2017.03.06
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第0回 Google Cloud Platformをはじめよう! アカウント登録~画像認識APIを試してみよう
「機械学習に興味あるけれど、なかなか自分でアプリを作るところまでできない……」
本連載では、そんな方を対象に、気軽に機械学習を使ったアプリを作れるようなサンプルを紹介していきます。
興味があるけどなかなか着手できていなかった方、一度チャレンジしてみたけれど難しくて挫折してしまった方、またはすでに取り組んでいて、もっといろんなアプリを作ってみたい方は、ぜひ本連載で紹介するアプリを一緒に作ってみてください。
さて、機械学習を使ったアプリといっても、どんな形で機械学習を取り入れるかには、いくつかの方法があります。
簡単な方法としては、機械学習のAPIサービスを利用するというやり方があります。有名なところでは、GoogleやMicrosoft、Amazon、IBMといった会社が提供しています。
すでに学習済みの機械学習モデルが用意されており、APIを通じて「画像から文字を読み取る」「画像にタグをつける」「文章の翻訳をする」といった機能を利用することができます。機械学習の仕組みを理解しなくても、手軽に利用できるという点が一番のメリットです。
また、一歩進んだ方法としては、機械学習のライブラリ(フレームワーク)を使って、独自の機械学習モデルを構築するという方法があります。有名なライブラリとしては、TensorFlow(テンソルフロー)やscikit-learn(サイキット・ラーン)、Chainer(チェイナー)、Caffe(カフェ)などがあります。
これらのライブラリを使うと、上記のAPIでは用意されていないような機能を作ることができるようになります。ただし、大量のデータを学習させたり、具体的な機能の実装などはユーザーが行うことになりますので、それなりに知識や手間が必要になります。
本連載では、前半ではAPIサービスを、後半ではライブラリを使って、機械学習を使ったアプリのサンプルを紹介していきます。APIサービスとしてはGoogleのGoogle Cloud Platformで提供されているAPIサービスを使い、ライブラリとしては、オープンソースとして提供されているTensorFlowを使います。
アプリを作る手順をしっかり説明していきますので、読者のみなさんもぜひ一緒に作ってみてくださいね。
まず以下の第0回では、Google Cloud Platformの画像認識APIを使う方法を紹介していきます。
(以上編集部より)
1.はじめてのGoogle Cloud Platform
Google Cloud Platformとは
Google Cloud Platform(以下、GCP)は、Google社が提供するパブリッククラウドサービスです。Googleは、検索エンジン/Gmail/YouTubeなどのサービスを自社が保有する世界各地のデータセンターとそれらを相互接続するグローバルなネットワーク回線を用いて提供しています。このGoogleのサービスを支える基盤を一般利用者にも使えるようにサービス化したものが、Google Cloud Platformです。
GCPの主なサービス
GCPで機械学習を始める前に、GCPが提供する主なサービスを見ておきましょう。サービスは、コンピュートやストレージ、ビックデータ、機械学習などいくつかのカテゴリーに分かれています。GCPのサービスを使って機械学習を行うときは、APIや、TensorFlowのマネージドサービスである Cloud MLだけでなく、ビッグデータを扱うサービスをはじめ、仮想マシンのCompute Engineや画像などのファイルを格納できるCloud Storageなどを必要に応じて組み合わせると効率よく進められるでしょう。
| カテゴリー | サービス | 説明 |
|---|---|---|
| コンピュート | Compute Engine(GCE) | 仮想マシンサービス |
| Container Engine(GKE) | コンテナオーケストレーション | |
| App Engine(GAE) | アプリケーションプラットフォーム | |
| ストレージ/データベース | Cloud Storage | オブジェクトストレージ |
| Cloud SQL | MySQLのマネージドサービス | |
| Cloud Bigtable | NoSQLデータベース | |
| ネットワーキング | Cloud Virtual Network | 仮想ネットワーク |
| Cloud Load Balancing | ロードバランサー | |
| ビッグデータ | BigQuery | データウェアハウス |
| Cloud Dataflow | データ処理サービス | |
| Cloud Dataproc | Spark/Hadoopのマネージドサービス | |
| Cloud Pub/Sub | メッセージングサービス | |
| 機械学習 | Cloud Vision API | 画像分析サービス |
| Cloud Speech API | 音声のテキスト変換サービス | |
| Cloud Translate API | テキスト翻訳サービス | |
| Cloud Natural Language API/Sub | 自然言語分析サービス | |
| Cloud ML | TensorFlowを用いた機械学習サービス |
このほかにも、運用監視サービスやアカウント管理サービスなどが提供されています。最新情報については公式のサイトを確認して下さい。
GCPのデータセンター
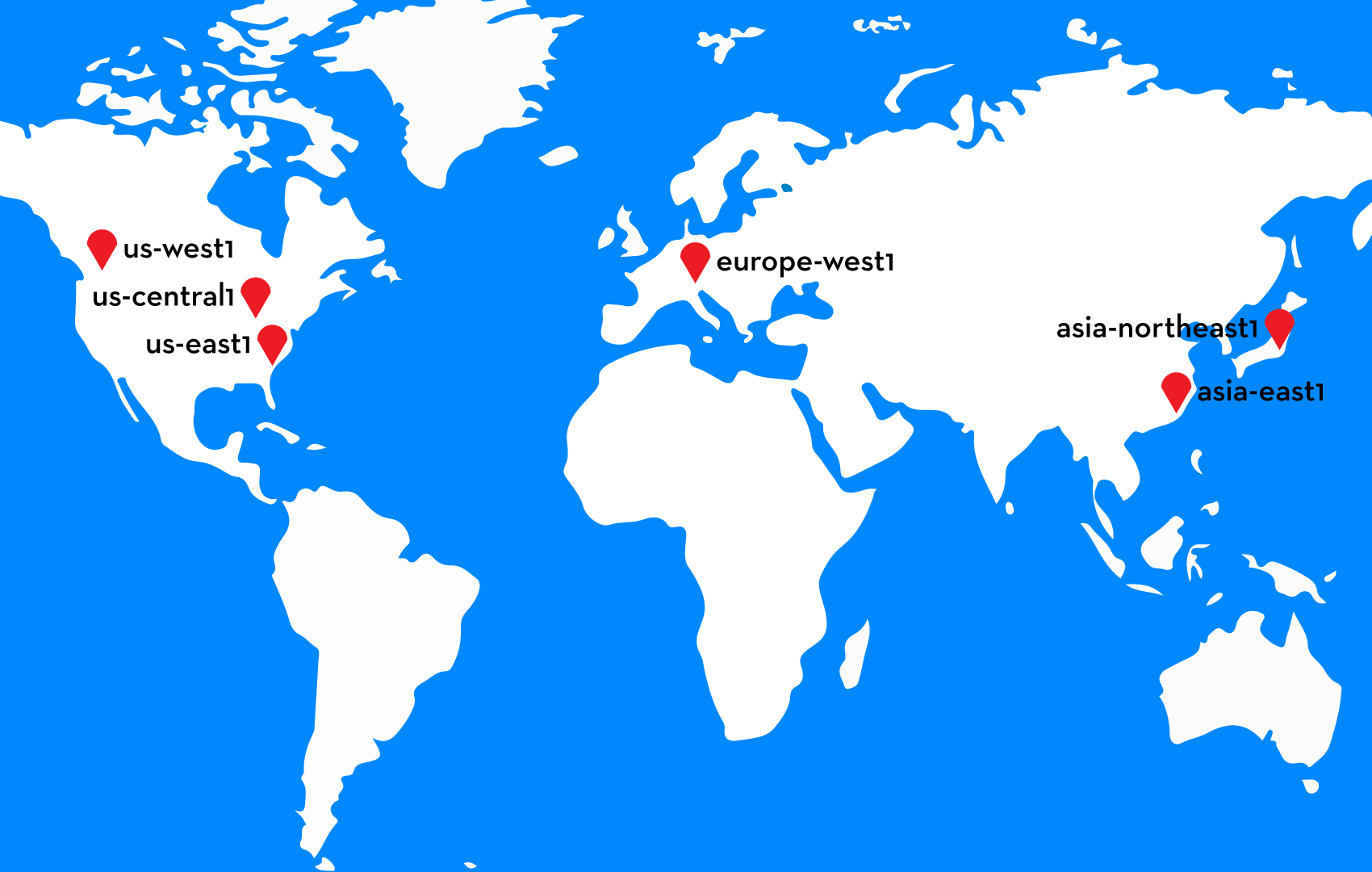
GCPでは、データセンターが存在する地域を「リージョン」と呼んでいます。2017年2月末時点では、全世界で6ヶ所のリージョンが利用可能で、それぞれのリージョンには、2~4個の「ゾーン」が用意されています。各ゾーンには名前がついており、たとえば東京リージョンのゾーンaは「asia-northeast1-a」という名前です。
2. アカウントを登録しよう
GCPを利用するときは、はじめにアカウントの登録が必要です。以下では、その手順を説明します。
[1] 準備
はじめてGCPにアカウントを登録すると、無料試用のためのクレジットが利用できます。無料試用に登録すると、GCPの全サービスに利用可能な300ドルのクレジットがアカウントに追加されます。すべてのクレジットを使い切るか、登録から12か月が経過した時点で無料試用は終了します。GCPのアカウント登録に必要なものは次の2つです。
・Google アカウント
Google アカウントは、GmailやGoogle+などのGoogleが提供するサービスで使用するアカウントです。
・クレジット カードまたは銀行口座
カード情報は、身元の確認とロボットによる登録でないことを確認する目的で使用されます。クレジットカードが無い場合は、銀行口座でも登録できます。
[2] アカウント登録
Google Cloud Platformにアクセスし、[無料トライアルを開始]のボタンをクリックします。ログインを求められますので、既存のGoogleアカウントでログインしてください。
「無料体験版」を選択するとアカウント情報の登録画面が表示されます。そこで、以下の項目を登録します。
・国と通貨
・口座の種類(ビジネス/個人)
・名前と住所
・お支払い方法(クレジットカード/デビットカード)
・使用言語
登録が完了すると図4の画面が表示されます。これで、GCPのサービスを利用できます。
なお、無料試用が終了すると、アカウントは一時的に停止されます。そのまま有料アカウントにアップグレードするには、GCPのコンソール画面上部の[アップグレード]ボタンをクリックして、手動でアップグレードしてください。
3. プロジェクトを作成しよう
GCPを使ってシステムを開発するときは、はじめにプロジェクトを作成します。GCPでは、プロジェクト単位で開発を行い、このプロジェクト内で仮想マシンやストレージなどのリソースを管理します。使用したリソースの利用料金は、あらかじめ設定した課金アカウントに対して請求されます。
1人のユーザーが複数のプロジェクトを作成することも可能です。また、使用中のプロジェクトをシャットダウンすると、その中で利用していたリソースはすべて削除され、一切の課金が行われなくなります。そのため、テスト用のプロジェクトを作成して、テストが終われば、プロジェクトごとシャットダウンするなどの使い方も可能です。このようにすれば、リソースを停止/削除し忘れて、無駄な課金が発生する心配もありません。
[1] プロジェクトの作成
それでは、プロジェクトを作成してみましょう。以下のURLにブラウザからアクセスします。
https://console.cloud.google.com/projectselector/home/dashboard
[ホーム]-[ダッシュボード]を選択し、[プロジェクトを作成]ボタンをクリックします。
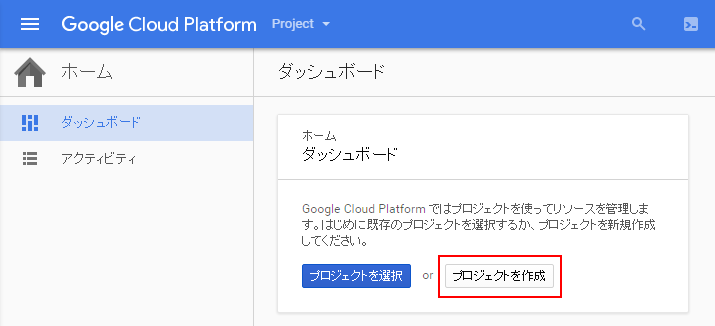
[2] プロジェクト名の設定
[プロジェクト名]に任意の名前を設定します。[作成]ボタンをクリックすると、プロジェクトが生成できます。
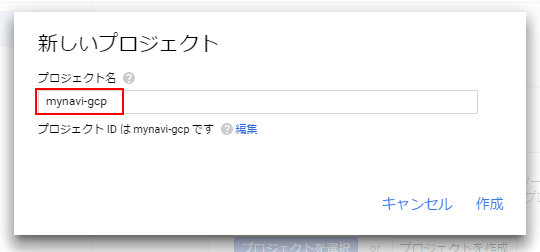
GCPでのプロジェクトは、プロジェクトIDと呼ばれるUUID(Universally Unique Identifier)で識別されます。この識別子は、小文字の文字/数字/ダッシュ/プロジェクト番号で構成された文字列です。プロジェクト名をもとに自動生成されますが、既存のプロジェクトとの重複がなければ任意の値を設定することも可能です。このプロジェクトIDはアプリケーションやAPIリクエストの識別子として利用します。一度プロジェクトを作成した後は、プロジェクト名とプロジェクトIDは変更できません。
4. GCPの開発ツールを使ってみよう
プロジェクトが作成できたら、実際にGCPを操作してみましょう。まず、以下のURLにブラウザからアクセスして「Cloud Console」を起動します。
https://console.cloud.google.com/
[1] Cloud Consoleの使い方
Cloud Consoleの左上のメニューをクリックすると、サービスが表示されます。これらのメニューは、GCPで提供されているサービスの管理画面にリンクされています。例えば、[コンピュート]-[Compute Engine]を選択すると、GCEの管理画面が表示されます。
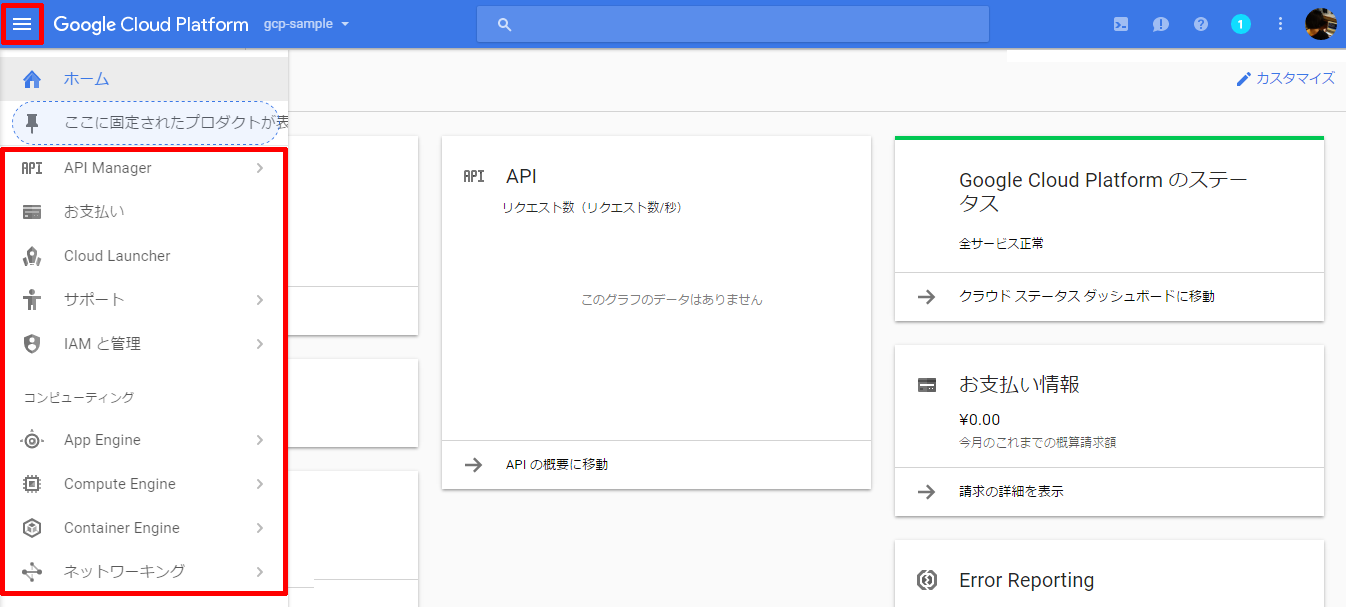
[2] ダッシュボード
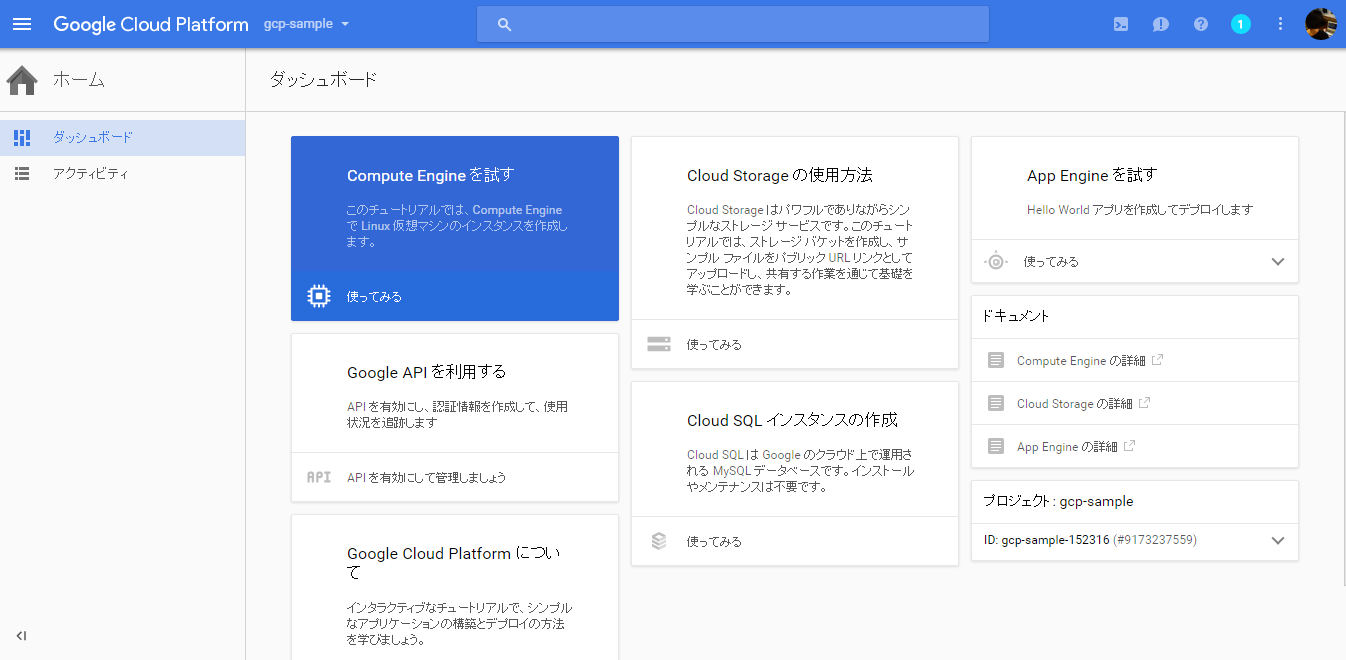
GCPのプロジェクト全体の状況を確認するときは、[ホーム]-[ダッシュボード]をクリックします。各サービスの稼働状況、APIへのリクエスト数、サービスを利用するためのドキュメントやチュートリアル、プロジェクト名/プロジェクトIDの確認や、利用料の概算が確認できます。
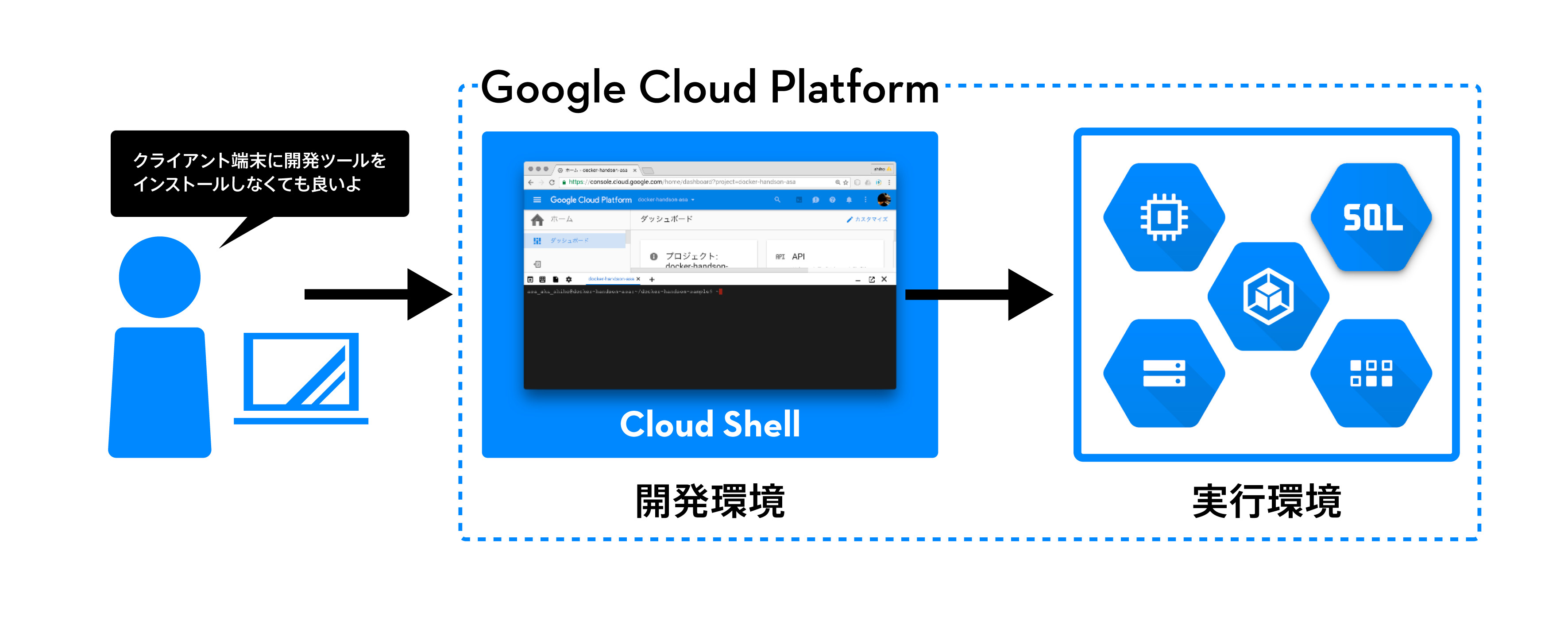
[3] Cloud Shellの使い方
サービスの操作やアプリケーションのデプロイなどの作業を行うときは、「Cloud Shell」と呼ばれるブラウザ上で動作する管理用コンソールを利用できます。Cloud Consoleの右上のアイコンをクリックするとブラウザ上でコマンド入力が可能なコンソールが立ち上がります。
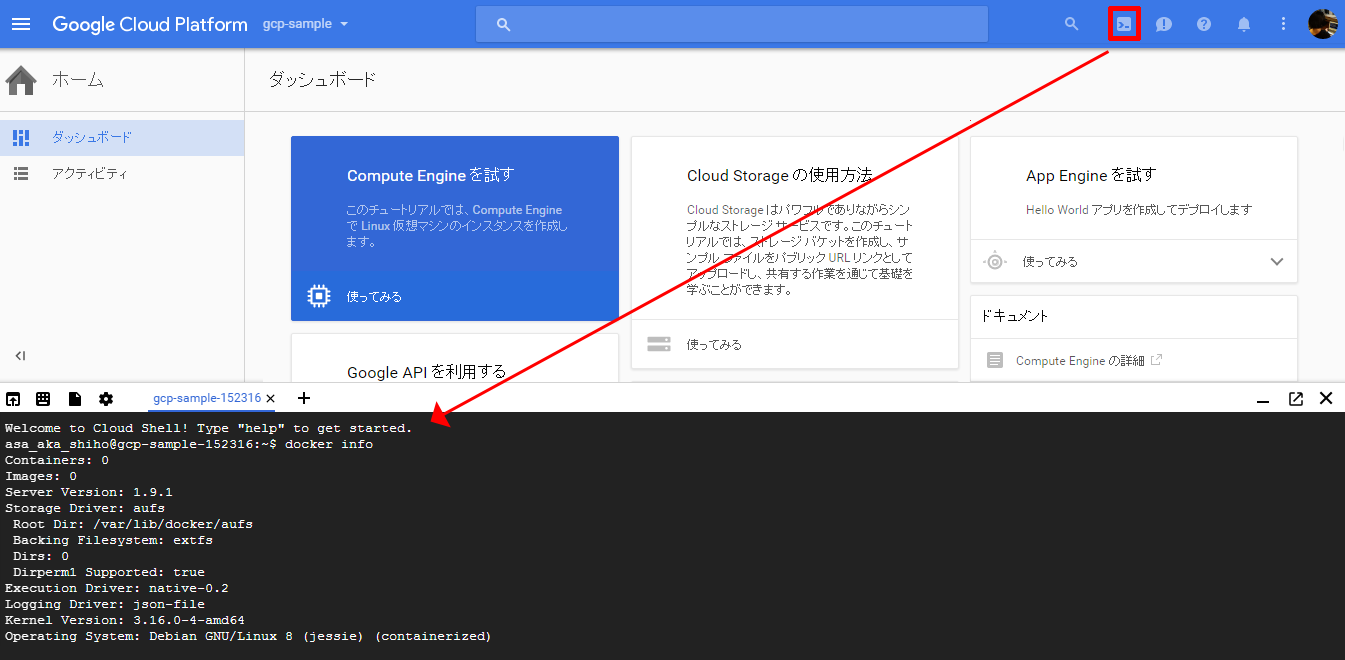
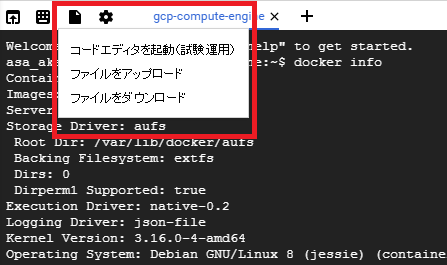
Cloud Shellには、ファイルのアップロードやダウンロードの機能があります。また、コードエディタも提供されているため、ブラウザ上でそのままファイルの編集ができます。
Cloud Shellには、開発に必要なツールがあらかじめインストールされています。たとえば、Google App EngineのSDKやGoogle Cloud SDKをはじめ、テキストエディタであるEmacsやVim、ビルドツールであるGradleやMaven、バージョン管理のためのGit、コンテナを操作するためのDockcerなどです。
なお、Cloud Shellは起動したときに選択していたプロジェクトを操作できます。操作対象のプロジェクトを確認したいときは、次の1行目の「gcloud」以降のコマンドをそのまま実行してください。以下は、プロジェクトIDが「gcp-ml」であるプロジェクトでコマンドを実行した例です。
$ gcloud config list project --format "value(core.project)" Your active configuration is: [cloudshell-xxxxxxxx] gcp-ml ←設定されているプロジェクトID
5. Vision APIで画像認識してみよう
それでは、いよいよ機械学習APIを使ってみましょう。Google Cloud Vision API(以降、Vision API)とは、機械学習モデルによって画像を認識するための REST APIです。Vision API は、リクエストで送信した画像やCloud Storageの画像の中に含まれる情報を検出できます。Vision APIで検出できる情報を、表2にまとめます。
| 項目 | 説明 |
|---|---|
| ラベル検出 | 乗り物や動物など、画像に写っているさまざまなカテゴリーの物体を検出 |
| 有害コンテンツ検出 | アダルト コンテンツや暴力的コンテンツなどの有害コンテンツを検出 |
| ロゴ検出 | 画像に含まれる一般的な商品ロゴを検出 |
| ランドマーク検出 | 画像に含まれる一般的な自然のランドマークや人工建造物を検出 |
| 光学式文字認識(OCR) | 画像内のテキストを検出/ 抽出。言語の種類も自動判別 |
| 顔検出 | 画像に含まれる複数の人物の顔を検出。感情の状態や主要な顔の属性について識別 |
| 画像特性 | ドミナント カラー(支配色)などの画像特性を検出 |
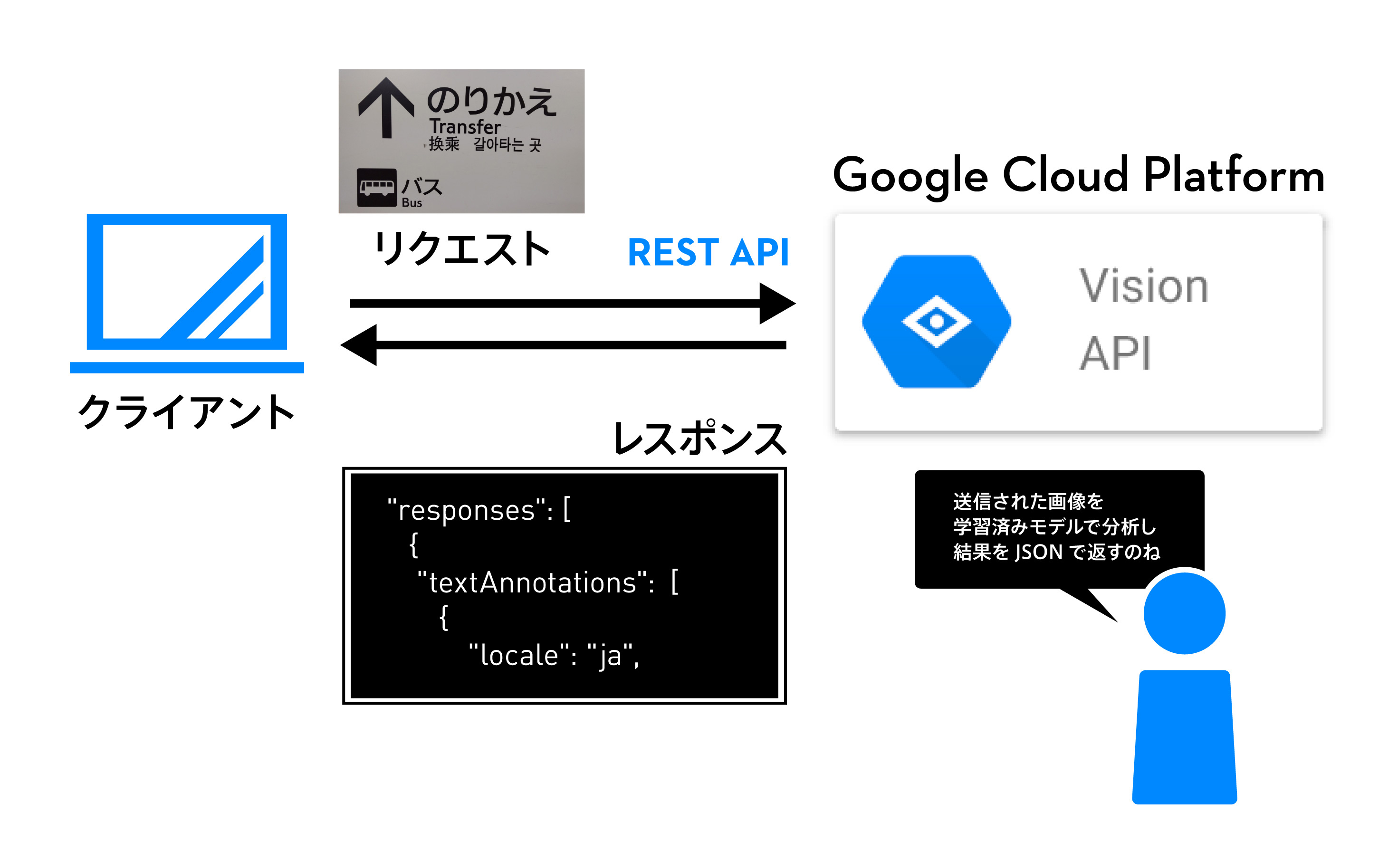
Vision APIは、クライアントから送信された画像に対し、学習済みデータを使って分析した結果をJSON形式にして返却するAPIです。Googleが膨大なデータを使って学習したモデルをもとに分析しますので、高い精度で画像の情報の抽出ができるのが大きな特徴です。
ここでは、Vision APIの動作確認のため、光学式文字認識(OCR)機能を使って画像の中に含まれる文字を検出する例を説明します。
[1] APIの有効化
プロジェクトでVision APIを利用するには、APIを有効化する必要があります。Cloud Consoleの[メニュー]-[API Manager]を選択します。
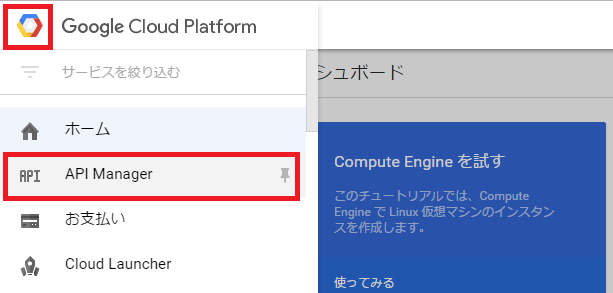
次に、API Managerの[ライブラリ]から「Google Cloud Vision API」を選択します。
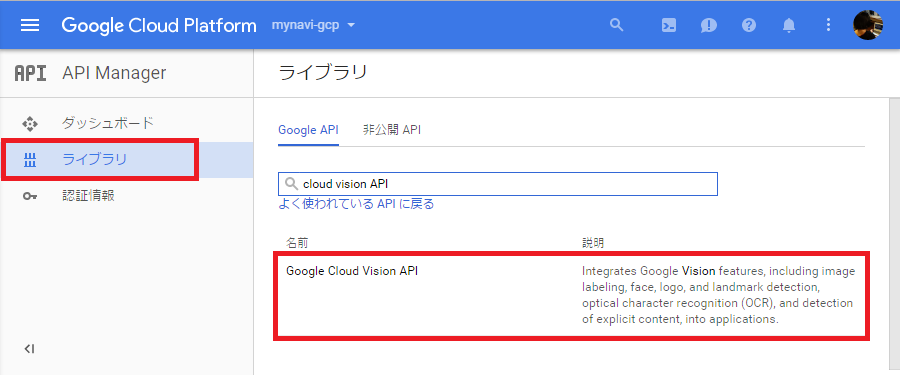
Vision APIの説明のページが表示されますので、[有効にする]ボタンをクリックします。これでこのプロジェクトで、Vision APIが利用可能になりました。

[2] APIキーの発行
アプリケーションからVision APIを使うときは認証が必須です。認証の方法は、次の3つがあります。
・API キー
・サービス アカウント
・OAuth 2.0 クライアントID
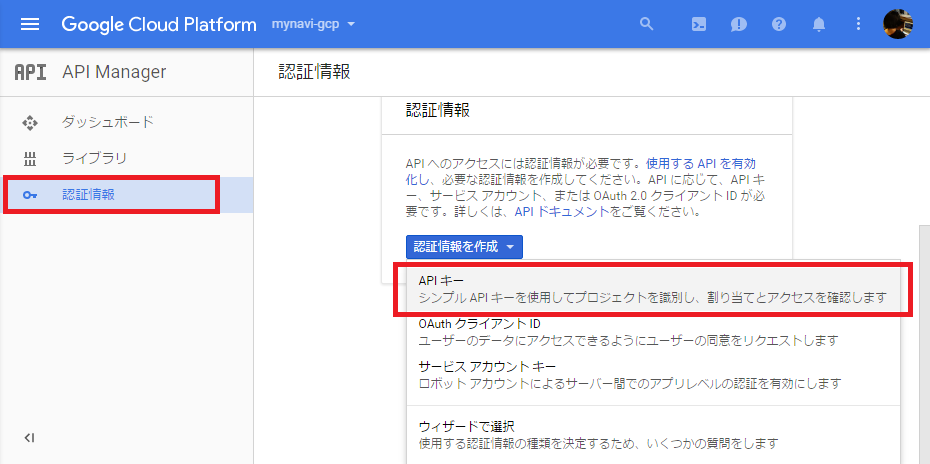
ここでは一番手軽なAPIキーによる認証を説明します。API Managerの[認証情報]を選択し、[認証情報を作成]をクリックします。そこで、「APIキー」を選択します。
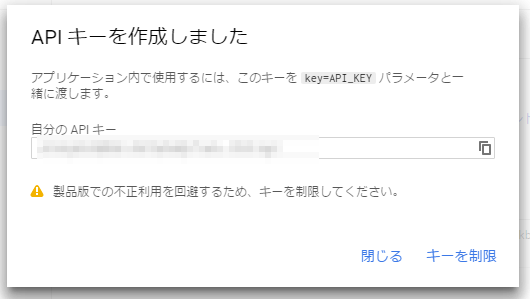
APIキーが生成されますので、これを安全な場所で管理します。このキーが不正に利用されてしまうと予期せぬ課金が発生してしまう恐れがありますので、くれぐれもGithubのリポジトリなどに誤ってアップロードしないよう注意してください。
[3]動作確認
それでは、発行したAPIキーを使って動作確認をします。サンプルコードの取得は、以下のサイトで[Clone or download]を選択し、[Download ZIP]をクリックしてください。
https://github.com/asashiho/mynavi-ml-visionapi
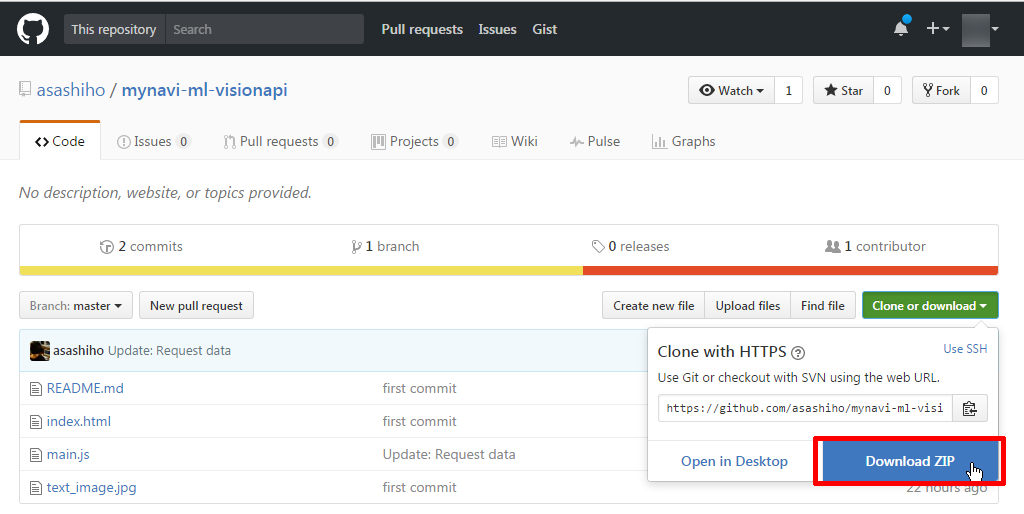
ダウンロードしたZIP形式のサンプルを任意の場所に展開します。展開したディレクトリの中に含まれるmain.jsをエディタで開き、取得したAPIキーを設定します。
// このAPI_KEYにAPIキーを設定してください // 例えば、APIキーが「abcdefg12345」の場合次のように指定します var API_KEY = 'abcdefg12345';
このmain.jsのコードでポイントとなるのはVision APIの呼び出しを行うsendFileToCloudVision関数です(以下のコードの【1】)。まず、変数requestにVision APIに送信するJSONを設定します。このJSONでは、requestsオブジェクトに画像認識の対象となる画像の情報としてimage/features/imageContextを指定します。これらの詳細は次の通りです。
| プロパティ | JSONでの指定方法 | 説明 |
|---|---|---|
| image | image:{...} | base64エンコードした画像のデータ |
| features | features:[...] | 画像認識に使用する機能。OCR機能の場合は、typeで「TEXT_DETECTION」を指定する。また、結果の最大件数を指定するときは、maxResultsに件数を数値で指定する |
| imageContext | imageContext:{...} | 画像分析の条件を指定。OCR機能の場合はlanguageHintsで言語を指定できる。指定を省略した場合、自動で言語が判定される |
そして、変数GOOGLE_URLで定義した、Vision APIのエンドポイントURLにリクエストを送信することで【2】、Vision APIからのレスポンスを得ることができます。このときのエンドポイントURLの後ろにkey=として、Vision APIにアクセスするためのAPIキーを設定します【3】。
var API_KEY = 'abcdefg12345'; var GOOGLE_URL = 'https://vision.googleapis.com/v1/images:annotate?key=' + API_KEY; ←【3】 ・・・
// VisionAPIの呼び出し
function sendFileToCloudVision (event) { ←【1】
var content = event.target.result;
// リクエストの作成
var request = {
requests: [{
image: {
content: content.replace('data:image/jpeg;base64,', '')
},
features: [{
type: 'TEXT_DETECTION',
maxResults: 200
}],
imageContext:{
languageHints:["ja","en","zh","ko"]
}
}]
};
// POST処理
$.post({ ←【2】
url: GOOGLE_URL,
data: JSON.stringify(request),
contentType: 'application/json'
}).fail(function (jqXHR, textStatus, errormsg) {
$('#results').text('error: ' + textStatus + ' ' + errormsg);
}).done(displayJSON);
}
次に、ダウンロードしたディレクトリにあるindex.htmlをWebブラウザで開きます。ここでは、サンプルに含まれる次の画像を使って、OCR機能を試します。

[ファイルを選択]ボタンをクリックしてこの画像を選択し、[送信]ボタンをクリックします。画像を解析した結果は、Vision APIからJSON形式で返却されます。OCR機能の場合は、requestsオブジェクトのtextAnnotationsに結果が格納されます。また、リクエストに失敗した場合は、errorにエラーの内容が格納されます。今回のサンプルの例では、descriptionに「のりかえ」や「Transfer」など文字認識されたデータが格納され、それぞれの文字列を検出した位置情報がboundingPolyに格納されているのが分かると思います。
{
"responses": [
{
"textAnnotations": [
{
"locale": "ja",
"description": "のりかえ\nTransfer\n换乘갈아타는 곳\nバス\nBus\n",
"boundingPoly": {
"vertices": [
{
"x": 380,
"y": 107
},
…
6. プロジェクトの削除
最後に、プロジェクト削除手順を説明します。Cloud Consoleのメニューから[IAMと管理]を選択します。
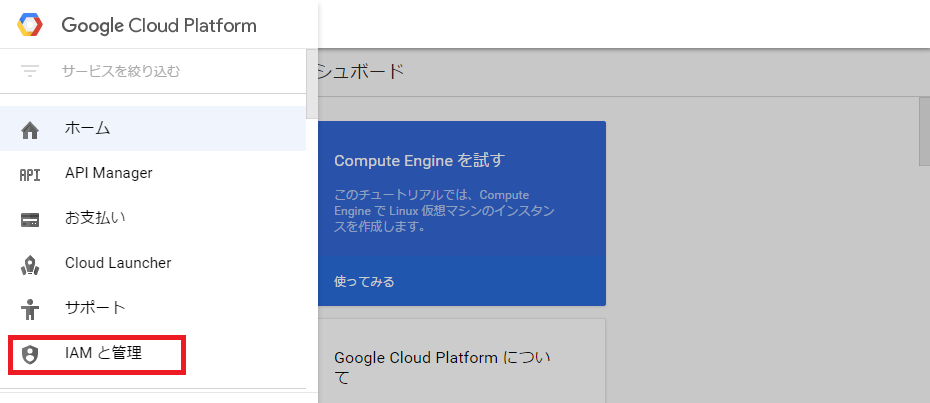
[IAMと管理]から[設定]を選択し、[削除]をクリックします。プロジェクトの削除を確認するダイアログが表示されますので、[シャットダウン]をクリックします。
シャットダウンすると、プロジェクト全体にアクセスできなくなり、すべての課金とトラフィック処理が停止します。なお、プロジェクト全体は 7 日後に削除されるため、誤ってシャットダウンしてしまった場合、7日以内であれば元に戻すことができます。
7. おわりに
今回は、Google Cloud Platformを利用して機械学習にチャレンジするにあたり、必要となるGoogle Cloud Platformの概要と基本的な使い方、そして画像認識APIであるCloud Vision APIを使った動作確認をご紹介しました。敷居の高く感じられる機械学習も、クラウドサービスを使えば、容易に既存のアプリケーションに組み込めることがお分かりいただけたかと思います。次回の連載からは、具体的にざまざまなアプリケーションを作りながら、機械学習で実現できることを見ていきたいと思います。
【編集部注】この記事は、執筆時の2017年3月現在の情報に基づくものです。記事公開後、サービス内容や画面などに変更が発生する可能性がありますのでご注意ください。
Manateeではメルマガ会員を募集中!

