2017.06.23
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第7回 TensorFlowの環境を構築してみよう
今回からはTensorFlowに焦点をあてて連載を進めて行きたいと思います。まず今回はTensorFlowの導入を行います。TensorFlowとは何なのか、どのような枠組みのものなのかを理解いただき、実際にTensorFlowの環境を構築することをゴールとしたいと思います。
1. TensorFlowとは?
TensorFlowとは2015年11月にGoogleがオープンソース化した機械学習ライブラリです。本家のサイトを見ると、"An Open-source software library for Machine Intelligence"と書かれていますので、直訳すると「機械知能のためのオープンソースソフトウェアライブラリ」となります。TensorFlowは2015年の公開以来、大きな注目を集め続けています。着実にバージョンアップを続け、2017年2月にはTensorFlow Dev SummitというTensorFlowのみを扱ったイベントが開催されました。TensorFlow Dev SummitではTensorFlowのバージョン1.0が公開され、これ以降は、APIは安定し、本番環境で積極的に使えるもの、というアピールがなされました。また、Kerasの統合など、いくつかの重要なロードマップも提示されました。
TensorFlowに関するよくある勘違いとして、TensorFlowはディープラーニング専用のライブラリである、というものがあります。しかし、実態は大きく異なります。TensorFlowとは大規模な機械学習を実行するためのライブラリであり、大規模な機械学習を実行するために、分散処理やGPUをうまく扱うような機能が提供されています。また、機械学習のアルゴリズムを実装する際に必要な機能一式も提供されています。ディープラーニングに関しても必要となる多くの機能が提供されています。ディープラーニングは機械学習の一種であり、計算に必要なリソースが非常に大きいため、GPUなどのデバイスや分散処理をうまく扱える実行基盤としてTensorFlowは非常に人気があります。
また、TensorFlowには可視化ツールであるTensorBoardや、機械学習モデルをサービングするための仕組みであるTensorFlow Servingといった、機械学習を試行錯誤する上で手助けになるツールやプロダクション環境で機械学習を運用するために必要になる仕組み等も合わせて提供されています。
執筆時点でのTensorFlowの現在の最新バージョンは安定版で1.2です。今回登場するサンプルコードはV1.2での動作確認済みのものとなります。
2. TensorFlowの基本
それではここからは、TensorFlow自体の基本について学んでいきましょう。機械学習という観点から離れると、純粋なTensorFlowの処理の概要は以下のようになっています。
・テンソル(後述)の演算グラフを作ることで処理内容を定義する
・演算の単位をオペレーションと言う
・演算グラフの単位をセッションと言う
・演算グラフでは、定数、変数、プレースホルダを宣言できる
・作ったグラフはデバイス上に展開して実行する
これだけではイメージしづらいと思います。簡単な計算処理を通じて、TensorFlowの基礎的な処理の流れが分かるようなサンプルコードを用意しました。
足し算(演算:Operation)
まずは足し算を行うことを通じて演算の概念について理解しましょう。TensorFlowで1+2の足し算を行うコード例は以下のようになります。
import tensorflow as tf
# 入力となる定数の定義
x = tf.constant(1, name="x")
y = tf.constant(2, name="y")
add_op = tf.add(x, y)
with tf.Session() as sess:
print(sess.run(add_op))
サンプルコード1を実行すると以下のような結果が得られるはずです。
3
このサンプルコードでは、tf.constant()を使って定数の1と2を定義しています。その後、2つの入力を足し合わせるtf.add()によって定数の足し算を行う演算add_opを作成しました。最後に、セッションを作りsess.run()にadd_opを渡すことで足し算を実行しています。すなわちsess.run(add_op)は結果として3を得ることができます。
この処理は内部的にはグラフで表現されていて、その演算グラフは次のようになっています。
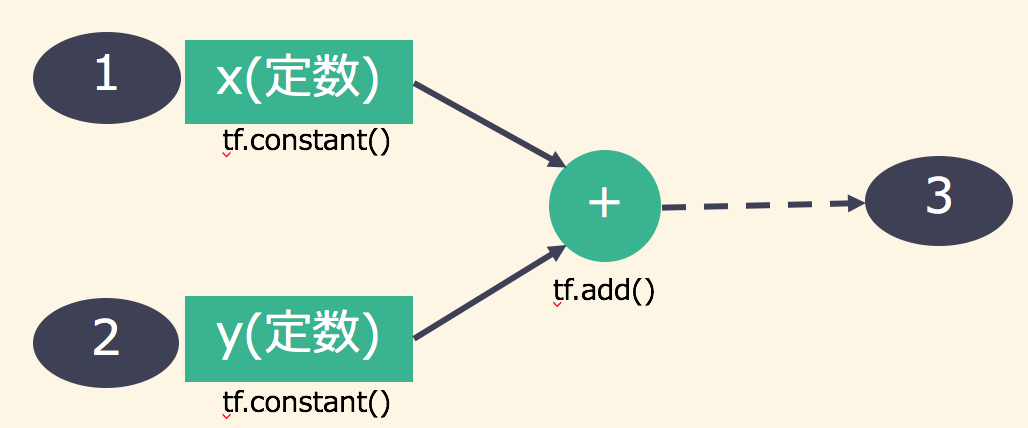
カウントアップ(変数:Variable)
次に、カウントアップを行うことによって変数の概念について理解しましょう。TensorFlowでカウントアップを行うコード例は以下のようになります。
import tensorflow as tf
# cntという変数の定義
cnt = tf.Variable(0, name="cnt")
inc = tf.constant(1, name="inc")
# カウントアップ
add_op = tf.add(cnt, inc)
# cntの値を更新
up_op = tf.assign(cnt, add_op)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# カウントアップを計3回の実施
print(sess.run(up_op))
print(sess.run(up_op))
print(sess.run(up_op))
サンプルコード1にはなかったtf.Variable()というものが登場しています。tf.Variable()はいわゆる変数の働きをするもので、任意の値を保存しかつ再代入可能となります。今回はtf.Variable()によって作られたcntがカウンターの役割を果たします。足し算の例と同じくtf.add()によってカウンターに1を加える足し算の演算をadd_opとして定義しています。ポイントは次のtf.assign()です。tf.assign()は定義した変数への割当を行う演算ですが、tf.assign(cnt, add_op)とすることで、cntに1を加えた結果(add_op)をcntに再度代入する演算up_opを定義しています。最後に作ったグラフを実行する前に、tf.global_variables_initializer()によって変数の初期化を行います。3度カウントアップを実行し順次出力しているため、サンプルコード2を実行すると以下のような結果が得られます。
1 2 3
サンプルコード2は以下のようなグラフになっています。
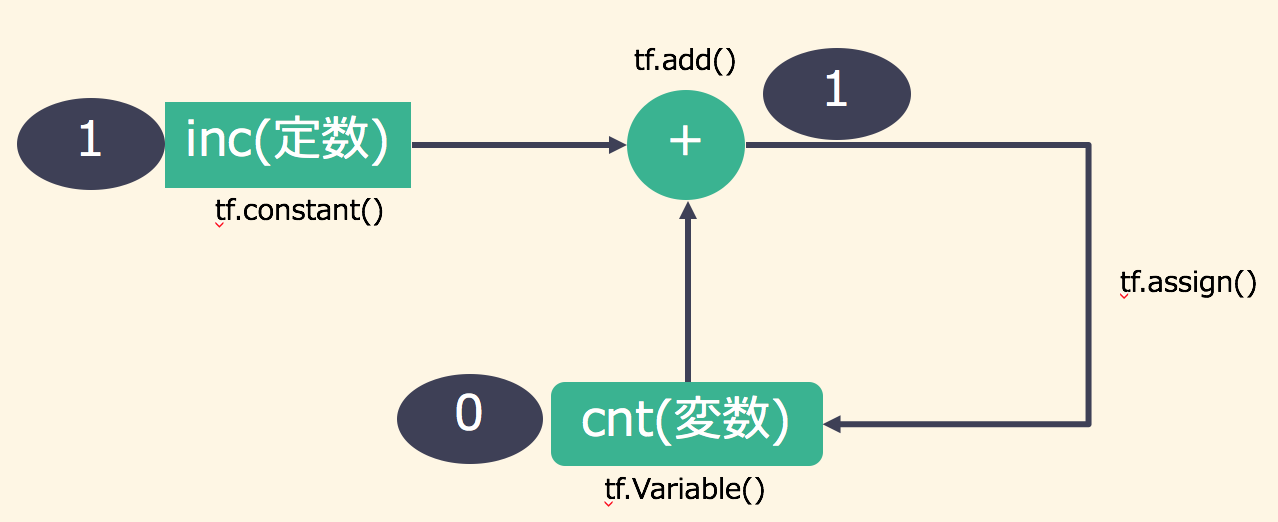
様々な入力を与える(プレースホルダ:Placeholder)
ここまでは計算に用いる値は全てプログラムの中にハードコードされている状態でした。しかし実際に機械学習の処理を行う場合、入力値は外部から様々な値を与える必要があります。TensorFlowには演算グラフに対して外部から値を与える方法としてプレースホルダという仕組みが提供されています。プレースホルダを使った仕組みとして、サンプルコード1を拡張して様々な値で足し算ができるようしたものがサンプルコード3となります。
import tensorflow as tf
x = tf.constant(1, name="x")
# プレースホルダーという箱を用意する
y = tf.placeholder(tf.int32, name="y")
add_op = tf.add(x, y)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(add_op, feed_dict={y:1}))
print(sess.run(add_op, feed_dict={y:3}))
ポイントはtf.placeholder()の部分です。tf.placeholder()ではtf.int32というデータの型のみ明示しているだけです。これによって次の足し算の演算であるadd_opはtf.placeholder()で定義されたtf.int32型の何らかの値とtf.constant()で定義された定数である1を足し合わせる、ということを定義したことになります。では、実際の値はいつ与えるのでしょうか。その答えが、sess.run()で足し算を実行する際にadd_opに追加する形で与えられているfeed_dictにあります。feed_dictによって演算グラフのプレースホルダ部分に値を与えることができます。つまり、サンプルコードではfeed_dictを通じてグラフに与える値を変えることで、1+1と1+3の足し算を実行していることになります。
サンプルコード3は以下のようなグラフになっています。
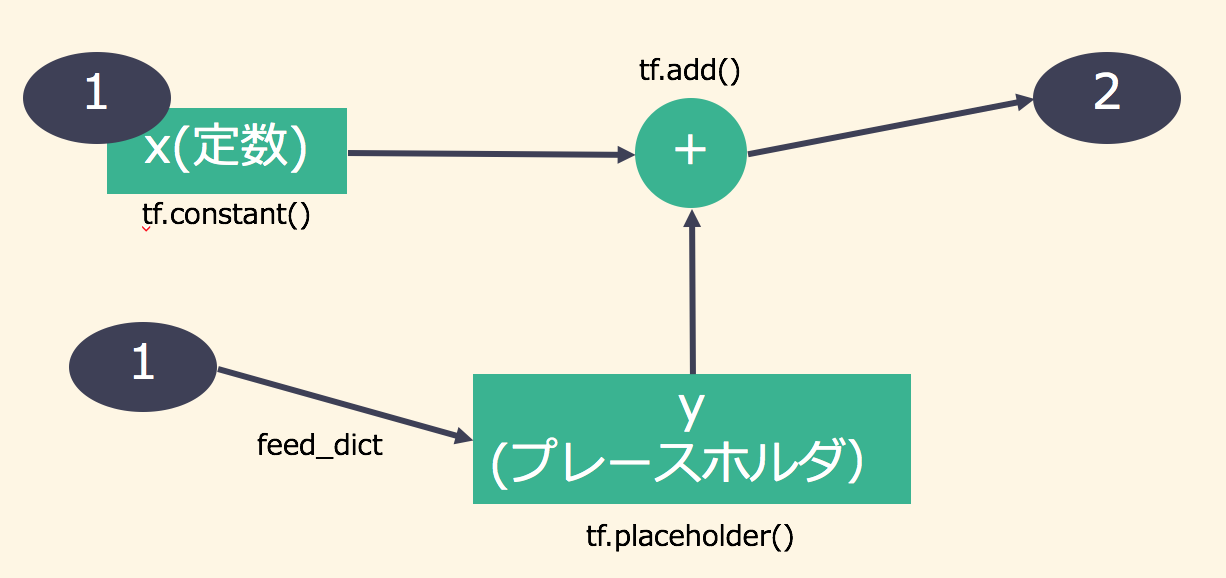
計算の実行単位を知る(セッション:Session)
続いてセッションの概念について説明します。セッションは計算グラフの実行単位のようなものです。これまでおまじないのように記述していたtf.Session()を使ってセッションを作ります。セッションはデバイスの割当てを行ったりと重要な機能も備えていますが、ここでは深入りせず、いわゆる名前空間のようなものだと考えていただければ良いと思います。それでは実際にコード例を見てみましょう。サンプルコード4はサンプルコード2のカウントアップするプログラムを拡張したものです。
import tensorflow as tf
cnt = tf.Variable(0, name="cnt")
inc = tf.constant(1, name="inc")
add_op = tf.add(cnt, inc)
up_op = tf.assign(cnt, add_op)
# 同じグラフで実行
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(up_op))
print(sess.run(up_op))
print(sess.run(up_op))
# 同じグラフでセッションを分けるとどうなるか
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(up_op))
print(sess.run(up_op))
print(sess.run(up_op))
サンプルコード4の実行結果は以下のようになります。
1 2 3 1 2 3
サンプルコード2のカウンターとの違いはセッションを2つ作り、それぞれでカウントアップを行っていることです。セッションが異なっていると、変数の情報が引き継がれていないことが分かります。サンプルコード4の演算グラフは以下のようになっています。
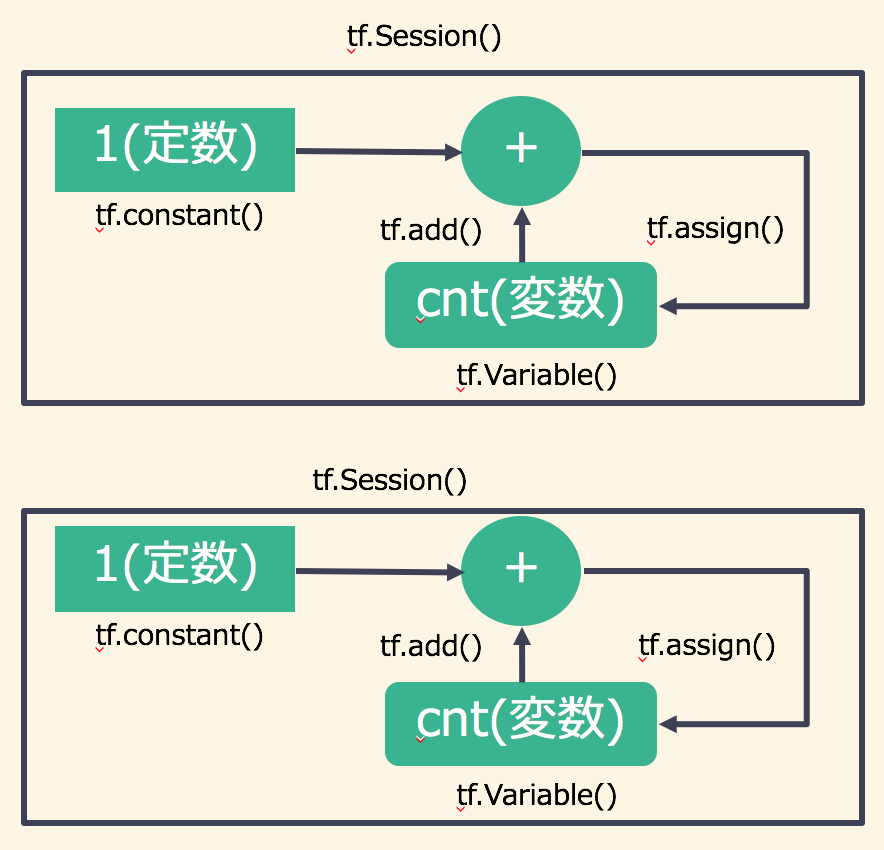
高ランクなテンソル計算
ここまでのサンプルコードは全て1や2などの整数で行ってきました。しかし実際の機械学習では、ベクトルや行列の計算が必要になってきます。TensorFlowの基礎の部分で、TensorFlowはテンソル(Tensor)の演算グラフを作って処理を行う、と書ました。テンソルとは多次元の配列のことで、ランク0のテンソルはスカラ(ただの数値)、ランク1のテンソルはベクトル、ランク2のテンソルは行列、イメージはし辛いですがランク3以降も多次元の配列として、同じようなデータ構造が定義されます。つまり、これまでのサンプルコードはランク0のテンソルの演算を行ってきたことになります。同じようにランク2のテンソルの演算、ランク3のテンソルの演算、とTensorFlowは、演算グラフにおいてテンソルを統一的に取り扱うことができます。それではランク2のテンソル(つまり行列)の演算の例を見てみましょう。
import tensorflow as tf
# ランク2のテンソル(行列)の定義
x = tf.constant([[1,2], [1,2]], tf.int32, name="x")
y = tf.constant([[3,4], [3,4]], tf.int32, name="y")
add_op = tf.add(x, y)
with tf.Session() as sess:
# 行列の足し算
print(sess.run(add_op))
このサンプルコードを実行すると次のような結果が得られます。
[[4 6] [4 6]]
サンプルコード5はサンプルコード1をランク2のテンソルを対象にするように改良しました。サンプルコード1との違いがtf.constant()に与えるテンソルだけであることが確認できると思います。また、足し算の結果も正しい行列の計算になっていることが確認できます。このように、対象とするテンソルのランクが変わっても、演算グラフ側に変更を加える必要なくテンソルの計算が行われます。サンプルコード5の演算グラフは次のようになっています。

いかがでしたでしょうか? 少しはTensorFlowの雰囲気はつかめたでしょうか? ここで紹介したことが基本となり、その上で機械学習のアルゴリズムを実装し実行する、これがTensorFlowです。よく聞く「TensorFlowは難しい」の原因はここまでの説明の通り覚えなければいけない「TensorFlowの流儀」が数多くあることに起因しているように思います。特にTensorFlowでディープラーニング/機械学習にトライしたいと思って気軽にTensorFlowを触り始めた方ほど、TensorFlowが難しいと感じてしまうようです。その点はTensorFlow開発チームも認識しているようで、TensorFlow Dev Summitでも高レベルなAPIの導入やTensorFlowをより使いやすくしたラッパーライブラリであるKerasとの統合などを積極的に推し進めている背景にもなっています。
TensorFlowの処理イメージが具体的になってきたところで、実際にTensorFlowを動かしてみたくなってきたかと思います。ここからは、TensorFlowの環境を構築していきましょう。
3. Windows上にTensorFlowの環境を構築してみよう
今回はWindows環境上にTensorFlowの環境を構築します。筆者が実際に構築した環境としては以下のようになっています。
・OS:Windows7 64bit
・Python:3.5
・TensorFlow:1.2
Pythonによる機械学習を実効する環境を構築する方法としてはいくつかありますが、最も簡単な方法としてminicondaを使います。minicondaは、Continuum Analytics社が提供しているPython本体とPythonの数値計算ライブラリが同梱されたPythonのディストリビューション「Anaconda」を再構成したものです。Python2系にも3系にも対応しているのと、インストーラで簡単にインストールできるため、特にWindowsユーザーの方にとってはPythonの環境を整えるためには良い選択肢の1つとなります。それでは実際にminicondaを使ってTensorFlowの環境を構築していきましょう。
minicondaのインストール
minicondaのインストーラはこちらのページから取得することができます。今回はWindowsのインストーラをダウンロードします。Pythonは3系での環境を構築するため、Python3.6と書かれている方のインストーラをダウンロードします(実際に使うのは3.5ですが)。インストーラを起動し、インストール場所などを適宜選択しつつインストールを行います。
minicondaを使ったTensorFlowのインストール
インストールが完了すると、Anaconda Promptというアプリケーションがプログラムメニューに追加されますので、それを起動して以下のコマンドを実行していきます。
minicondaではcondaコマンドを使ってパッケージの管理や仮想環境の構築を行います。Pythonのバージョンなどを切り替えるためにも仮想環境を作った上で各種ライブラリをインストールされることをお勧めします。TensorFlowはPython3.5に対応していますので、まずはPython3.5の仮想環境を構築しましょう。
# 仮想環境の構築 $ conda create -n tensorflow-test python=3.5 jupyter ←「$」より右部分を入力

続いて、作成した仮想環境をアクティベーションします。2回目以降に動作確認を行う場合は、以下を実行すれば、仮想環境が起動します。
# 作った仮想環境のアクティベーション $ activate tensorflow-test ←「$」より右部分を入力

これでPython3.5の環境ができました。続いてTensorFlowのインストールを行います。TenosrFlow本家のサイト通りにコマンドを実行すれば簡単にインストールが行えます。
$ pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.2.0-cp35-cp35m-win_amd64.whl

動作確認1:インタラクティブシェルでの確認
続いて、正しくTensorFlowがインストールされたかの動作確認を行いましょう。まずは、Anaconda Promptで「Python」と入力してPythonのプロンプトを立ち上げて、TensorFlowのインストールページにある確認用のプログラムを実行します。
$ python ←「$」より右部分を入力
# 以下はPythonのプロンプトが立ち上がった後
>>> import tensorflow as tf ←「>>>」より右部分を入力
>>> hello = tf.constant('Hello, TensorFlow!') ←「>>>」より右部分を入力
>>> sess = tf.Session() ←「>>>」より右部分を入力
>>> print(sess.run(hello)) ←「>>>」より右部分を入力
最後に"Hello, TensorFlow!"と表示されれば確認は完了です。「exit()」と入力してPythonのプロンプトを終了させておきましょう。
動作確認2:チュートリアルのコードの実行
続いて、TensorFlowのリポジトリからソースツリー一式をダウンロードしましょう。ソースツリーに含まれるexampleの中で、TensorFlowのチュートリアルに記載されている手書き文字の認識を行うプログラムを実行してみます。
これは0から9までの全部で10種類の手書き文字の認識する学習モデルを構築するというもので、手書き文字の認識は機械学習の領域でのHello Worldに相当する問題となります。もし今後読者の皆さんが機械学習について学ばれるのでしたら、他のライブラリのチュートリアルでも手書き文字の認識が題材として扱われているでしょう。今回はどのような学習モデルか、という点には踏み込まずプログラムの実行のみを取り扱います。現在のカレントディレクトリが、ダウンロードしたTensorFlowのソースツリーのトップ(「tensorflow-master.zip」を解凍してできる「tensorflow-master」→「tensorflow-master」)として、プログラムを実行して確認する手順を示します。
$ cd tensorflow/examples/tutorials/mnist ←「$」より右部分を入力 $ python mnist_softmax.py ←「$」より右部分を入力 Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes. Extracting /tmp/tensorflow/mnist/input_data/train-images-idx3-ubyte.gz Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes. Extracting /tmp/tensorflow/mnist/input_data/train-labels-idx1-ubyte.gz Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes. Extracting /tmp/tensorflow/mnist/input_data/t10k-images-idx3-ubyte.gz Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes. Extracting /tmp/tensorflow/mnist/input_data/t10k-labels-idx1-ubyte.gz 0.917
必要になるデータがダウンロードされ、無事にプログラムが完了すると最後に数値が出力されます。これは手書き文字を約91%の精度で認識するモデルが作られたことを表しています。ここまでで無事にTensorFlowを実行する環境を無事に整えられました。
Jupyter notebookの利用
さて、実際にTensorFlowのプログラムを書くにはどうすればよいでしょうか? もちろん好みのエディタでPythonのプログラムを書いて実行すれば良いですが、今回はJupyterを紹介します。Jupyterではノートブックと呼ばれる形式でプログラムを作成、実行していきます。コードブロックという単位ごとに実行を行ったり、Markdown形式でメモを書くことができたりと、試行錯誤的にプログラムを動かしていくには非常に使いやすい環境となっています。今回はすでに仮想環境を構築する際にJupyterをインストールしていますので、後は立ち上げるだけで簡単にJupyterを使うことができます。Jupyterは以下のようにコマンドを打つだけで簡単に利用できることができます。
$ jupyter notebook ←「$」より右部分を入力
コマンドを打つとブラウザが立ち上がります。以後はブラウザ上でノートブックを作成し、セルにプログラムを書いて実行する、これを繰り返していきます。具体的には、画面右上の「New」→「Python3」をクリックしてノートブックを作成し、セルにプログラムを書いたら「Cell」メニューから「Run Cells」をクリックして実行します。新しいセルを追加するには「Insert」メニューから「Insert Cell Bellow」を選びます。
例えば、動作確認1で実行したHello, TensorFlow!を表示するプログラムを書くと以下のようになります。
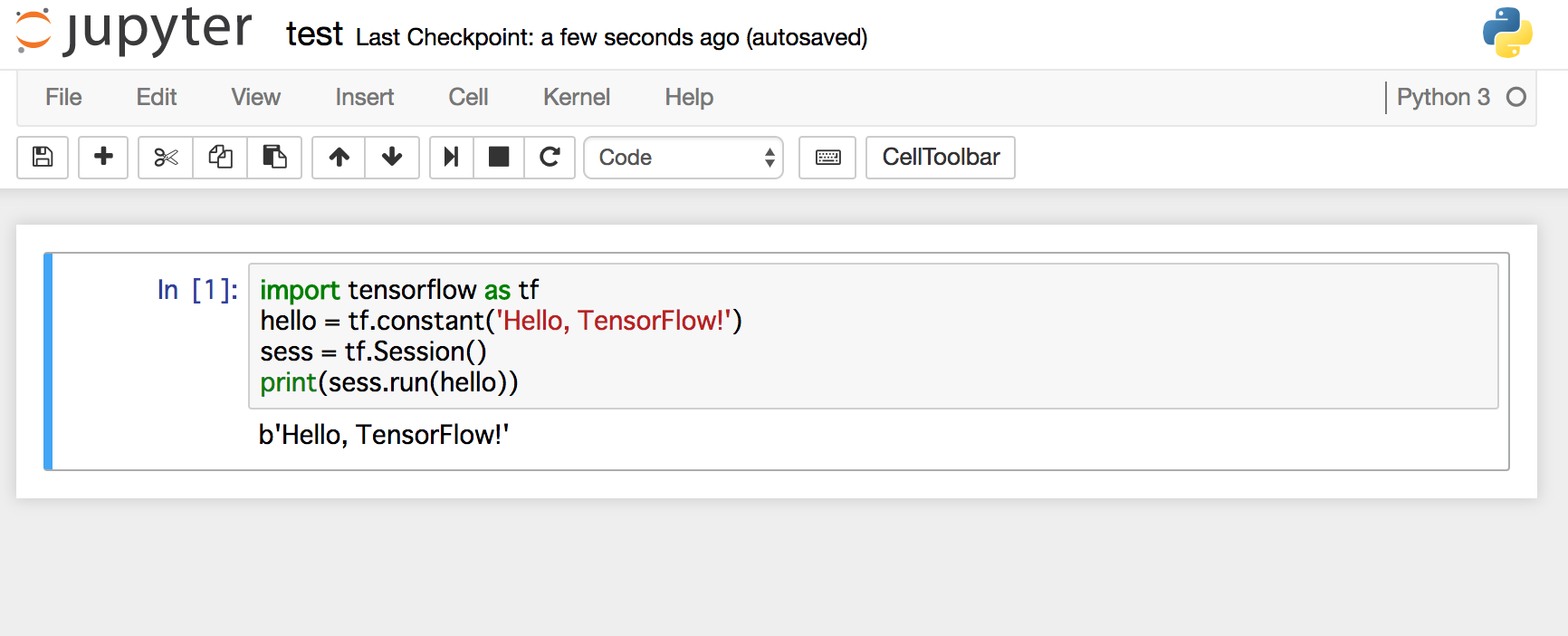
Jupyterの詳しい使い方は、豊富に用意されているJupyterのドキュメントを参照してみてください。また、日本でも多くのユーザーがいますので、インターネットで検索すると日本語でも多くの情報が発信されていることが分かるかと思います。
CPU版のTensorFlowの限界
mnist_softmax.pyに関してはCPU版のTensorFlowですぐに処理が終了しました。しかし、大規模なディープラーニングでも同じようにうまく処理が終わるのでしょうか? もちろんそんなことはありません。CPU版のTensorFlowの限界を知っていただくために、同じディレクトリに含まれているmnist_deep.pyを実行してみてください。
$ python mnist_deep.py ←「$」より右部分を入力 Extracting /tmp/tensorflow/mnist/input_data/train-images-idx3-ubyte.gz Extracting /tmp/tensorflow/mnist/input_data/train-labels-idx1-ubyte.gz Extracting /tmp/tensorflow/mnist/input_data/t10k-images-idx3-ubyte.gz Extracting /tmp/tensorflow/mnist/input_data/t10k-labels-idx1-ubyte.gz step 0, training accuracy 0.12 step 100, training accuracy 0.9 step 200, training accuracy 0.9 step 300, training accuracy 0.92 step 400, training accuracy 0.86 step 500, training accuracy 0.88 <以後step 100ごとの結果が出力される>
先程はプログラムを実行してすぐに結果が得られましたが、今度はなかなか処理が進まないことを実感いただけると思います。また、大半の方のPCのファンが大きな音を立て始めるかと思います。mnist_deep.pyはその名の通り、ディープラーニングによって手書き文字を認識するモデルを作るプログラムであり、CPU版のTensorFlowでは、プログラム中に含まれる行列の演算などに大きな負荷がかかってしまっているのが、処理が進まずファンが悲鳴をあげてしまう原因です。これがディープラーニングにはGPUが必要であると言われる理由なのです。それでは、最後にGPU版のTensorFlowをインストールして今回を締めくくりましょう。
4. GPU版TensorFlowのインストール
それではGPU版のTensorFlowをインストールしていきましょう。GPUをローカル環境でお持ちではない方が多数だと思いますので、今回はGCPのGCE(Google Compute Engine)のGPUインスタンス上にTensorFlowをインストールしてみます。GPU版のTensorFlowをインストールする手順は以下のようになります。
・GPUインスタンスの立ち上げ
・NVIDIAのドライバとCUDAのインストール
・cuDNNのインストール
・GPU版TensorFlowのインストール>
ここで使用しているCUDAやcuDNNについての詳しい説明はNVIDIAによるCUDAの説明ページとcuDNNの説明ページにてご確認ください。TensorFlowのv1.2では、CUDAはv8.0、cuDNNはv5.1を使用する必要があります。また、詳しくは後述しますが、GCPの無料トライアルアカウントのままではGPUを利用できないため、GPU版のTensorFlowも使えませんのでご注意ください。
GPUインスタンスの立ち上げ
残念ながら本記事を執筆しているタイミングでは、まだGCEの東京リージョン(asia-northeast1)でGPUインスタンスが利用可能にはなっていません。そこで、今回は日本から最も近いリージョンでGPUインスタンスが利用可能な台湾リージョン(asia-east1)でGPUインスタンスを立ち上げることにします。GPUを利用するには少々ステップを踏む必要があります。詳細についてはGCEのGPUに関するドキュメントをご確認いただきたいと思いますが、ここでは簡単にGPU利用までの流れを説明します。
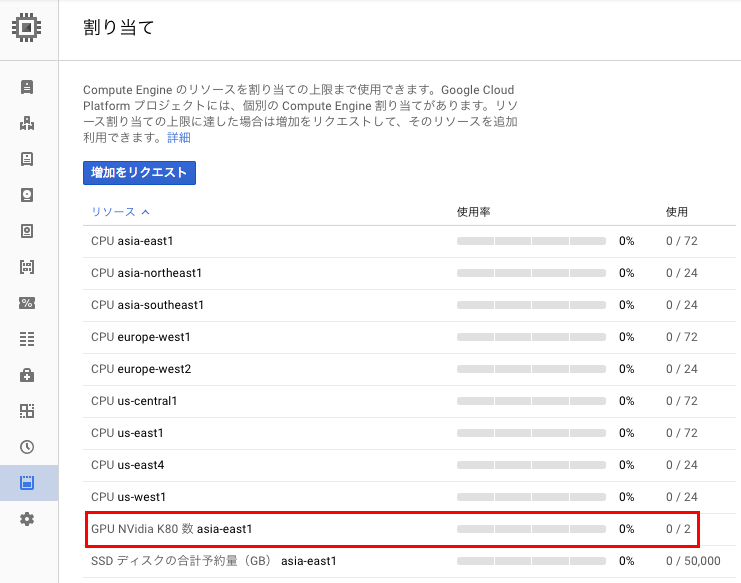
まずは、GPUのクォータ(GPUの利用権)を割り当ててもらう必要があります。クォータを確認するには、「Cloud Console」にアクセスし、左メニューから「Compute Engine」 > 「割り当て」と移動します。「割り当て」のページからGPUのクォータが確認できない状態ではGPUを利用することができません(2017年6月現在、無料トライアルアカウントではGPUの割り当てはありません)。
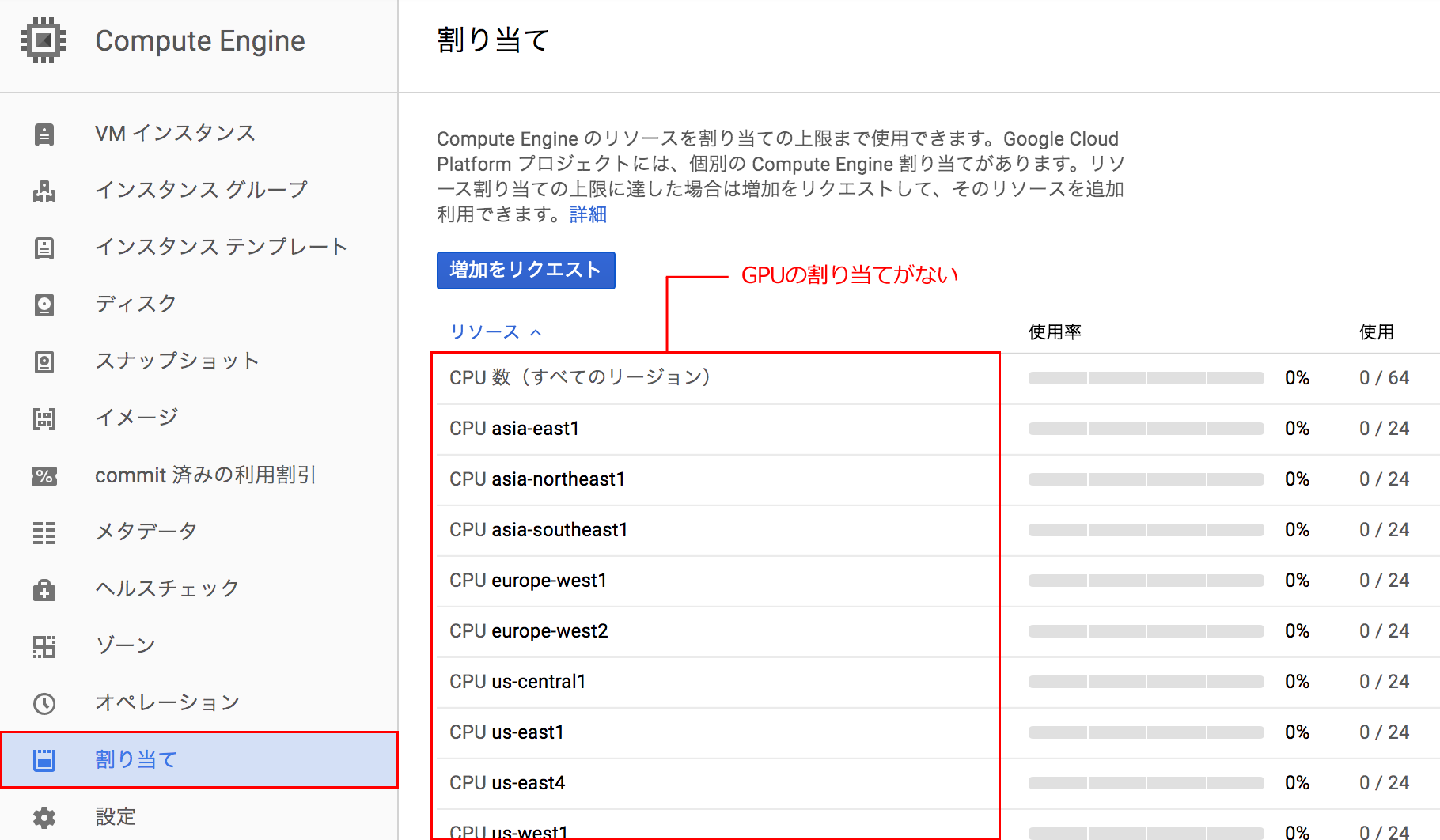
続いて、GPUのクォータの申請を行いましょう。「割り当て」のページ上部にある「増加をリクエスト」をクリックし、表示されたフォームにてアカウントに関する必要な情報を入力し、asia-east1に許可して欲しいGPUのクォータ数を入力して送信します。

すぐに入力したメールアドレスにサポートから返信があると思います。その返信をよく確認していただくと分かるのですが、GPUのクォータを割り当ててもらうには、すでに一定の課金を行っているプロジェクトである、もしくは別のプロジェクトを所有しており、そのプロジェクトで課金が行われていることが必要になります。作り立てで無料アカウントの範囲内で運用されている、もしくはごくごく少額の課金しか発生していないアカウントの場合、GPUのクォータ割り当てに許可がおりません。いずれにせよ、サポートからの返信内容をよく読んだ上で、クォータを得てください。クォータを割り当ててもらうと先程の「割り当て」ページに申請した分のクォータが確認することができます。
これでようやくGPUインスタンを立ち上げる準備ができました。「Compute Engine」 > 「VM インスタンス」とメニューを移動して、インスタンスを立ち上げましょう。今、GPUはasia-east1でのみクォータが割り当てられている状態です。asia-east1にはa、b、cの3つのゾーンがありますが、GPUインスタンスを立ち上げられるゾーンはasia-east1-aなので、ゾーンはasia-east1-aを選択します。

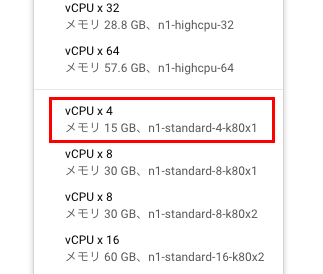
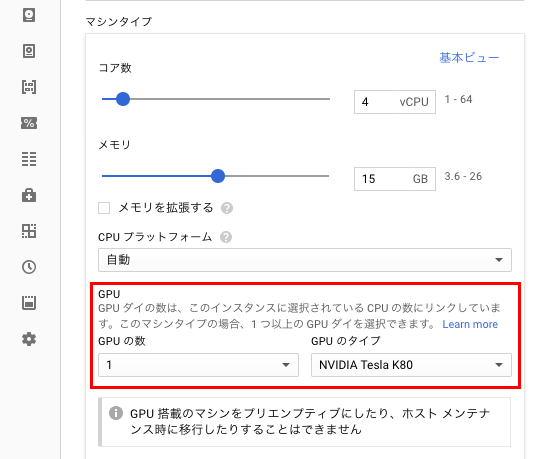
「マシンタイプ」のメニューにn1-standard-4-k80x1などのメニューが追加されていることが確認できるかと思いますので選択し、「マシンタイプ」の「カスタマイズ」をクリックして選択できるメニューからもGPUを1と選択しましょう。
続いて、ブートディスクのメニューからOSをUbuntu 16.04 LTSに変更します。ディスクはお好みで変更し、インスタンスを立ち上げます。
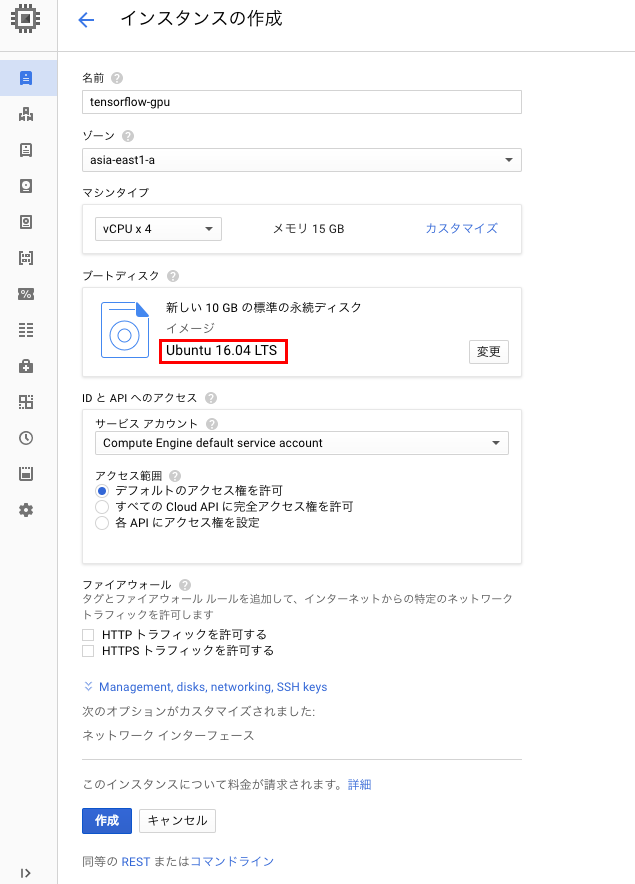
これでGPUを1つアタッチしたGPUインスタンスを立ち上げる準備が整いました。
GPUのドライバとCUDAのインストール
まずは立ち上げたGPUインスタンスにログインしましょう。その後、GCEのドキュメント通りにUbuntu 16.04 LTSのスクリプトをルート権限で実行します。
#!/bin/bash echo "Checking for CUDA and installing." # Check for CUDA and try to install. if ! dpkg-query -W cuda; then # The 16.04 installer works with 16.10. curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb dpkg -i ./cuda-repo-ubuntu1604_8.0.61-1_amd64.deb apt-get update apt-get install cuda -y fi
cuDNNのインストール
続いてcuDNNをインストールします。cuDNNについては、NVIDIAのディベロッパープログラムへの登録が必要となります。登録を行った上でこちらからcuDNN v5.1 Library for Linuxをダウンロードします。ダウンロードしたものを展開して所定の位置に展開し、依存関係を更新すればインストールは完了します。
$ sudo cp -a cuda/lib64/* /usr/local/cuda/lib64/ ←「$」より右部分を入力 $ sudo cp -a cuda/include/* /usr/local/cuda/include/ ←「$」より右部分を入力 $ sudo ldconfig ←「$」より右部分を入力
GPU版TensorFlowのインストール
GPU版のTensorFlowはnvidia-dockerを使うなどいくつかの方法がありますが、今回はCPU版と同じようにminicondaをインストールし、その環境下でTensorFlowをインストールしましょう。bashのインストールスクリプトが用意されていますので、ダウンロードして実行すると簡単にminicondaをインストールすることができます。CPU版と同じように仮想環境を作り、GPU版のTensorFlowをインストールしてみます。
$ conda create -n tensorflow-gpu-test ←「$」より右部分を入力 <中略> $ source activate tensorflow-gpu-test ←「$」より右部分を入力 (tensorflow-gpu-test) $ pip install tensorflow-gpu
動作確認1:インタラクティブシェルでの確認
この状態でCPU版と同じく'Hello Worldを'出力するプログラムを実行してみます。
(tensorflow-gpu-test) $ python ←「$」より右部分を入力
# 以下はPythonのプロンプトが立ち上がった後に入力
<<< import tensorflow as tf ←「<<<」より右部分を入力
<<< hello = tf.constant('Hello, TensorFlow!') ←「<<<」より右部分を入力
<<< sess = tf.Session() ←「<<<」より右部分を入力
2017-06-16 05:19:03.816338: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:893] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2017-06-16 05:19:03.817253: I tensorflow/core/common_runtime/gpu/gpu_device.cc:940] Found device 0 with properties:
name: Tesla K80
major: 3 minor: 7 memoryClockRate (GHz) 0.8235
pciBusID 0000:00:04.0
Total memory: 11.17GiB
Free memory: 11.11GiB
2017-06-16 05:19:03.817282: I tensorflow/core/common_runtime/gpu/gpu_device.cc:961] DMA: 0
2017-06-16 05:19:03.817297: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 0: Y
2017-06-16 05:19:03.817311: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Creating TensorFlow device (/gpu:0) -< (device: 0, name: Tesla K80, pci bus id: 0000:00:04.0)
<<< print(sess.run(hello)) ←「<<<」より右部分を入力
今回はtf.Session()を実行したタイミングで、CPU版にはなかったログが出力されます。よくよく読むと、GPUが見つかりました、というようなログであることが分かります。うまくGPU版のTensorFlowが動いているようです。
動作確認2:CPU版のTensorFlowでは時間がかかったサンプルプログラムの実行による確認
それでは最後にGPUのパワーを体験してみましょう。CPU版では一向に進まなかったmnist_deep.pyですが、処理がサクサクと進んでいくことが体感いただき、ものの数分で処理が完了します。
# はじめにgit cloneやzipダウンロードでTensorFlowのリポジトリを取得し、プロジェクトルートに移動する $ git clone https://github.com/tensorflow/tensorflow.git ←「$」より右部分を入力 $ cd tensorflow/tensorflow/examples/tutorials/mnist ←「$」より右部分を入力 $ python mnist_deep.py ←「$」より右部分を入力 2017-06-16 05:34:12.268437: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:893] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2017-06-16 05:34:12.269353: I tensorflow/core/common_runtime/gpu/gpu_device.cc:940] Found device 0 with properties: name: Tesla K80 major: 3 minor: 7 memoryClockRate (GHz) 0.8235 pciBusID 0000:00:04.0 Total memory: 11.17GiB Free memory: 11.11GiB 2017-06-16 05:34:12.269386: I tensorflow/core/common_runtime/gpu/gpu_device.cc:961] DMA: 0 2017-06-16 05:34:12.269393: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 0: Y 2017-06-16 05:34:12.269401: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Creating TensorFlow device (/gpu:0) -> (device: 0, name: Tesla K80, pci bus id: 0000:00:04.0) step 0, training accuracy 0.12 step 100, training accuracy 0.84 step 200, training accuracy 0.9 step 300, training accuracy 0.96 <中略> step 19700, training accuracy 0.98 step 19800, training accuracy 1 step 19900, training accuracy 1 test accuracy 0.9918
プログラムが動作している間にnvidia-smiコマンドを実行すると、GPUがどう使われているかが確認できます。
$ nvidia-smi ←「$」より右部分を入力 Fri Jun 16 05:34:38 2017 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 375.66 Driver Version: 375.66 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla K80 Off | 0000:00:04.0 Off | 0 | | N/A 55C P0 132W / 149W | 10942MiB / 11439MiB | 77% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | 0 5473 C python 10938MiB | +-----------------------------------------------------------------------------+
GPUは1枚確認でき、その番号として0番が割り当てられており、TensorFlowのログで出力されていた0番のデバイスを確認し、それを利用しているというメッセージとも一致する結果となっています。このように、GCEを使えば必要に応じて必要な枚数のGPUを持ったGPUマシンを簡単に作成することができます。ぜひ大規模な計算にもトライしてみてください。これまでの回と同じく、不要な課金を割けるため、利用しない時はインスタンスを停止する、もしくは削除することを忘れないでください。
5. この後の学び方
GCPとTensorFlowを使って複雑な機械学習を行うための環境は整いました。次にどうすればよいでしょうか? もちろん機械学習やディープラーニングについて書籍やWebサイトなどで学ぶのが良いと思いますが、TensorFlowに興味を持たれた方への次のアクションとして、筆者がオーガナイザーを務めるTensorFlow User Group (TFUG) への参加をお薦めさせてください。

TFUGは2016年10月に発足したユーザーグループで、月に一度程度のペースでTensorFlowを題材にしたミートアップや勉強会を開催しています。サービスやプロジェクトでTensorFlowを使った事例の話や、TensorFlowの機能の話など、TensorFlowの旬の情報を仕入れるための1つの有力な方法かと思います。イベント管理サービスであるConnpassにてTFUGのグループがあります。イベントの告知などはそちらで行いますので、ご興味を持っていただいた方はConnpass上のTFUGのメンバーになられると最新の情報をお届けできますので、ぜひ次の一歩として参加を検討してみてください。
Manateeではメルマガ会員を募集中!
