2017.07.03
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第8回 TensorFlow で○×ゲームの AI を作ってみよう
今回は○×ゲームという簡単な例をつかって、機械学習とゲーム AI がどうつながるのかの雰囲気を掴んで頂ければと思います。
1. はじめに
Google が買収した DeepMind 社によって開発された AlphaGo など、機械学習技術を用いたゲームの AI が話題になったことは皆さんの記憶に新しいのではないでしょうか。
ゲームの AI といわれると、いかにも人工知能という感じがしてワクワクするものですし、興味を持っているという方も多いかと思います。
一方で、具体的にどのような仕組みでゲームの AI が作られるのかということについてはなかなかイメージしにくいところがあります。
そこで、今回は○×ゲームという簡単な例で、機械学習とゲーム AI がどう繋がるのかという雰囲気を掴んで頂ければと思います。
本稿で使用するサンプルコードは以下の GitHub のリポジトリで公開されています。
https://github.com/sfujiwara/tictactoe-tensorflow
2. 機械学習で何を作るか
ついさきほど○×ゲームの AI を作ると言ったばかりですが、機械学習で扱える枠組みに落とし込むためにはもう少し目標を具体的に設定する必要があります。
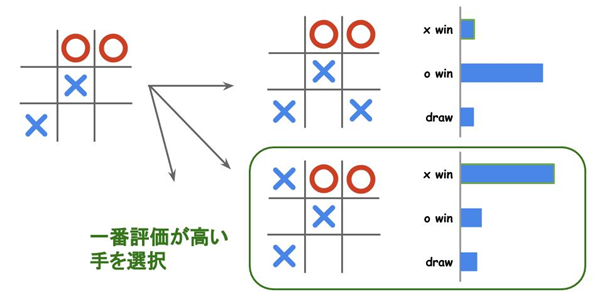
今回は「盤面の情報を入力したら、勝つ確率・負ける確率・引き分けになる確率、の 3つの数値を出力するモデル」を作成することにしましょう。

このようなモデルを作成すれば、次に打てる手を全て調べて最も自分が勝つ確率が高いものを選択することができます。また、○×ゲームの場合は相手が最善手を選ぶと勝てない状況が多いため、サンプルコードでは勝ちの目が薄い場合には引き分けを狙うようにしてあります。
3. どんなデータがあれば良いか
「盤面の情報を入力したら、勝つ確率・負ける確率・引き分けになる確率、の 3つの数値を出力するモデル」を作成するためには次のような盤面の情報と勝敗のデータが必要になります。
| top left |
top middle |
top right |
middle left |
middle middle |
middle right |
bottom left |
bottom middle |
bottom right |
result | |
|---|---|---|---|---|---|---|---|---|---|---|
| 盤面 1 | o | o | blank | x | o | x | x | blank | blank | o win |
| 盤面 2 | blank | o | blank | blank | x | blank | x | blank | blank | x win |
| ... | ... | |||||||||
| 盤面 m | blank | blank | blank | blank | blank | blank | blank | blank | blank | draw |
複雑なゲームの場合は人間が実際に打った棋譜などを膨大な量用意することになりますが、今回は○×ゲームという簡単なお題を使った練習なので、筆者が予め最善手を打った場合のデータを作成しておきました。
モデルの詳細
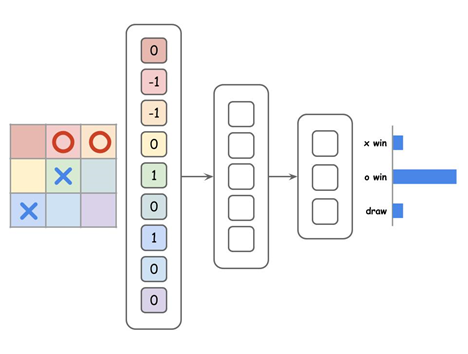
盤面のデータをニューラルネットに入力する際には、×は「-1」、○は「+1」、空いている場合は0として扱うことにします。○×ゲームの盤面は 9マスなので、ニューラルネットの最初の層のノード数は 9 個になります。
そして、全結合のネットワークを経て最終的には、×が勝つ確率・○が勝つ確率・引き分けの確率の3つの数値が出力されるというモデルです。
TensorFlow を使った実装
本稿で使用するサンプルコードのうち、TensorFlow で記述された学習用コード train.py の重要な部分について簡単に解説をしておきましょう。
TensorFlow にはニューラルネットワークを簡単に実装するための様々なモジュールが用意されています。好みによって使い分ければ良いのですが、本稿のサンプルコードでは tf.layers というニューラルネットワークをパーツごとに実装していくためのモジュールを使用しました。
盤面を入力として受け取って各確率を予測するネットワーク部分の処理は tf.layers.dense 関数を使って次のように書くことができます。今回はノード数 32 の隠れ層を 2 個持つニューラルネットを実装しました。
def inference(x_ph):
# ノード数が 32 の隠れ層を 1 層追加
hidden1 = tf.layers.dense(x_ph, 32, activation=tf.nn.relu)
# ノード数が 32 の隠れ層を 1 層追加
hidden2 = tf.layers.dense(hidden1, 32, activation=tf.nn.relu)
# ×が勝つ確率・○が勝つ確率・引き分けに対応するスコアを 3 つを出力
logits = tf.layers.dense(hidden2, 3)
return logits
tf.layers.dense 関数を 1 回呼ぶごとにニューラルネットワークの層が 1つ追加されるようなイメージで直感的にネットワークを記述することが可能です。
出力された予測値と実際の値を比較して誤差を小さくするように更新する処理まで含めると次のようなコードになります。
# 学習データを流し込むための placeholder を用意
x_ph = tf.placeholder(tf.float32, [None, 9])
y_ph = tf.placeholder(tf.float32, [None, 3])
logits = inference(x_ph)
y = tf.nn.softmax(logits)
# 予測値 y と実際の値 y_ph のずれを交差エントロピーで定義
cross_entropy = tf.losses.softmax_cross_entropy(
onehot_labels=y_ph,
logits=logits,
label_smoothing=1e-5
)
# 交差エントロピーを適当な optimizer に渡す
train_op = tf.train.AdamOptimizer(learning_rate=0.0002).minimize(cross_entropy)
予測値と実際の値のずれを cross_entropy で定義して、それを適当な optimizer に渡しています。機械学習では多くの場合、交差エントロピーなど何らかの意味で予測と実際の値の誤差にあたるものを小さくすることが目標となります。その際には最適化手法 (optimizer) と呼ばれるようなアルゴリズムを用いるのですが、TensorFlow にはあらかじめ様々な最適化手法が実装されています。
あとは placeholder に適当なデータを渡しながら train_op を繰り返し実行するだけです。
with tf.Session() as sess:
...
for i in range(20000):
# 学習データからランダムサンプリング
ind = np.random.choice(len(y_train), 1000)
# サンプリングしたデータを placeholder に渡しながら train_op を実行
sess.run(train_op, feed_dict={x_ph: x_train[ind], y_ph: y_train[ind]})
4. 動かしてみよう
実行環境の準備
TensorFlow がインストールされていればローカルの環境で動かすことも可能ですが、そうでない場合は Google Cloud PlatformのCloud Shell を使うと簡単に試すための環境を用意することができます。Cloud Shellを使うための詳しい操作は連載第0回をご覧ください。なお、Cloud Shellを起動するまえに、プロジェクトを作成しておく必要があります。
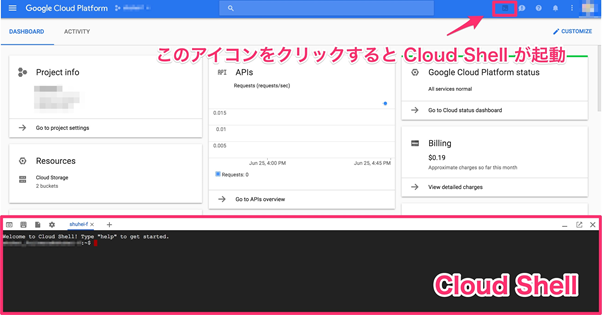
Cloud Shell が起動したら次のコマンドを実行して必要なソースコードをダウンロードしてください。
git clone https://github.com/sfujiwara/tictactoe-tensorflow cd tictactoe-tensorflow
学習を実行してみよう
次のコマンドを入力すると学習が始まります。
python train.py
学習の途中経過が表示され、徐々に精度が上がっていく様子が観察できるはずです。
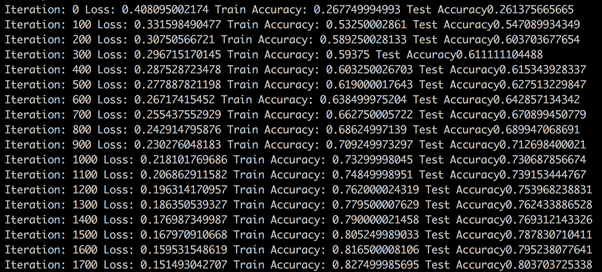
学習が終わると model というディレクトリが作成され、この中に学習済みのモデルが保存されます。
学習済みのモデルと対局してみよう
次のコマンドを実行すると、できあがった学習済みのモデルと対局することができます。
python play.py
まずAIが1手目を打ってスタートします。ユーザーは、2手目以降を0~8までの数字で入力していきます。0~8 の入力が 9 個の各マスに対応しています。
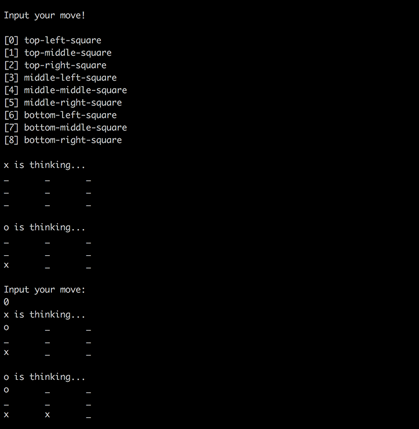
どのような AI ができあがっていましたか?
乱数の機嫌によって変わるかと思いますが、筆者が試したときは一手目を真ん中ではなく隅に置いてこちらのミスを誘ってくる少し意地悪な戦略を学習していました。
5. 次のステップ
手法やモデルの設計
今回は○×ゲームという簡単な例だったため、最善手の盤面と勝敗のデータをあらかじめ全て用意することができました。ですが、ゲームによっては予め学習用のデータを用意することが困難な場合も多いでしょう。そういった場合に有効なのが強化学習と呼ばれるタイプの手法です。強化学習では実際にゲームをプレイさせてデータを蓄積しながら並行して学習を進めていきます。最近では DeepMind 社が開発した Deep Q-Network という強化学習と Deep Learning を組み合わせた手法が話題になりました。
また、入力と出力の形式などの問題設定についても、本稿で紹介したものはほんの一例にすぎません。どのようなゲームではどのような問題設定で学習をさせれば上手くいくか、専門家の方々が日々研究をしているので、興味がある方はぜひ調べてみてください。
できあがったモデルのデプロイ
できあがったモデルを動かす方法は、play.py のように TensorFlow でモデル読み込み用のコードを書くだけではありません。Cloud ML Engine の prediction 機能では TensorFlow の学習済みモデルをデプロイすることができます。この機能を使うと TensorFlow で作った学習済みモデルから簡単にオートスケールする web API を作成することが可能です。実は今回作成した学習済みモデルは Cloud ML Engine にそのままデプロイ可能な形式で保存されているので、こちらも興味がある方は試してみてください。
Manateeではメルマガ会員を募集中!
