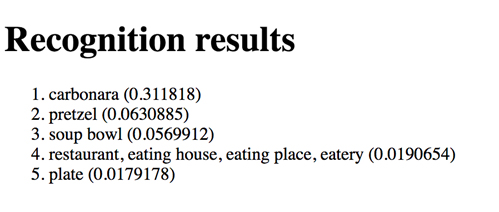
カルボナーラ、というのが最も近いものとして認識されたようです。 外れではありますが、似たような形をした食べ物である、というところでは悪くない結果と言えるでしょう。
4. サンプルアプリの解説
サンプルアプリのメインの処理は、app.py で行われています。 ここでは、このファイル内のコードの主なポイントを解説します。なお、サンプルアプリのコードは https://github.com/sugyan/inception-app-example で確認できます。
Inception-v3モデルのダウンロードと展開は、前述した classify_image.py をコピーして、それらに含まれる関数を利用しています。
import classify_image...classify_image.maybe_download_and_extract()classify_image.create_graph()node_lookup = classify_image.NodeLookup()sess = tf.Session()softmax_tensor = tf.squeeze(sess.graph.get_tensor_by_name('softmax:0')) |
まず maybe_download_and_extract() はデータのダウンロードと展開を行います。 次に create_graph() は展開したグラフ定義ファイルからモデルを復元します。 また、 NodeLookup() はモデルが推論した結果で得られるindexとラベル名の対応辞書を作成します。
tf.Session() によってSessionを定義し、そのグラフから softmax:0 という名前のTensorを取り出します。 これが Inception-v3 モデルの最終出力となります。
次に識別のAPI部分です。
@app.route('/recognize', methods=['POST'])def recognize(): f = request.files['image'] predictions = sess.run(softmax_tensor, feed_dict={'DecodeJpeg/contents:0': f.read()}) results = [] top_k = predictions.argsort()[-5:][::-1] for node_id in top_k: human_string = node_lookup.id_to_string(node_id) score = predictions[node_id] results.append({'label': human_string, 'score': score}) return render_template('result.html', results=results) |
フォームからは multipart/form-data 形式でPOSTリクエストを受け取ります。 Flaskではファイルデータを request.files で得ることができるので、それを使います。
sess.run(softmax_tensor) で、定義したグラフの出力を計算しますが、その際には入力データを指定する必要があります。DecodeJpeg/contents:0 というkeyに対応するJPEGのバイナリデータを持つ辞書オブジェクトを feed_dict 引数に指定することで、その画像データに対する推論結果を得ることができます。
この結果を使って、 argsort() で値の大きい出力を得たもの上位5件を取り出し、そのindexに対応するラベル名を NodeLookup()で得た辞書から取得して表示しています。
5. 後片付け
サンプルアプリの動作確認ができたら、公開中のアプリは停止しておきましょう。 作成したインスタンスを削除するか、もしくはプロジェクトごと削除すれば、課金を完全に停止することができます。
6. まとめ
今回のアプリケーションのように、公開されている学習済みのモデルをそのまま使用することで簡単に画像認識アプリケーションを作成できました。 しかし例で試したようなうどんの写真を正しく識別できるようにするためには、十分な量のうどんの写真に そのラベルを付けた新たなデータセットを用意し、再びモデルを学習させる必要があります。
そのように学習済みモデルを利用してFine-Tuningを行う方法も tensorflow/models リポジトリに載っていますので、興味ある方は調べて挑戦してみると良いでしょう。

