2017.09.21
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第11回 Cloud ML Engine上でTensorFlowを動かしてみよう
第8回では○×ゲームを題材にTensorFlowのサンプルコードを動かしてみました。せっかくなので引き続き同じ題材を用いて、Cloud Machine Learning Engine (Cloud ML Engine)を使ってみましょう。
1. Cloud ML Engineとは
Cloud ML EngineはGCP (Google Cloud Platform)のサービスのひとつで、TensorFlowの実行環境を提供してくれるというものです。大きく以下の2つの機能を持っています。
1. TensorFlowで書いた学習用コードを実行するためのリソースを提供する
2. TensorFlowの学習済みモデルをデプロイしてWeb APIを生成する
まず初めに、それぞれの機能についていったい何が便利なのかというところを簡単に説明しておきましょう。
学習アルゴリズム実行のためのマシンリソース
機械学習のアルゴリズムを回すためには大量のマシンリソースが必要である、という話は最近よく耳にするのではないでしょうか。もちろんアルゴリズムによりけりではあるので常にそうとは限りませんが、Deep Learningなどはネットワークの構造が大きく複雑になるほど計算が重くなり、相当なマシンリソースが必要になります。また、最近では計算の高速化のためにGPUを使うことが多く、本格的に学習をさせたい場合はそのための環境を構築しなければなりません。さらに高速化したい場合は分散学習をさせるためのクラスタを作る必要もあります。
Cloud ML Engineを使うと、これらの手間を飛ばして実行環境をすべて用意してもらうことができます。
学習済みモデルのデプロイ
学習済みのモデルをどうやって呼び出すかというのも難しい問題です。扱いやすい構成の例として、TensorFlowのモデルを呼び出す部分をWeb APIとして切り離してしまうという方法があります。
Cloud ML Engineを使うとTensorFlowの学習済みモデルから簡単にWeb APIを作成することが可能です。作成したWeb APIはCloud Vision APIなどのGCPで提供されている機械学習APIとほぼ同じように扱うことができます。もちろん大量のリクエストを送っても自動でスケールしてくれますし、新しいモデルを作成して切り替えるときのバージョン管理も簡単にできるようになっています。
2. Cloud ML Engine上で学習を実行してみよう
第8回と同様、ここからの作業はすべてCloud Shell上で行います。
また、本稿で使用するサンプルコードは以下のGitHubのリポジトリで公開されています。
https://github.com/sfujiwara/tictactoe-ml-engine
Cloud Storageのバケットの作成
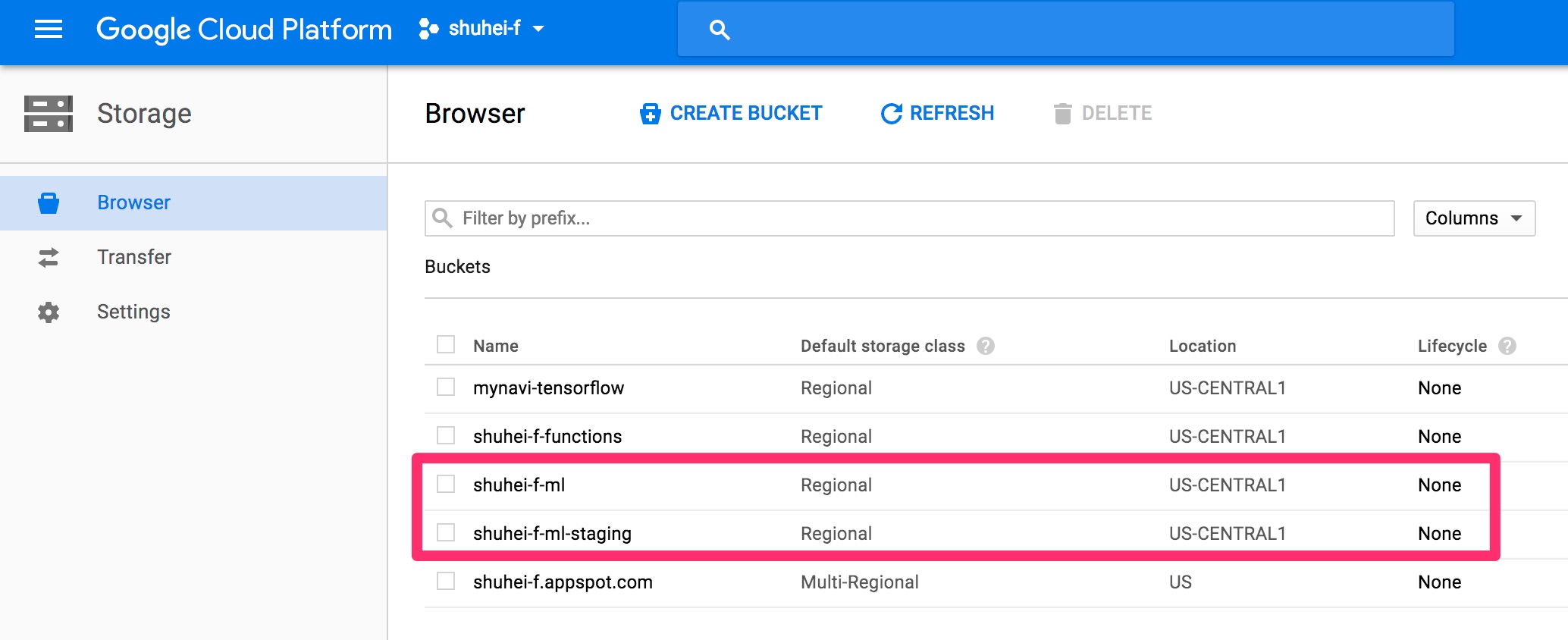
まずはCloud ML Engineで使用するCloud Storageのバケットを作成しましょう。今回は学習用データや学習済みのモデルを置くバケットと、TensorFlowのコードをアップロードするためのバケットを作成します。Cloud Shell上で次のコマンドを実行してください。
図1のように<PROJECT ID>-mlと<PROJECT ID>-ml-stagingの2つのバケットが作成されます。
サンプルコードの内容
まずは以下のコマンドを実行してサンプルコードをダウンロードしてください。
# サンプルコードのリポジトリをクローンcd tictactoe-ml-engine |
Cloud ML Engineに渡すTensorFlowのコードの最小構成は以下のようになります。

本稿で使用するサンプルコードも同様の構成です。
trainer以下はPythonの一般的なパッケージと同じ構成になっていれば自由に変えても問題ありません。これらのファイルがパッケージングされてCloud Storageにアップロードされ、Cloud ML Engine上で、pipでインストールされるという仕組みです。Cloud ML Engineの役割はあくまで実行環境を用意することなので、学習用のコードは自由に書くことができます。
config.yamlはCloud ML Engineに用意してもらいたいマシンの情報を記述する設定ファイルです。せっかくなので今回は以下のような設定ファイルでGPUインスタンスを使用しています。
1 2 | trainingInput: scaleTier: BASIC_GPU |
これだけでGPUを使って学習可能な環境が用意されるので、Compute Engineなどを使って環境構築を行うよりもずっと楽をすることができます。設定ファイルの詳細な書き方については公式のドキュメントに詳しく掲載されているので、そちらを確認してください。
また、TensorFlowはCPUを使う場合とGPUを使う場合でコードを変更しなくて済むような書き方ができるので、実は本稿で使用するサンプルコードは第8回のものとほとんど変わっていません。
Cloud ML Engineに学習のジョブを送る
それではいよいよCloud ML Engineにジョブを送ってみましょう。以下のコマンドを実行してみてください。
# Project IDの取得(念のため再度掲載)PROJECT_ID=`gcloud config list project --format "value(core.project)"`# 学習用データをCloud Storageにコピーgsutil cp data/tictactoe.csv gs://${PROJECT_ID}-ml/data/# Jobの名前をuniqueになるように生成JOB_NAME="tictactoe`date '+%Y%m%d%H%M%S'`"# 学習用のデータの場所CSV_FILE="gs://${PROJECT_ID}-ml/data/tictactoe.csv"gcloud ml-engine jobs submit training ${JOB_NAME} \ --package-path=trainer \ --module-name=trainer.task \ --staging-bucket="gs://${PROJECT_ID}-ml-staging" \ --region=us-central1 \ --config=config.yaml \ --runtime-version 1.2 \ -- \ --output_path="gs://${PROJECT_ID}-ml/tictactoe/${JOB_NAME}" \ --csv_file=${CSV_FILE} |
裏ではtrainer以下のコードがパッケージングされてCloud Storageにアップロードされ、Cloud ML Engineが用意したインスタンスはそのパッケージをインストールしてtask.pyを実行するという一連の作業が自動で行われます。
--output_pathと--csv_fileはtask.pyが実行されるときに渡されるコマンドライン引数です。今回は学習済みのモデルなどを保存する場所と、学習に使用するデータの場所を渡しています。task.pyでは以下のようにコマンドライン引数の値を受け取れるように記述しています。
10 11 12 13 14 15 16 17 | parser = argparse.ArgumentParser()# Required argumentsparser.add_argument("--output_path", type=str)parser.add_argument("--csv_file", type=str)args, unknown_args = parser.parse_known_args()CSV_FILE = args.csv_fileOUTPUT_PATH = args.output_path |
コマンドを実行したらCloud ML Engineのコンソールを表示してみましょう。図3のようにジョブのステータスが表示されるはずです。ジョブIDの左側のアイコンが図のように作成済みを示すチェックマークになるまで待ちましょう。
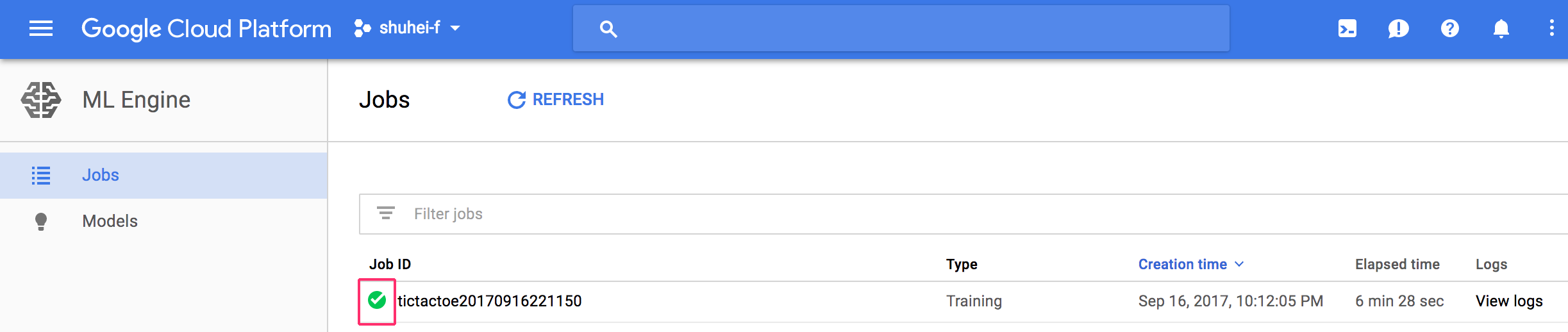
画面右側の「View logs」から図4のようにStack Driver Loggingからログを確認することができます。特に設定をしなくても学習中のログを一箇所に集約してくれる便利な機能です。これらのログをBigQueryに保存することも可能です。

3. 学習済みモデルをデプロイしてみよう
無事にジョブが終了したら以下のコマンドを実行すると、できあがった学習済みモデルからWeb APIを生成することができます。
# Modelを作成gcloud ml-engine models create tictactoe --regions us-central1# Modelの下にVersionを作成gcloud ml-engine versions create v1 \ --model tictactoe \ --origin gs://${PROJECT_ID}-ml/tictactoe/${JOB_NAME}/model |
図5のようにtictactoeというModelと、その下にv1というVersionが作成されているはずです。
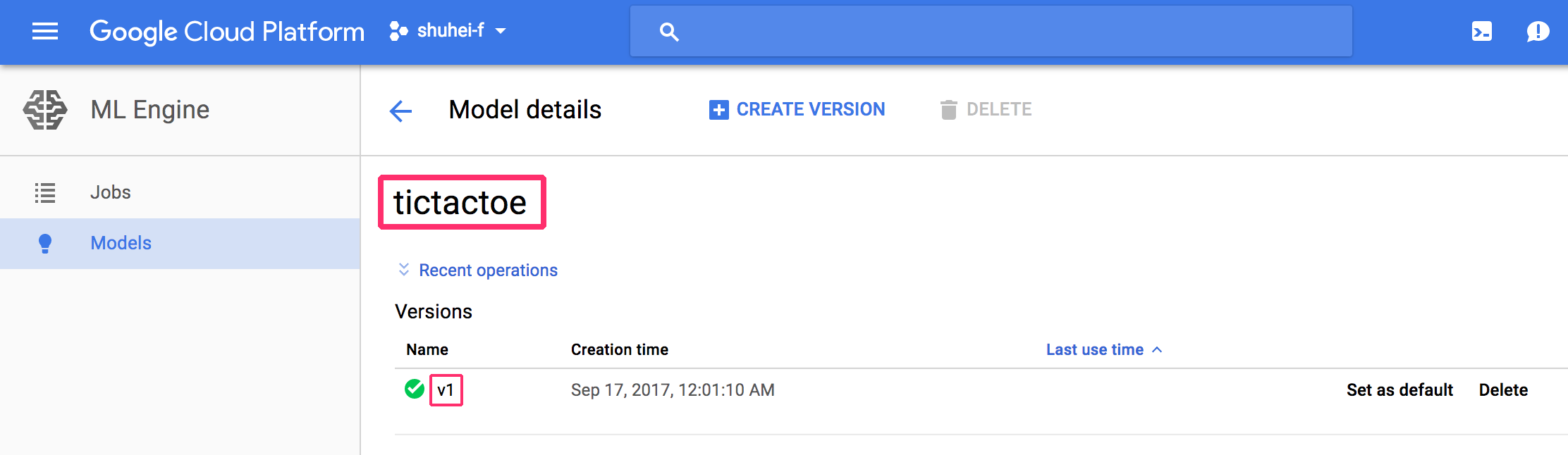
このVersionがTensorFlowの学習済みモデルに対応しているものです。ひとつのModelの下に複数のVersionを作成して、この管理画面から新しいVersionに切り替えたり古いVersionに戻したりという作業を簡単に行うことができます。
4. デプロイした学習済みモデルを使ってみよう
デプロイしたモデルの使い方はCloud Vision APIなど他のGCPの機械学習APIとほぼ同じです。
まずはPython 用 Google API クライアントライブラリをインストールしましょう。
sudo pip install --upgrade google-api-python-client |
クライアントライブラリを使ってモデルを呼び出すサンプルとしてprediction.pyを用意しておきましたので、実行してみましょう。
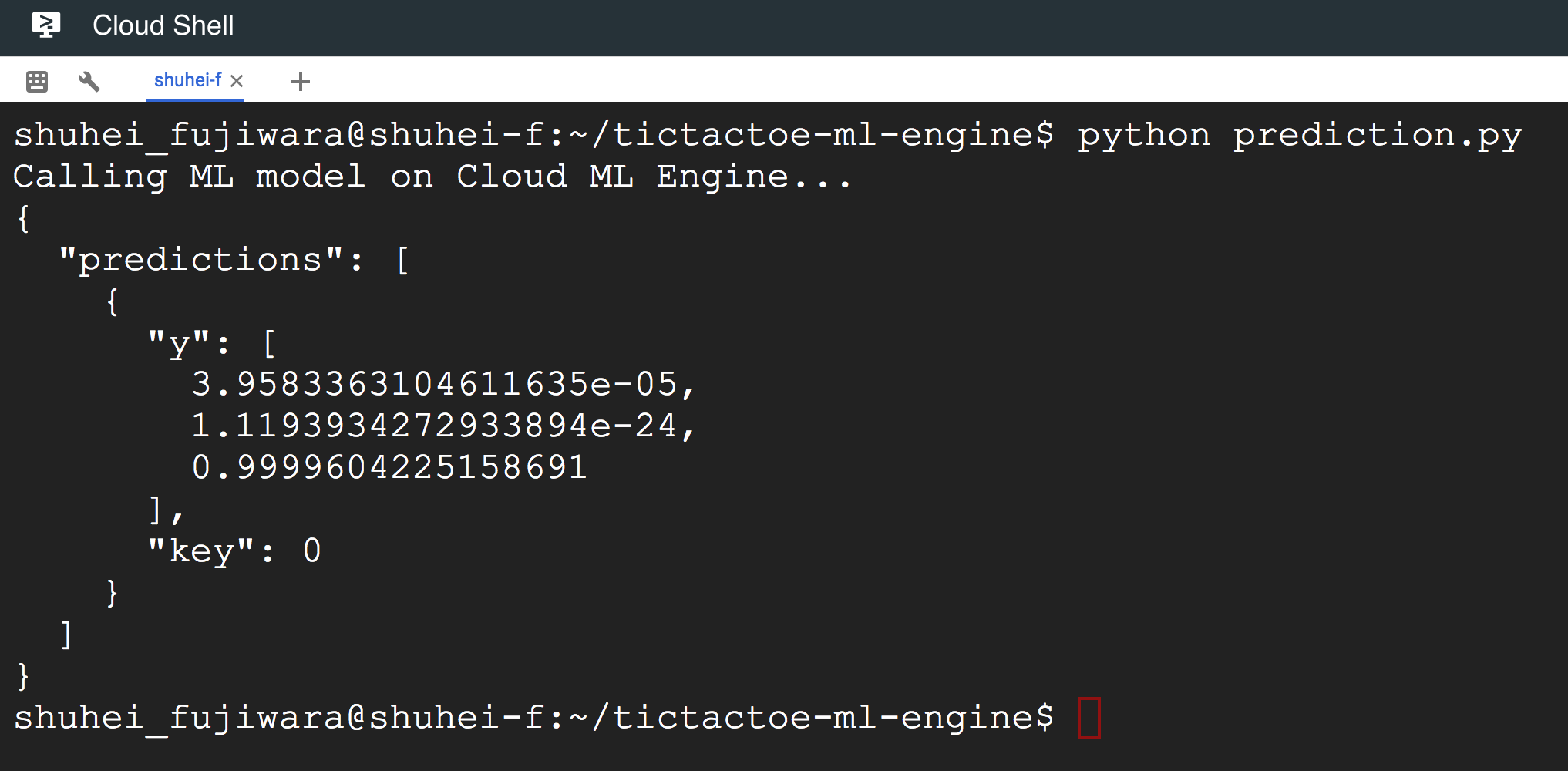
python prediction.py |
以下のように予測の結果が返ってきます。配列yの要素がそれぞれ勝確率・負ける確率・引き分けの確率に対応しています。
prediction.pyの内容について少し補足の解説をしておきましょう。prediction.pyの中で以下のようなデータを作成してCloud ML Engineにデプロイしたモデルに渡しています。
# モデルに渡すサンプルデータを作成data = { "instances": [ {"x": [0, 0, 0, 0, 0, 0, 0, 0, 0], "key": 0} ]}# サンプルデータをbodyに書き込んでリクエストを送信req = ml.projects().predict( body=data, name="projects/{0}/models/{1}".format(PROJECT_ID, MODEL_NAME))print(json.dumps(req.execute(), indent=2)) |
"instances"の各要素がデータ1個分に対応しています。この例では1つしか送っていませんが、同時に複数送信することも可能です。送られるデータは"x"と"key"を持っています。"x"は盤面の状態を表す長さ9の配列です(盤面の表し方については第8回の記事を参考にしてください)。"key"は、今回は任意の整数を渡せるようにしてあります。複数のデータに対してまとめて予測の処理を行う場合、返ってくる結果が渡したときと同じ順番になっていることが保証されていないので、後で対応関係を調べるために存在しているものです。
5. 次のステップ
今回は1つのGPUインスタンスを使って学習をさせましたが、TensorFlowを使うと複数インスタンスを使った分散学習を実装することも可能です。もちろんCloud ML Engineでも設定を変えれば簡単に分散学習用のクラスタを用意することができるので、興味がある方は挑戦してみてください。
また、Cloud ML Engineにはハイパーパラメータを自動でチューニングする機能など紹介しきれなかった便利な機能も存在しているので、ぜひ試してみてください。

