2017.10.16
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第12回 TensorFlowの高レベルAPIを使ってみよう
第7回ではTensorFlowの基本的な概念を説明しました。今回はTensorFlowをより簡単に扱うことができるようになる高レベルAPIについて説明を行います。高レベルAPIを知ることで、TensorFlowがぐっと身近に感じられるようになるでしょう。
1.はじめに
今回ご紹介するサンプルコードはPython3系、TensorFlow v1.3にて動作確認をしています。すでにPython3系、TensorFlow v1.3のTensorFlowの環境が構築できている方はサンプルコードをgithubより取得してください。
$ cd tf-highlevel-sample |
なお、本記事のサンプルコードを閲覧のみする場合は以下よりご覧いただけます。
https://github.com/rindai87/tf-highlevel-sample/
また、環境構築ができていない方向けに、Google Compute Engine(GCE)上に環境構築を行う方法も合わせてご紹介します。GCEで新しいプロジェクトを作成したら、コンソール画面の「Compute Engine」メニューから「VMインスタンス」を選び、新しい仮想マシンインスタンスを作成します(設定はすべてデフォルトで問題ありません)。インスタンスが作成されたら、「SSH」ボタンを押してログインします。このあたりの操作は連載第9回の記事を参考にしてください。
ログインしたら以下のコマンドを実行します。
$ sudo apt-get update -y && sudo apt-get upgrade -y$ sudo apt-get install -y python3-pip git $ pip3 install h5py pillow$ pip3 install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.3.0-cp35-cp35m-linux_x86_64.whl$ cd tf-highlevel-sample |
これで最低限必要なライブラリ等をインストールした状態となります。
2. 高レベルAPIに対するニーズ
TensorFlowに限らず機械学習に注目している方々の目的を改めて整理してみましょう。
1. 機械学習やディープラーニングのアルゴリズムを自分で実装したい
2. 機械学習やディープラーニングを使ってみたい
大きくこの2つに分類されるでしょう。1は、研究者など独自に機械学習のアルゴリズムを実装する必要のある方々が該当すると思います。TensorFlowでは、機械学習を実装する上での多くの便利な機能も提供されています。しかしながら、1以上に2の方が多いのではないでしょうか? 多くの方は、機械学習の実装ではなく、機械学習によって得られる恩恵を利用してアプリケーション化したり、ビジネスに適用したりしたいと思っているでしょう。
機械学習のライブラリとして成功を収めているscikit-learnは、まさに機械学習を実装したい人ではなく機械学習を使い人に焦点を当てられています。多数の機械学習のアルゴリズムが実装されており、共通のAPIを通じて簡単に機械学習のアルゴリズムを実行することができます。パラメータチューニングや機械学習の実行結果を評価する仕組みまで提供されており、利用者の目的に合致した非常に使い勝手の良いライブラリです。
3. TensorFlowにおける高レベルAPI
TensorFlowは、公開当初から長らく非常にプリミティブなAPIしか提供していませんでした。連載第7回で説明したような基本的なプログラミングのパラダイムを理解しつつ、機械学習の知識がある上でアルゴリズムの実装が求められるため、ユーザーにとっては比較的敷居が高い状態でした。いわゆる機械学習/ディープラーニングを使ってみたい、という要望には合致していませんでした。そのため、他の機械学習/ディープラーニングのライブラリと比較してTensorFlowは使いにくいと評価されていた時期もあります。
この問題に対して、TensorFlowはv1.0より高レベルAPIについても積極的に取り組んでいくことが表明されました。執筆現在(v1.3)現在、公開されているTensorFlowのアーキテクチャ図です。

いわゆる「素」のTensorFlowとして利用していたのが「Python Frontend」と示されている部分です。高レベルAPIもいくつかのAPI層から構成されていますが、今回は「Estimator」と「Keras」について説明します。
4. Estimatorの紹介
TensorFlowにおける「呼び出すだけで簡単に機械学習を使えるようにする」を実現するAPI層が「Estimator」です。Estimatorは利用者目線で見ると、機械学習のアルゴリズムが内包されており、機械学習の「学習を行い、評価を行った後に推論を行う」といった一連の処理がすべて共通のAPIとして提供されている仕組みとなります。
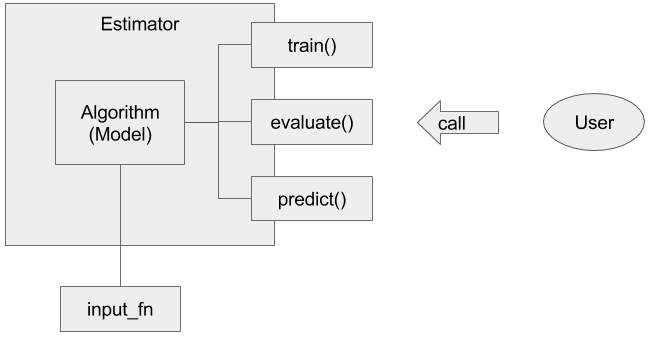
Estimatorでは内包している機械学習のアルゴリズムに対して、学習用にrain()、評価用にevaluate()、推論用にpredict()が提供され、入力用の関数であるinput_fnを通じてデータを受け取るという仕組みになっています。このような仕組みを通じて実装されたアルゴリズムが「pre-made Estimator」として提供されています。もちろん、独自でこの枠組みに沿ってアルゴリズムを実装することもできます。
pre-made Estimatorの例については、「TesnsorFlowのGET STARTED」内の「tf.estimator Quickstart」がちょうどよい題材となっていますので、そちらに沿ってポイントを解説します。
このQuickStartは、以下のようになっています。
・irisというアヤメに関するデータセットを題材とし、アヤメの特徴(がく片の長さ/幅、花弁の長さ/幅)からアヤメの種類(3種類)を当てる
・アヤメの種類を当てるアルゴリズムにはDNN(複数の層を持つニューラルネットワーク)を使う
「tf.estimator Quickstart」のプログラムはPython2系が前提のコードとなっていますので、Python3系で動かす場合は少し修正が必要になります。本記事の「1.はじめに」でご紹介しているサンプルコードではPython3系で動くように修正した版を同梱しています(ファイル名は「estimator_basic.py」)。なお、修正ポイントは下記のとおりになります。
# import urllib# import urllibの部分をurllib.requestに変更import urllib.request |
#raw = urllib.urlopen(IRIS_TRAINING_URL).read()# urllib.urlopen()からurllib.request.urlopen()に変更# read()の後にdecode()を追加raw = urllib.request.urlopen(IRIS_TRAINING_URL).read().decode() |
#raw = urllib.urlopen(IRIS_TEST_URL).read()# IRIS_TRAINING_URLの行と同じ修正を行うraw = urllib.request.urlopen(IRIS_TEST_URL).read().decode() |
プログラムはすべて眺めていただくのが良いですが、ポイントをかい摘んで解説します。
46 47 48 49 50 | # Build 3 layer DNN with 10, 20, 10 units respectively.classifier = tf.estimator.DNNClassifier(feature_columns=feature_columns, hidden_units=[10, 20, 10], n_classes=3, model_dir="/tmp/iris_model") |
58 59 | # Train model.classifier.train(input_fn=train_input_fn, steps=2000) |
68 69 | # Evaluate accuracy.accuracy_score = classifier.evaluate(input_fn=test_input_fn)["accuracy"] |
82 | predictions = list(classifier.predict(input_fn=predict_input_fn)) |
$ python3 estimator_basic.py ←この行の「$」マークより右を入力 Test Accuracy: 0.966667New Samples, Class Predictions: [array([b'1'], dtype=object), array([b'2'], dtype=object)] |
最後の行を見ると、1つ目のデータでは2番目の種類のアヤメらしいと判断され、2つ目のデータでは3番目の種類のアヤメらしいと判断されていることが分かります。
このようにEstimatorによって、利用者目線では、決められたAPIを呼び出していけば機械学習が実行できるようになります。
さらにEstimatorの設計のポイントは、異なるアルゴリズムに入れ替えることが非常に容易であることが挙げられます。例えば、今回はtf.estimator.DNNClassifier()を使っていますが、これを同じくpre-made Estimatorとして提供されているtf.estimator.LinearClassifier()を使ってもプログラムの構造として大きな変化は起きません。
同じく、train()により学習モデルを構築し、evaluate()でその結果を評価し、最後に未知のデータに対してpredict()を適用する、という流れのままです。これにより、様々なアルゴリズムを試しやすくなるという効果も得られます。
このように、Estimatorが導入されたことによって、機械学習のアルゴリズムについては深くは理解していないが使ってみたい、という方が簡単にEstimatorとして提供されているアルゴリズムを手持ちのデータに試してみることができるようになりました。
これはすでにsckit-learnが達成している世界ではあります。しかしながら、最も大きな違いはEstimatorの裏側がTensorFlowであることです。本記事では取り扱いませんがEstimatorはTensorFlowの枠組みで動くため、GPU上での動作や分散処理、Cloud ML Engine上での実行など、TensorFlowで受けられる恩恵も受けられるように設計されています。まさにTensorFlowを使った機械学習が簡単に扱えるようになるための仕組みなのです。
5. Estimatorの現状
非常に便利なEstimatorですが、まだ公開されて日が浅いということもあり、Estimatorとして実装され公開されているアルゴリズムの数が圧倒的に少ないです。
現在公開されているEstimatorは、EstimatorのAPIのページから確認できます。現状では、Estimatorについては利用したいアルゴリズムが実装されていないケースが多々あります。そのため、もう少し実装済みのアルゴリズムが増えてくるのを待つ、あるいは自分でアルゴリズムを実装する際には、社内や他のプロジェクトで再利用することを見越してEstimatorの枠組みに沿っておく、というのが良い付き合い方となるでしょう。
そこで、やはりTensorFlowを利用する場合は、機械学習のアルゴリズムを自身で1から実装する必要が出てきます。その時にTensorFlowの低レベルなAPIを使ってアルゴリズムを実装するのは少々気の重い作業となります。そこで活躍するのが「Keras」です。
6. Kerasの紹介
Kerasはアルゴリズムの実装を簡単にしてくれるAPI層です。Kerasは、もともとはTensorFlowとTheanoという2つのライブラリをバックエンドに持つことができ、開発者がアルゴリズムの実装に集中できることを目的として誕生した、ディープラーニングアルゴリズムの開発に特化したラッパーライブラリでした。
サードパーティのライブラリではありましたが、非常に使い勝手がよくTensorFlowユーザーの多くがKerasを使っているという状態でした。この点が注目され、TensorFlowのv1.0公開時に、KerasがTensorFlowに統合され、Kerasの機能を「tf.keras」というAPI層で利用できるようになると発表されました。このことにより、Estimator内でアルゴリズムを実装する部分にKerasを利用することができるようになります。
つまり、Kerasを利用して機械学習のアルゴリズムを実装し、Estimatorの枠組みにより共通の外部公開のAPIを通じてユーザーに機械学習のアルゴリズムを利用してもらえるようになります。
図3にKerasの位置付けを図示しました。
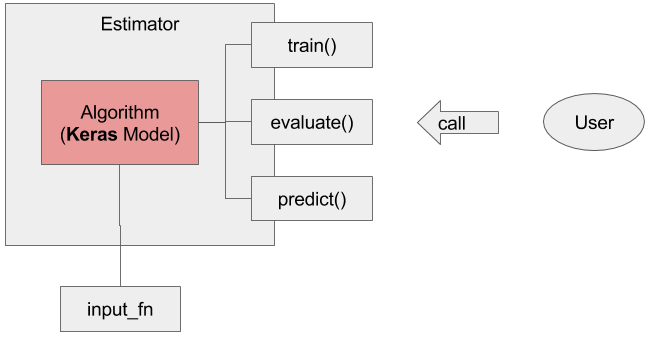
ロードマップ公開時はこの統合はv1.3で完了する予定でしたが、現在の所、まだtf.kerasというAPI自体は提供されておらずtf.contrib.kerasというAPIが提供されるにとどまっています。
使い勝手が良いと言われるKerasの雰囲気を見て見るために、irisデータを分類するコード例のKeras版を見てみましょう。「Pre-made Estimator」と同じくDNNでirisデータを分類するモデルを構築するプログラムです。本記事のサンプルプログラムに同梱されています(ファイル名は「keras_iris.py」)です。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | # tf.estimator Quickstartによってirisデータがすでにローカル環境に# 存在している前提のプログラムです。import numpy as nptraining_data = np.loadtxt('./iris_training.csv', delimiter=',', skiprows=1)train_x = training_data[:, :-1]train_y = training_data[:, -1]test_data = np.loadtxt('./iris_test.csv', delimiter=',', skiprows=1)test_x = test_data[:, :-1]test_y = test_data[:, -1]# ここからがKerasの処理import tensorflow as tfimport tensorflow.contrib.keras as kerasSequential = keras.models.SequentialDense = keras.layers.Densebackend = keras.backendnum_classes = 3train_y = keras.utils.to_categorical(train_y, num_classes)test_y = keras.utils.to_categorical(test_y, num_classes)# モデルの定義model = Sequential()# ネットワークの定義model.add(Dense(10, activation='relu', input_shape=(4,)))model.add(Dense(20, activation='relu'))model.add(Dense(10, activation='relu'))model.add(Dense(3, activation='softmax'))# モデルのサマリの確認model.summary()# モデルのコンパイルmodel.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])# 学習history = model.fit(train_x, train_y, batch_size=20, epochs=2000, verbose=0, validation_data=(test_x, test_y))# 学習モデルの評価score = model.evaluate(test_x, test_y, verbose=0)print(score[1])# 未知のデータに対しての適用result = model.predict_classes(np.array([[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]], dtype=np.float32))print(result)backend.clear_session() |
以下のようにこのプログラムを実行することで結果を確認することができます。
$ python3 keras_iris.py ←「$」から右を入力_________________________________________________________________Layer (type) Output Shape Param # =================================================================dense_1 (Dense) (None, 10) 50 _________________________________________________________________dense_2 (Dense) (None, 20) 220 _________________________________________________________________dense_3 (Dense) (None, 10) 210 _________________________________________________________________dense_4 (Dense) (None, 3) 33 =================================================================Total params: 513Trainable params: 513Non-trainable params: 0_________________________________________________________________0.966666638851[[ 3.61802595e-05 9.99962330e-01 1.37085647e-06] [ 3.91774711e-06 1.80593178e-01 8.19402933e-01]] |
今回はKerasの提供する便利な機能を1つ追加しています。それがmodel.summary()です。その名の通り、モデルのサマリを出力してくれる機能で、この出力を見ると、全部で4つの層(中間層3つ+出力層)があり、中間層はそれぞれが10, 20, 10のユニットでできていることが分かります。
また、この出力の嬉しいポイントとして、パラメータの数が示される点があります。Total Params: 513となっている通り、このモデルでは全部で513個のパラメータを調整することが、すなわち学習となります。いわゆる「ディープラーニングは計算量が多くて処理が大変」と言われる所以は、このパラメータが数百万、数千万個になってしまうためです。
次に、テストデータに対して精度を調べ、0.966、すなわち約97%で正解が得られているという結果となっています。最後にこの学習モデルを用いて、未知のデータを分類しています。2つのデータを与えた、3つのアヤメのうち、どのアヤメらしいか、ということが数値で出力されています。数値の大きなものほど、そのアヤメらしさが大きいということを表すため、1つ目のデータでは2番目の種類のアヤメらしいと判断され、2つ目のデータでは3番目の種類のアヤメらしいと判断されていることが分かります。
さて、サンプルコードに話を戻します。Pre-made EstimatorとKerasはレイヤーが違うものなので当然といえば当然ですが、Kerasではアルゴリズムを一から実装しています。
しかし、TensorFlowの基礎的な概念(連載第7回を参照)であるPlaceholderやVariable、Sessionなどは隠蔽されているため、keras利用者はTensorFlowを意識せずに機械学習のアルゴリズムを実装することができます。また、Kerasは機械学習における各種処理をちょうど良い粒度でAPI提供してくれています。例えば、ニューラルネットワークの層を追加するのはmodel.add()、層の定義はDense()、という具合にかなり直感に沿う形でモデルを記述することができます。
7. Kerasを使ったInception-v3による画像分類
Kerasの雰囲気はわかっていただけたと思いますが、実際どのくらい使い勝手が良いものなのでしょうか? 実はKerasは画像処理や自然言語処理を扱う時、さらにその使い勝手の良さが体感できます。
以下では連載第10回で紹介されたInception-V3による画像分類をKerasによって実行してみます。KerasではInception-V3などの著名なモデルを学習済みの状態で簡単に取り扱う仕組みが提供されています。
今回は画像処理を行うため、以下のように追加で2つのPythonモジュールをインストールしてください。いずれもKerasが内部的に必要とするモジュールです(「1. はじめに」で、GCE上に環境を構築された方は以下のコマンドの実行は不要です)。
$ pip install h5py pillow |
Kerasで学習済みのInception-v3を利用した画像分類のサンプルコード(ファイル名は「keras_image.py」)は以下のようになります。プログラムファイルと同じディレクトリ階層に入力画像がある前提となっています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import numpy as npimport tensorflow as tfimport tensorflow.contrib.keras as kerasimage = keras.preprocessing.imageinception_v3 = keras.applications.inception_v3preprocess_input = keras.applications.inception_v3.preprocess_inputdecode_predictions = keras.applications.inception_v3.decode_predictionsmodel = inception_v3.InceptionV3(weights='imagenet')img_path = './elephant.jpg'img = image.load_img(img_path, target_size=(299, 299))x = image.img_to_array(img)x = np.expand_dims(x, axis=0)x = inception_v3.preprocess_input(x)preds = model.predict(x)print('Predicted:', inception_v3.decode_predictions(preds, top=3)[0]) |
プログラム内で入力画像としている「elephant.jpg」は、フリー素材のサイトで入手した象の画像を与えています。
プログラムの初回実行時はInception-V3をダウンロードする必要があるため少々時間がかかります。また、プログラムの出力はInception-V3によってもっともらしいと判断された上位3つのカテゴリとなります。今回の結果は以下のようになりました。
$ python3 keras_image.py ←「$」より右を入力Predicted: [('n02504458', 'African_elephant', 0.57746637), ('n01871265', 'tusker', 0.31566802), ('n02504013', 'Indian_elephant', 0.039047066)] |
実はこの写真はアフリカ象というタイトルがついている写真であり、見事にInception-V3はアフリカ象と判断したようです。ぜひ様々な入力画像でどのような結果が出るかを試してみてください。また、KerasではInception-V3以外にも、VGGやResNetというInception-V3と同じように著名で高性能なモデルを学習済みの状態で利用することができます。Kerasはドキュメントの日本語化が進んでいますので、是非参考にしてみてください。
拍子抜けするほど簡単に画像分類ができました。しかも、Inception-V3という画像認識のコンテストで優秀な成績を収めるモデルを使えるため、簡単に高性能な画像分類ができます。Keras自体が画像処理を行う関数を提供してくれているため、画像の扱いにも特別困ることはありません。
8. 学習済みモデルの限界と発展としての転移学習
しかしながら、色々な画像を分類させていくと1つの問題に気付くと思います。それは、画像を分類するクラスが固定されてしまっている点です。Inception-v3はImageNetというコンテストで好成績を収めたモデルであり、ImageNetは画像を全部で1000クラスに分類するコンテストです。そのため、分類したい画像がImageNetの1000クラスに入っているものでないとあまり役に立ちません。とはいえ、1からInception-V3に匹敵するような精度のモデルを作ることも容易ではないでしょう。
そのような時に取られる手法に転移学習というものがあります。転移学習とは、学習済みモデルを活かしながら追加で学習を行うようなイメージの手法となります。1からモデルを学習するよりも少ない学習データと計算時間で精度の良いモデルを獲得できる可能性があります。
Kerasでは転移学習に取り組むための機能も提供されています。もしInception-V3を始めとした学習済みモデルをさらに活用されたい方は、ぜひ、転移学習についても調べてトライしてみてください。
9. 終わりに
今回は、TensorFlowの高レベルAPIに関する基本的な概念から、2つの大きなトピックであるEstimatorとKerasを取り上げて説明しました。EstimatorとKerasはTensorFlowを使う上で敷居を下げてくれる大変便利なものです。TensorFlowを利用するという立場で、EstimatorとKerasを積極的に利用していくと良いと思います。
最後に、Kerasについての正確な情報も補足しておきます。少しややこしいのですが、ラッパーライブラリとして当初から存在していたKerasはそのまま開発が継続されており、並行して同種の機能がTensorFlow内でも提供される、という状態となっています。ラッパーライブラリとしてのKerasはバックエンドはTensorFlowに限らず、Theano、それに CNTK も利用できるようになっています。Kerasのモデルの記述のしやすさの恩恵は、TensorFlowユーザーに限らず受けることができるものとなっています。

