2017.06.06
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第6回 複数の機械学習とロボットアームの組み合わせで広がるアイデアを体感しよう
連載第6回では、複数のAPIを組み合わせたデモの例として、筆者の所属するチームで開発した"FindYourCandy"というデモをご紹介します。FindYourCandyは、複数の機械学習とロボットアームを組み合わせたデモです。このデモは、ロボットアーム等のハードウェアを使うことで、オンラインの世界を飛び出し、実世界で機械学習を利用することをイメージしやすいことを目指して開発されました。機械学習部分にはGoogle Cloud Platformの機械学習系サービスを積極的に利用することで、高い精度と開発工数の削減の双方を実現しています。まずはFindYourCandyそのものの説明を行い、どのように機械学習を使ってFindYourCandyの各機能を実現しているか説明します。また、FindYourCandyはGitHub上で公開していますので、最後にそのセットアップ方法について解説します。
FindYourCandyの説明やソースコード(GitHub)
https://github.com/BrainPad/FindYourCandy
1. FindYourCandyの全体像
まずはFindYourCandyが実際に展示された様子や動いている様子をお見せします。

FindYourCandyは、各種機械学習の処理とロボットアームを組み合わせたデモンストレーションです。ユーザーが発話した内容をもとに、ロボットアームが机の上に置かれたお菓子からお勧めのものを1つ選び、ピックアップしてユーザーのもとへ届けます。システムの全体像を図2に示します。
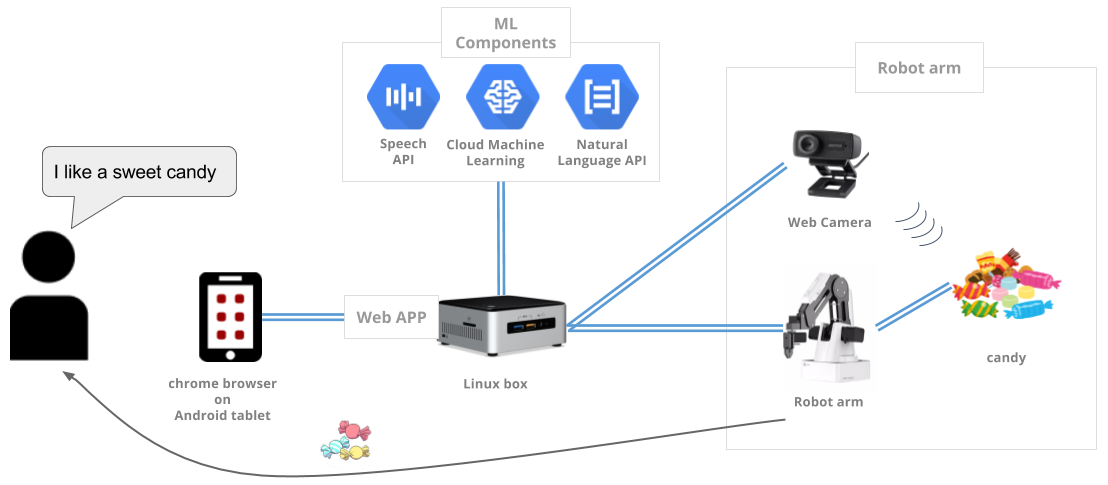
FindYourCandyは大きく分けて「UI」「Web App」「ML」「Robot Arm」「Camera」の5つの部分から構成されています。また、あらかじめ学習したモデルにしたがってお薦めのお菓子を選びユーザーに届ける「ServingMode」とその場で学習モデルを構築する「LearningMode」の2つのモードが用意されています。それでは各構成要素について説明していきます。
UI / Web App
UIはChromeブラウザを前提としており、入力には音声を用いるためマイクも必要となります。ローカルネットワーク上に配置したLinux Box上にメインとなるWeb Appをホスティングし、そこに接続させることでアプリを起動させます。FindYourCandyではマスタ情報などを管理するわけではないため、データベースの利用はありません。そのため、Web Appは基本的にUIとロジック部分をつなぐだけのシンプルな構造になっています。高度な機能は必要ないため、シンプルなWebフレームワークであるFlaskを採用しています。また、Linux BoxのOSはUbuntuを採用しており、USBを経由したカメラとロボットアームのコントロールPCとしての役割も担っています。
ML
機械学習部分には、Google Cloud Platformの機械学習系のサービスとTensorFlowを利用しています。音声認識部分にはCloud Speech API(ただし、現行のFindYourCandyはWeb Speech APIによる実装となっています。機能としてはCloud Speech APIと同等のものが得られます)、自然言語処理部分にはCloud NL APIとPythonのライブラリであるgensim、画像処理部分にはCloud Vision APIとOpenCVとTensorFlowを利用しています。Robot Arm / Camera
ロボットアームはDobotという中国・深センの企業が開発している比較的安価なロボットアームを採用しました。また、カメラはA3サイズを一度に撮影できる書画カメラを採用しました。ハードウェア部分に関しても可能な限り安価に調達できることを意識した構成となっています。
ServingModeとLearningModeについて
FindYourCandyでは初期状態として4つのクラス(ラベル)が学習された状態になっています。ServingModeでは、その学習済みのラベルの情報をうまく使うことでユーザーにお勧めのお菓子を選べるように設計されています。また、このラベルはLearningModeで学習し直すことができます。本記事は機械学習をテーマにした連載のため、カメラやロボットの詳しい解説は割愛します。機械学習部分のみにフォーカスすると、以下のようなステップを経てお勧めのお菓子が選ばれます。
1. ユーザーの発話を文字列に変換
2. 発話内容の形態素解析
3. 形態素解析結果の特徴量化
4. 画像の特徴量化
5. 発話内容と画像のマッチング
6. 4の部分については再学習可能
1~5がServingModeに相当し、6がLearningModeに相当する処理となります。
非常にシンプルなデモですが、「音声認識」「自然言語処理」「画像処理」の3つの機械学習を組み合わせており、ロボットアームと協調して動作するように作られています。まさにロボットを動作させる頭脳として機械学習を利用しているイメージです。機械学習部分にはGCPの機械学習系サービスを積極的に利用していますが、一部、クラウド側のサービスで足りない部分については、TensorFlowを利用して独自モデルを構築しています。その際「転移学習」と呼ばれるテクニックを利用するなど工夫を行っています。
それでは、次からはFindYourCandyが提供している2つの機能である「ServingMode」と「LearningMode」の説明を通じて、どのように機械学習を組み合わせているのか、またどのようにGCPの機械学習系サービスを活用しているのかを見ていきましょう。
2. 発話から好みのお菓子を特定して提供する
ServingMode
"ServingMode"は、その名の通りユーザーの発話に対してお薦めのお菓子を選び出し、ロボットがピックアップしユーザーに届ける、というモードです。図3にServingModeの全体像を示しました。

GCPの機械学習系サービスだけではなく、OpenCVやTensorFlowも活用していることが分かるかと思います。それでは具体的にServingModeで行われていることをみていきましょう。
以下で紹介するソースコードは、GitHub上で公開しています。
https://github.com/BrainPad/FindYourCandy
ユーザーの発話を文字列に変換
まずは、音声認識を利用して、ユーザーの発話を文字に起こします。現在のFindYourCandyでは、Web Speech APIで音声認識を実現していますが、Cloud Speech APIについても基本的な利用方法のイメージは同じとなります。音声データをクラウドにアップロードすることで結果として文字列データを得ることができます。ソースコードではDOM操作も含まれていますが、Web Speech APIに関する処理のみを抜き出すと以下のようになります。
// webapp/candysorter/static/js/init.js// 初期化var recognition = new webkitSpeechRecognition();// 中略// 言語選択 recognition.lang = lang;// 中略// Web Speech APIの利用 recognition.start();// 中略// 発話を文字列化した結果の取得 speechTxt = e.results[0][0].transcript |
非常に簡単に音声認識の機能が実現できることが確認できるかと思います。また、精度も非常によく、かなり特殊な専門用語でもない限り、精度良く文字起こしをしてくれます。
発話内容の形態素解析
文字列化した発話内容に対して、形態素解析を行います。MeCabなどのオープンソースの形態素解析エンジンなどもありますが、利用する場合はインストール作業や辞書の準備などの手順が必要になります。Cloud NL APIの利点としては、インストールや辞書の準備などの手順が必要なく、多言語(現在サポートされている言語はこちらで確認してください)に対応できることや、形態素解析以外にも固有表現や感情分析などの機能も提供されている点が挙げられます。それでは、実際にどのように利用しているか確認していきましょう。
具体的には以下のように、text_analyzer.analyze_syntax()に、文字起こしした発話内容を与えています。
@api.route('/morphs', methods=['POST'])@id_requireddef morphs(): text = request.json.get('text') if not text: abort(400) lang = request.json.get('lang', 'en') logger.info('=== Analyze text: id=%s ===', g.id) tokens = text_analyzer.analyze_syntax(text, lang) return jsonify(morphs=[ dict(word=t.text.content, depend=dict(label=t.dep.label, index=[ _i for _i, _t in enumerate(tokens) if _i != i and _t.dep.index == i ]), pos=dict(tag=t.pos.tag, case=t.pos.case, number=t.pos.number)) for i, t in enumerate(tokens) ]) |
内部的には、text_analyzer.analyze_syntax()は、Googleが提供しているGoogle cloud用のクライアントライブラリを拡張したクラスで、文字列データをクラウドにPOSTすることで実現しています。以下に該当部分を掲載します。
class Document(language.Document): def analyze_syntax(self): data = { 'document': self._to_dict(), 'encodingType': self.encoding, } api_response = self.client._connection.api_request( method='POST', path='analyzeSyntax', data=data) return [Token.from_api_repr(token) for token in api_response.get('tokens', ())] |
形態素解析結果の特徴量化
ここからは少し機械学習のAPIサービスから離れます。形態素解析の結果を特徴量化するためにWord2vecと呼ばれる手法を利用します。Word2vecとは、簡単に説明すると単語のベクトル表現を得られる手法です。これを利用することで単語同士の距離や単語同士の計算などが簡単に実現できます。この特性を利用し、形態素解析の結果得られた形容詞と名詞を用いて、Word2Vecにより学習済みのラベルとの距離を算出します。具体的には次のように算出しています。
def calc_similarities(self, tokens, lang='en'): t_v = self._tokens_vector(tokens, lang) return np.array([ 1. - spatial.distance.cosine(t_v, l_v) for l_v in self._label_vectors(lang) ]) |
_tokens_vector()が形態素解析の結果をベクトル化したもので、_label_vectors()がラベルをベクトル化したものです。最後に双方のベクトルを比較してコサイン類似度を取ることで発話内容と事前に学習していた各ラベルとの距離をもとにした新しい特徴量が生成されます。
画像の特徴量化
次に画像処理部分に移ります。画像処理にはOpenCVとCNN(Convolutional Neural Network)を用いています。まずテーブルに置いてあるお菓子をOpenCVによって1つずつ個別に切り出します。次に、各お菓子画像に対してCNNを利用し各ラベルであると推定される確率を算出します。これによって、各お菓子画像にラベルへの近しさが特徴量として生成された状態となります。具体的には次のようになります。
candy_sims = [candy_classifier.classify(c.cropped_img) for c in candies] |
candy_classifierは画像を入力として、どのラベルにもっとも近しいかを判定するCNNです。
candy_classifier.classify()によって、入力画像の特徴量化が行われていることを確認することができます。
発話内容と画像のマッチング
最後に発話内容を特徴量化したベクトルと、各お菓子画像を特徴量化したベクトル同士を比較してお勧めのお菓子を決定します。現在のアルゴリズムでは、具体的には次のように2つのベクトルで内積を取り、その値が最大になったお菓子を選択するように決定しています。
nearest_idx = np.argmax([speech_sim.dot(s) for s in candy_sims]) |
これは、ベクトル演算における、内積の値が大きいほど2つのベクトルは似ているという特徴を利用しています。すなわち、事前に用意された4つのラベルに対して、発話内容がどのくらい似ているかという観点での類似度ベクトルと、お菓子画像がどのくらい似ているかという観点での類似度ベクトルの双方が最も類似しているお菓子を選んでいることになります。マッチングのアルゴリズムは様々に考えられますが、今回はこのようなアプローチを採用しました。シンプルながら体感的には比較的精度が良いように思われます。実際に案件やサービスなどで機械学習を利用する時は、定めた目標に対して定量的にモデルやアルゴリズムの正しさを評価し、パラメータのチューニング等の種々の工夫を行う必要がありますが、今回はデモ用ということもあり、可能な限りシンプルな作りにしています。
3. その場でモデルを学習させるLearningMode
LearningModeはServingModeで使われている機械学習の技術の中の、画像認識部分のモデルをその場で作り直すことができるモードです。図4にLearningModeの全体像を示しました。
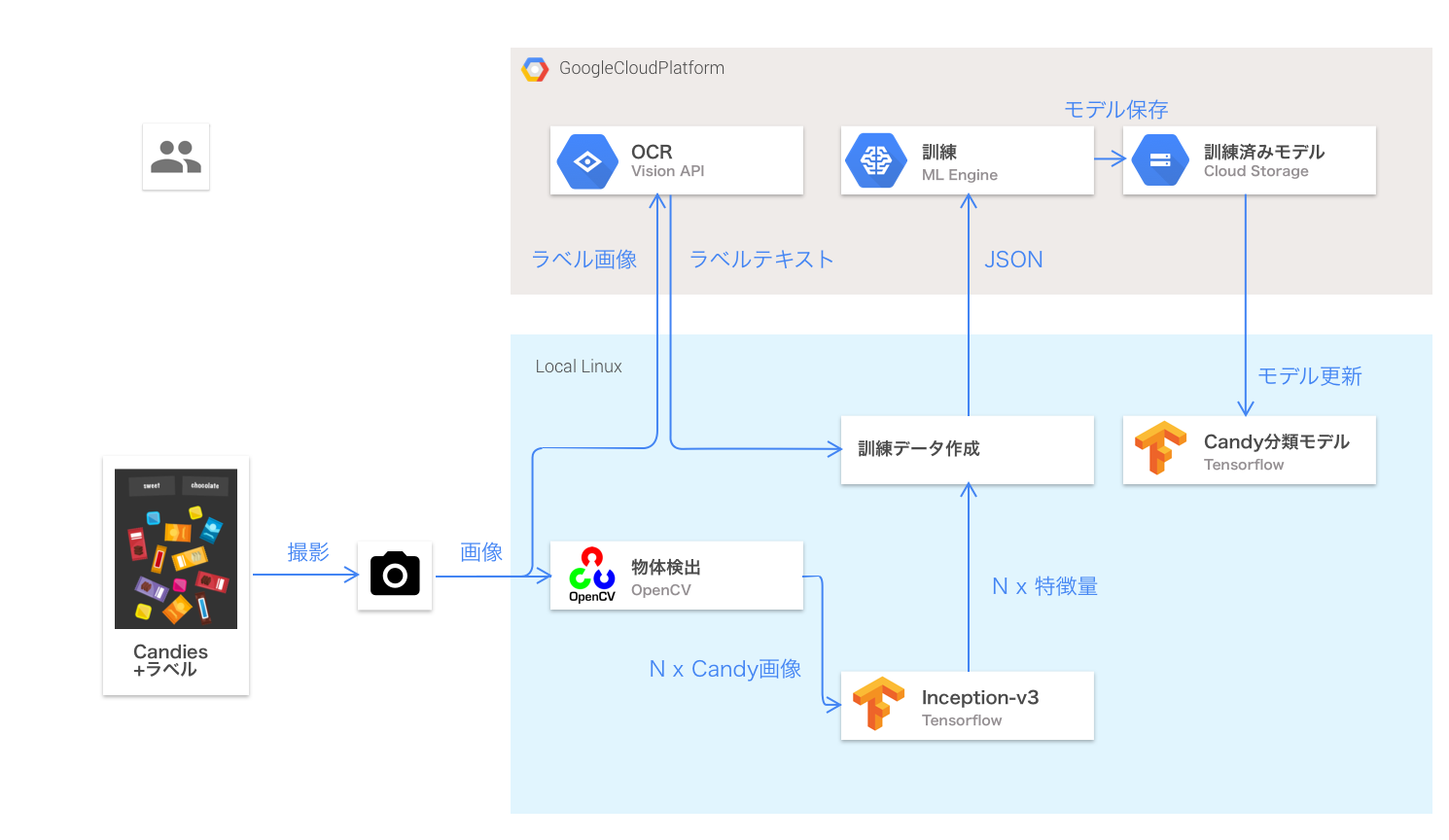
前述のとおり、FindYourCandyでは4つのラベルを与えて学習させることができます。ここでの学習とは、アルゴリズムとしてCNNを用い、学習データとしてお菓子画像を与えることで、お菓子とラベルの関係性を学習させることに相当します。LearningModeでのポイントは、手書きで作成されたラベルとお菓子画像を紐付けて認識できることと、転移学習と呼ばれるテクニックを用いて、少ない学習データでも精度の高いモデルが作られている点です。手書き文字の認識にはCloud Vision APIのOCR機能を用い、CNNの学習にはTensorFlowを用いてCloud ML Engine上で学習処理を行っています。
テーブル上のラベルとお菓子の認識

まずは手書きで作られた任意の文字列をラベルとして認識します。所定の位置に置かれた手書きラベルを次のようにCloud Vision APIのOCR機能を使って文字列として認識します。
def detect_labels(img): image = vision_client.image(content=cv2.imencode('.jpg', img)[1].tostring()) # 中略 labels = set() for text in texts: words = [w.upper().strip() for w in text.description.split()] words = [w for w in words if w] labels.update(words) return list(labels) |
Cloud NL APIを利用する時と同様に、クライアントライブラリが提供されているため、簡単にOCR機能を使うことができます。それぞれのお菓子については、OpenCVを使って切り出しています。
転移学習によるモデル構築
今回の学習モデルはGoogleによって公開されているInception v3と呼ばれているモデルを利用しています。Inception v3はImageNetと呼ばれる画像分類のための大規模なベンチマークデータセットを高い精度で分類可能なモデルです。Inception V3の概要図を以下に示します。

Inception v3は一般的なモノの概念を学習したモデルのため、残念ながら今回のデモのようにお菓子それぞれを分類するようなモデルでありません。そのため、Inception v3をそのまま利用するということは今回のデモの用途に関しては適当ではありません。一方で、個別のお菓子を識別するようなモデルを一から学習するためには大量のお菓子画像が必要になります。そこで、FindYourCandyの学習には転移学習と呼ばれるテクニックを用いています。記事のスペースの都合上、転移学習の詳細はここでは説明しません。ソースコード上でご確認ください。簡単にイメージだけ述べると、学習済みのInception v3の最終層を取り、代わりに独自の層を2層追加しています。テーブルのお菓子画像をInception v3に通して得られる特徴量を入力としその2層分の学習をCloud ML Engine上で行います。
Cloud ML Engineによる学習
Cloud ML Engineは他の機械学習系サービスとは少し毛色が異なります。Cloud ML Engineは特定の機械学習の機能を提供しているのではなく、マネージドなTensorFlowの実行環境を提供してくれます。すなわち、ユーザーが作成したTensorFlowのコードをもとに、学習や推論などを行ってくれるサービスとなります。今回は、上述した転移学習の実行をCloud ML Engineで実行します。実行過程はStack Driverのログとして確認することができます。FindYourCandyではこのログと連携することで、リアルタイムに学習過程をWebアプリから確認できるように工夫しています。
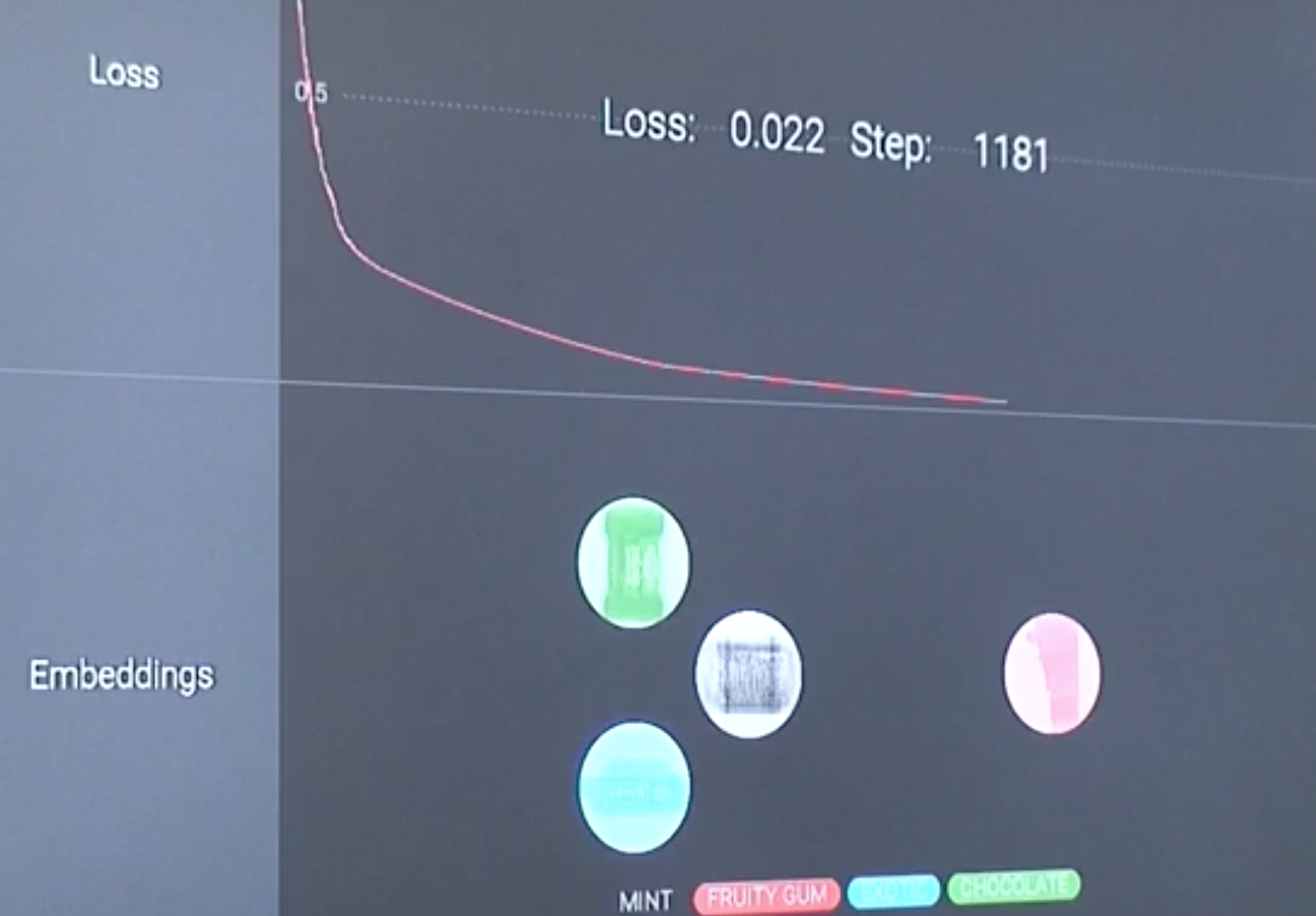
最終的に得られた学習結果のモデルをローカル環境にダウンロードし、次回からのServingModeで利用するようにしています。
4. FindYourCandyをセットアップしてみよう
それではいよいよFindYourCandyのセットアップを行っていきましょう。FindYourCandyに必要なもの、セットアップの手順はすべてこちらに記載していますので、ここからはそれぞれのステップのポイントをかいつまんで説明します。
ハードウェアの準備
こちらのリストに従い必要物品を用意してください。ロボットアームの入手には比較的時間がかかってしまいますのでご注意ください。トータルで、25,000ドル程度で全てのハードウェアは調達することができます。
Linux Boxのセットアップ
Web Appのホスト及びロボットとカメラのコントロールPCとして動作させるLinux BoxのOSにはUbuntu 16.04を想定しています。GitHubのレポジトリからソースコード一式を持ってきた上で、種々のセットアップを行ってください。デモで利用するため、ネットワークは全て有線での接続を前提としています。余談となりますが、UIに使っているタブレットを有線で接続するため、Chromecast Ultraに付属している電源アダプターを活用しています。
Google Cloud Platformのセットアップ
デモ用のGCPプロジェクトを用意してください。もちろん、既存のプロジェクトを流用いただく方法でも問題ありません。GCS、Vision API, Speech API, NL API, Cloud ML Engine を有効化した上でクレデンシャルを作成してください。この辺りの手順は第0回を参考にしていただければと思います。
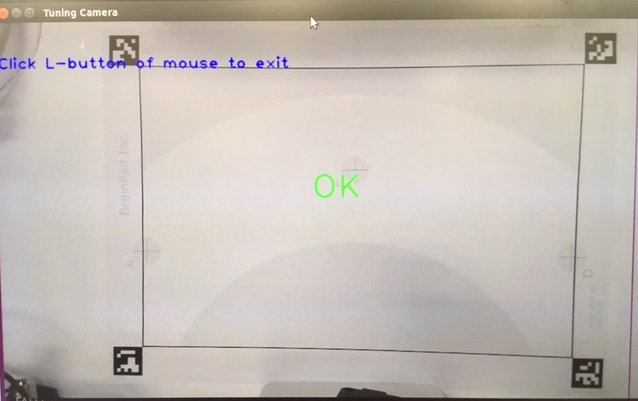
カメラのキャリブレーション
続いてロボットの目となるカメラのセットアップです。まずはマーカーシートをA3用紙に印刷していただき、セットアップ用のアプリを起動します。GUIでフォーカスやキャリブレーションを調整できます。マーカーシートの4隅がカメラ内にうまく入るように調整すると下記のように「OK」の文字がでます。
ロボットアームのキャリブレーション
最後にロボットの位置補正を行います。今回はお菓子という比較的小さなものをピックアップするため、ロボットアームの位置については慎重に調整する必要があります。こちらもインタラクティブに調整するためのソフトウェアを用意しています。現在ロボットアームが置かれている位置と、マーカーシート上の三点の座標を教えることで調整が行われます。
ここまででセットアップの手順は終了です。お疲れ様でした。最後にタブレットでWeb AppにアクセスするとFindYourCandyをお試しいただくことができます。
5. おわりに
今回は、機械学習とロボットアームを組み合わせたデモシステムであるFindYourCandyをご紹介しました。様々な機械学習のモデルを一から作るとなると大変な時間と労力が必要となりますが、今回はGoogle Cloud Platformの各種機械学習サービスを活用し、公開されている学習済みモデルを利用することで高い精度を達成しながらも非常に短い工数でシステムが構築できました。実際に、FindYourCandyはロボットの選定と仕様調整も含めて5人のチームによって約1ヶ月で開発しました。アプリケーションを試された後は他の連載回と同じく、適切に後片付けを行い課金が発生しないようにしましょう。

