2017.05.19
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第5回 もう議事録不要? 写真から手書き文字を認識するAndroidアプリを作ろう~アプリ開発編~
連載第4/5回目では、Google Cloud Vision APIの光学的文字認識(OCR)機能をつかって、カメラで撮影した写真の中に含まれる文字を認識するAndroidアプリ「PhotoOCR」を作成します。第4回では、Androidアプリケーションの開発環境の準備と実機での動作確認を行い、HelloWorldが表示されるサンプルアプリが動くところまでを確認しました。第5回では、いよいよ機械学習APIをつかったAndroidアプリケーションを開発していきましょう。対象読者や本稿での環境、アプリケーションの全体像は第4回を参照してください。
1. サンプルアプリケーションをダウンロードしよう
それでは、サンプルアプリケーションを開発用PCにダウンロードし、コードを修正していきましょう。サンプルアプリケーションのダウンロードではGitHubのアカウントを使いますが、アカウントをお持ちでない方の説明も後述しています。
1-1 サンプルアプリケーションのダウンロード
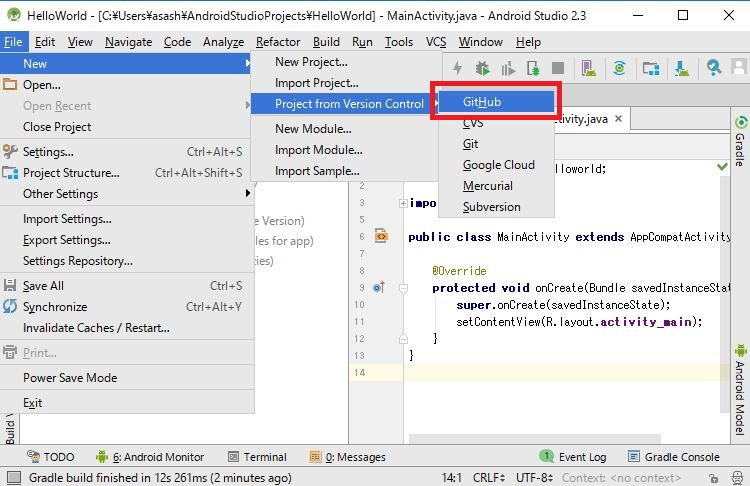
Android Studioを起動します。メニューから[File]―[New]―[Project from Version Control]―[GitHub]を選択します。
GitHubの認証情報を聞かれますので、GitHubのログイン名とパスワードを入力し、[Login]ボタンをクリックします。

次に、GitHubのリポジトリを聞かれますので、ここで「Git Repository URL」を「https://github.com/asashiho/PhotoOCR」として、[Clone]ボタンをクリックします。これで開発用PCにクローンできました。
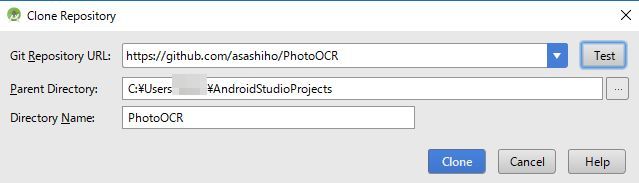
ここで、クローンした新しいプロジェクトを、Android Studioのどのウインドウで開くかを聞かれますので、[This Window]ボタンをクリックします。
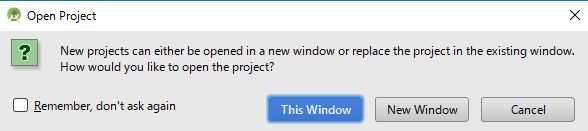
問題なく開発用PCにサンプルアプリケーションがクローンできたら、次の画面が表示されるので[OK]ボタンをクリックします。
2. Android Studioの使い方
Android Studioは、JetBrains社が開発した「IntelliJ IDEA」をベースに作られています。まず、画面の左端の[Project]ボタンをクリックすると、開発中のプロジェクトが開きます。
図の左側(赤の領域)がプロジェクトツールウィンドウで、右側(緑の領域)がエディタウィンドウです。プロジェクトツールウィンドウのファイルをクリックすると、エディタウィンドウでファイルが編集できます。左側のプロジェクトツールウィンドウで、[app]の下にあるフォルダをクリックして開きながら以下をご覧ください。
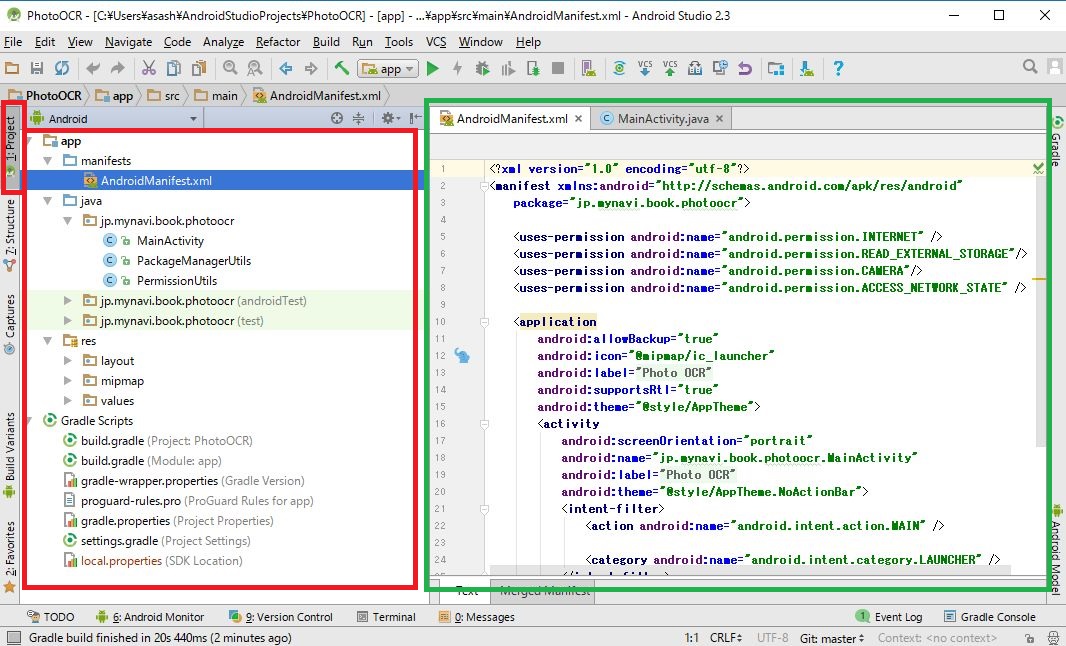
Androidアプリケーションの開発では、主に実機を使ってデバッグを行います。開発したアプリケーションをビルドするときは、画面上部の[▶」アイコンをクリックします。ビルドおよび実行中の詳細なログなどを確認するときは、画面下部(赤の領域)のデバックウィンドウを確認します。

ビルドが完了すると、アプリケーションの実行に必要なファイルが1つにまとめられたapkパッケージが、USBケーブルで繋がったAndroid端末に配置されます。これを図で表すと、次のようになります。
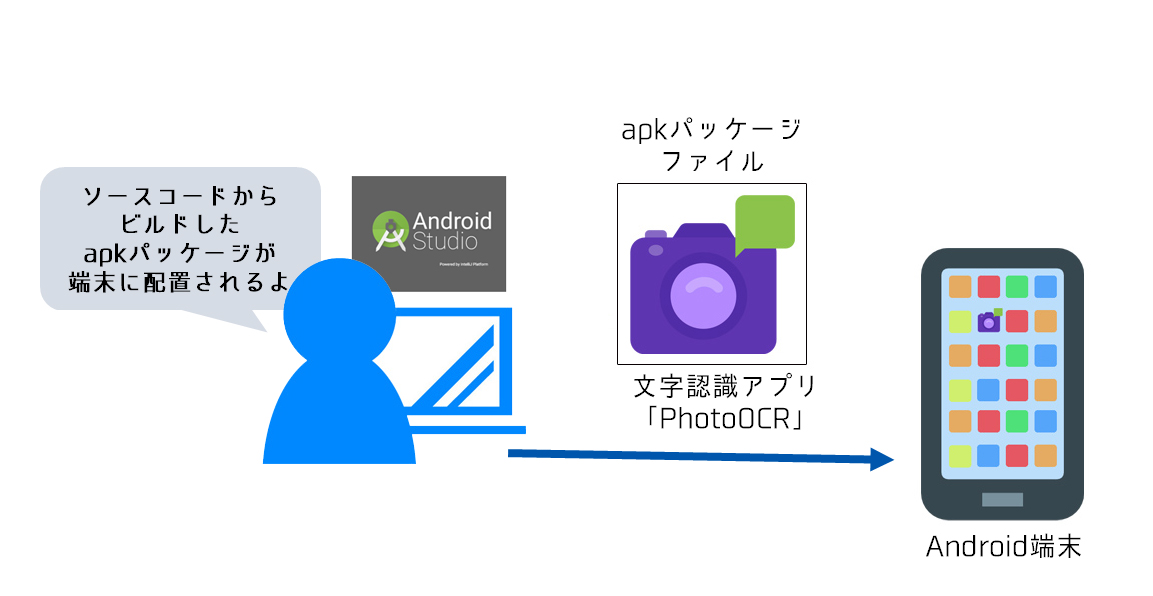
開発したアプリケーションは、「Google Play」でダウンロードしたアプリと同じようにAndroid端末で実行できます。
2-1 サンプルアプリの構成
Androidアプリケーションは、Androidフレームワークに則って開発が行われます。ここで、サンプルアプリケーションの構成を簡単に説明します。ファイルの構成は次の図のようになっています。
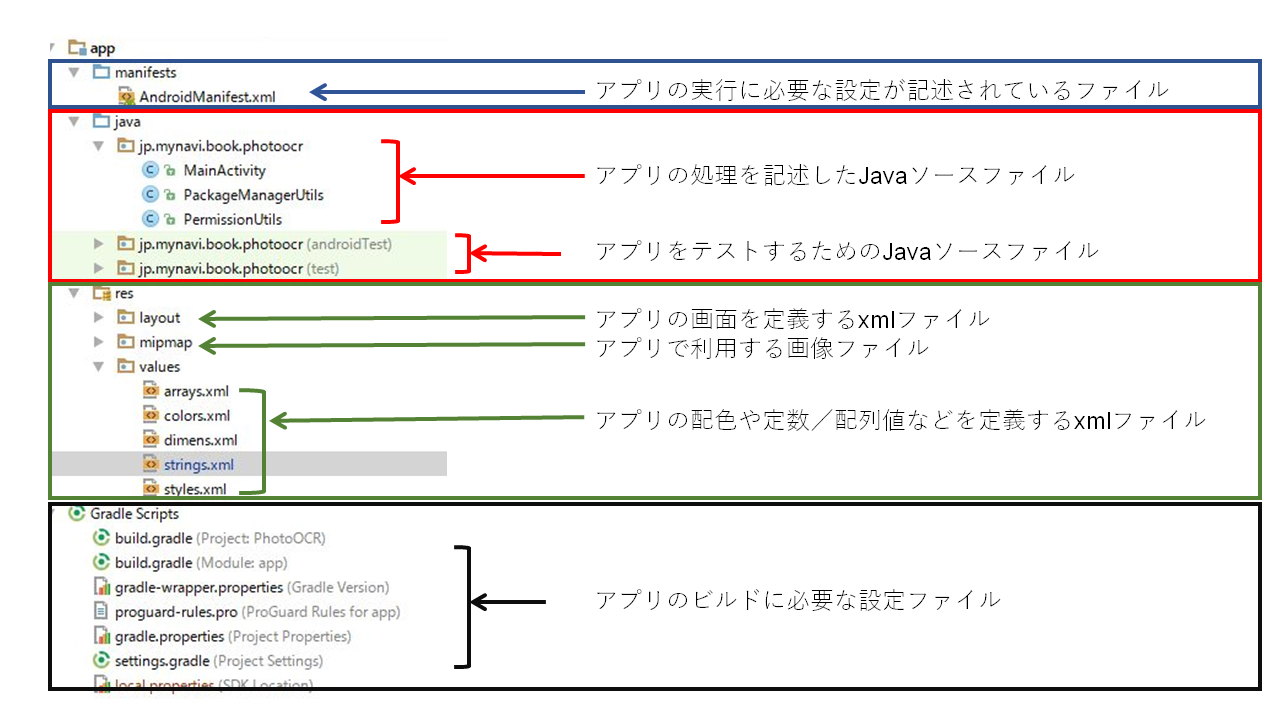
アプリケーションの実行に必要なファイルは、「manifests」「java」「res」の3フォルダに分かれています。また、Androidアプリケーションは、オープンソースビルド自動化システムであるGradleを使ってビルドを行います。このGradleに必要な設定ファイルも用意します。
2-2 [manifests]フォルダ
このフォルダには、Androidアプリケーションの実行に必要な設定が含まれる、AndroidManifest.xmlが格納されています。このAndroidManifest.xmlには、アプリケーションの名称やUIのスタイル、後述するアクティビティの指定などを行います。
また、Androidアプリケーションが、デバイスまたはネットワーク上のリソースにアクセスするときなどは、明示的に権限を与える必要があります。
たとえば、今回のサンプルアプリケーションでは、ネットワーク経由でCloud Vision APIを呼び出すため、「android.permission.INTERNET」「android.permission.ACCESS_NETWORK_STATE」、Android端末のカメラやストレージを利用するので「android.permission.CAMERA」「android.permission.READ_EXTERNAL_STORAG」の権限を付与する定義を行っています。
<?xml version="1.0" encoding="utf-8"?> package="jp.mynavi.book.photoocr"> <uses-permission android:name="android.permission.INTERNET" /> <uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/> <uses-permission android:name="android.permission.CAMERA"/> <uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />~中略~</manifest> |
2-3[java]フォルダ
このフォルダには、Androidアプリケーションの処理部分をしたJavaのソースファイルが格納されています。また、AndroidアプリをテストするためのJavaソースファイルもこの[java]フォルダに格納します。
Androidアプリケーションは、処理をJavaクラスに、画面構成をxmlファイルに記述し、このファイルのペアでひとつの画面が作られます。この画面に紐づいたJavaクラスのことをアクティビティと呼びます。アクティビティはActivityクラス(またはそのサブクラス)を継承して作ります。
今回のサンプルアプリでは、アプリケーションを起動したとき最初に表示される画面に紐づいたアクティビティは、MainActivity.javaです。
アクティビティは、ActivityクラスのサブクラスであるAppCompatActivityクラスを継承しています(以下ソースコードの【1】)。アクティビティのライフサイクルの状態の切り替え時(アクティビティの作成、停止、再開、破棄など)にシステムが呼び出すコールバック メソッドをオーバーライドして実装します。たとえば、アクティビティの生成時に呼び出されるonCreateメソッドには、アクティビティの必須コンポーネントを初期化する必要があります。 そして、setContentView()を呼び出してアクティビティに紐づくレイアウトファイル(後述)を定義します。ここのサンプルの例ではレイアウトファイルを「R.layout.activity_main」と指定しています【2】。
package jp.mynavi.book.photoocr;~中略~public class MainActivity extends AppCompatActivity { ← 【1】 ~中略~ @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); ← 【2】 ~中略~} |
Androidアプリケーションを開発するときは、このアクティビティの仕様およびライフサイクルを理解することが重要です。以下の公式サイトに詳細が記述されていますので、ぜひ一度目を通してみてください。
https://developer.android.com/guide/components/activities.html?hl=ja
2-4 [res]フォルダ
Androidアプリケーションで使用する画像ファイルやUIのスタイル定義などのリソースを格納するフォルダです。
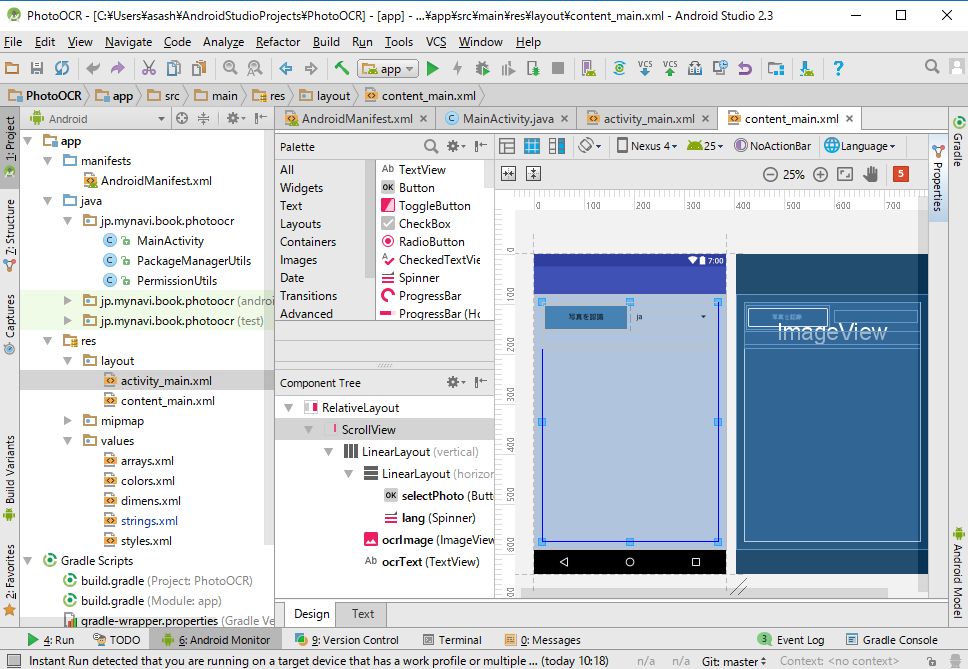
2-5 [layout]フォルダ
Androidでは画面構成をxmlファイルに記述します。これをレイアウトファイルといいます。レイアウトファイルには、どのUIコンポーネント(たとえばTextViewやImageViewなど)を、どう配置するか(LinearLayoutなど)を定義します。今回のサンプルでは、activity_main.xmlとcontent_main.xmlを使います。
このレイアウトファイルは、前述したアクティビティとペアになっています。レイアウトファイルがどのアクティビティのクラスに対応するかは、tools:contextで指定します(以下ソースコードの【1】)。
<?xml version="1.0" encoding="utf-8"?> ~中略~ tools:context="jp.mynavi.book.photoocr.MainActivity" ←【1】 tools:showIn="@layout/activity_main"> <ScrollView ~中略~ |
なお、Android StudioではGUIツールを使ってUIコンポーネントのデザインを行うことも可能です。
2-6[mipmap]フォルダ
このフォルダはアプリケーション内で使用する画像を格納します。また、アプリのアイコンは、ic_launcher.pngという名前のファイルを用意します。解像度によって複数のサイズのアイコンが必要です。
2-7[values]フォルダ
このフォルダには、アプリで表示するメッセージなどの文字列(strings.xml)や画面のスタイル(styles.xml)色の定義(colors.xml)を表すxmlファイルなどを格納します。
2-8 Gradle Scripts
Android StudioはビルドシステムとしてGradleを使用しています。その際に使用するビルドソースコードを格納します。
3. Vision APIを呼び出そう
それでは、アプリケーションの概要が分かったところで、いよいよ機械学習APIであるCloud Vision APIを呼び出して、アプリケーションを完成させましょう。Cloud Vision APIとは、Google Cloud Platformの機械学習APIの1つで、画像に何が映っているかを認識できます。
3-1 APIキーの設定
AndroidアプリケーションからCloud Vision APIにアクセスするには、REST APIを使うか、Cloud Vision API Client Librariesを使う方法がありますが、今回はCloud Vision API Client Librariesを利用します。
[Cloud Vision API Client Libraries公式サイト]
https://cloud.google.com/vision/docs/reference/libraries
まず、連載の第0回の「5. Vision APIで画像認識してみよう」を参考にして、APIキーを発行してください。
まず、Vision APIの呼び出しのために、APIキーを設定します。Android Studioのプロジェクトの[app]―[res]―[values]―[strings]を開き、XMLファイルに取得したAPIキーを設定します。
<!-- Vision APIのAPIキーを設定 --><!-- 例えば、APIキーが「abcdefg12345」の場合次のように指定します --><string name="vision_api_key">abcdefg12345</string> |
なお、このstrings.xmlには、アプリケーションで利用するメッセージなどを定義していますので、カスタマイズするときはこのファイルを変更してください。
3-2 Vision APIの呼び出し処理
これで、Vision API呼び出しの準備ができましたので、実際にVision APIを呼び出すメソッドを確認しておきます。Android Studioのプロジェクトの[app]―[java]―[jp.mynavi.book.photoocr]―[MainActivity]を開きます。ここでは、ポイントとなるコードのみ説明します
まず、Cloud Vision API Client Librariesを利用するために必要なパッケージを、importします。
// Google Cloud Vison APIの呼び出しに必要なパッケージimport com.google.api.client.extensions.android.http.AndroidHttp;import com.google.api.client.http.HttpTransport;import com.google.api.client.json.JsonFactory;~中略~import com.google.api.services.vision.v1.model.Feature;import com.google.api.services.vision.v1.model.Image;import com.google.api.services.vision.v1.model.ImageContext; |
実際のAPI呼び出しは、callCloudVisionメソッドで行います。MainActivityクラスは、画面に紐づいたクラスであるため、たとえばネットワーク経由でAPIを呼び出すなど時間のかかる処理を行うと、利用者からは処理中にもかかわらず「画面が固まった」ようにみえてしまいます。そこで、これらの時間のかかる処理は、UIの表示とは別で非同期で行う必要があります。Androidアプリケーションでは、非同期処理を行うためAsyncTaskを使います(以下ソースコードの【1】)。
今回のサンプルでは、AsyncTasksをメンバークラスとして生成し、doInBackgroundメソッドに非同期で行いたい処理を記述します【2】。このdoInBackgroundメソッドはAsyncTaskクラスで、抽象メソッドとして定義されていますので、オーバーライドして実装する必要があります。
private void callCloudVision(final Bitmap bitmap) throws IOException { ~中略~ // API呼び出しを行うための非同期処理 new AsyncTask<Object, Void, String>() { ←【1】 @Override protected String doInBackground(Object... params) { ←【2】 try { HttpTransport http = AndroidHttp.newCompatibleTransport();~中略~ |
次に、Vision APIを呼び出すリクエストの生成のため、Vision.Builder をインスタンス化します(以下ソースコードの【1】。APIを呼び出すためのリクエストは、BatchAnnotateImagesRequestを使います【2】。まず、Vision APIに送信する画像をBase64エンコードし、setImageメソッドの引数にセットします【3】。
// リクエストの作成Vision.Builder builder = new Vision.Builder(http, jsonFactory, null); ←【1】~中略~BatchAnnotateImagesRequest batchImgReq = new BatchAnnotateImagesRequest(); ←【2】batchImgReq.setRequests(new ArrayList<AnnotateImageRequest>() {{ AnnotateImageRequest annotateImgReq = new AnnotateImageRequest(); // 画像のJPEGへの変換 Image base64Image = new Image(); ByteArrayOutputStream out = new ByteArrayOutputStream(); bitmap.compress(Bitmap.CompressFormat.JPEG, 90, out); byte[] imageBytes = out.toByteArray(); base64Image.encodeContent(imageBytes); annotateImgReq.setImage(base64Image); ←【3】~中略~ |
Featureオブジェクトは、どの画像解析に機能を利用するかを指定するオブジェクトです。Vision APIには、光学式文字認識(OCR)以外にもラベル検出やロゴ検出画像やランドマーク検知などさまざまな機能をもっていますが、どの機能を使うかをsetFeaturesメソッドで設定します。
| 項目 | setTypeでの設定値 | 説明 |
|---|---|---|
| ラベル検出 | LABEL_DETECTION | 乗り物や動物など、画像に写っているさまざまなカテゴリーの物体を検出 |
| 有害コンテンツ検出 | SAFE_SEARCH_DETECTION | アダルト コンテンツや暴力的コンテンツなどの有害コンテンツを検出 |
| ロゴ検出 | LOGO_DETECTION | 画像に含まれる一般的な商品ロゴを検出 |
| ランドマーク検出 | LANDMARK_DETECTION | 画像に含まれる一般的な自然のランドマークや人工建造物を検出 |
| 光学式文字認識(OCR) | TEXT_DETECTION | 画像内のテキストを検出/ 抽出。言語の種類も自動判別 |
| 顔検出 | FACE_DETECTION | 画像に含まれる複数の人物の顔を検出。感情の状態や主要な顔の属性について識別 |
| 画像特性 | IMAGE_PROPERTIESN | ドミナント カラー(支配色)などの画像特性を検出 |
3-3 Vision APIの主な機能
今回は文字認識を行うOCR機能を使用するため、setTypeメソッドで「TEXT_DETECTION」をセットします(以下ソースコードの【4】)。ここで指定できる値は以下の表のとおりです。なお、処理結果の最大数は、setMaxResultsメソッドで指定できます【5】。
// Vision APIのFeatures設定 annotateImgReq.setFeatures(new ArrayList<Feature>() {{ Feature textDetect = new Feature(); // OCR 文字認識'TEXT_DETECTION'を使う textDetect.setType("TEXT_DETECTION"); ←【4】 textDetect.setMaxResults(10); ←【5】 add(textDetect); }});~中略~ |
最後に、Vision APIで判定する言語をsetLanguageHintsメソッドにセットします(以下ソースコードの【6】)。このサンプルでは、画面の選択項目(Spinner)でセットされた値を取得し、メソッドに渡しています。なお、言語はリストで複数の値を渡せます。また、Vision APIは言語を指定しない場合、自動判定されますので明示しなくても動作します。
// 言語のヒントを設定 final Spinner selectLang = (Spinner) findViewById(R.id.lang); // UIで選択された言語を取得する List<String> langHint = new ArrayList<String>(); langHint.add(selectLang.getSelectedItem().toString()); ImageContext ic= new ImageContext(); ic.setLanguageHints(langHint); annotateImgReq.setImageContext(ic); ←【6】 // リクエストにセット add(annotateImgReq);~中略~ |
その他、Androidのカメラデバイスやストレージへのアクセスや、取得した画像の変換処理などはソースコードを参照してください。Androidアプリケーション開発の詳細なドキュメントは、以下の公式サイトを参照してください。
https://developer.android.com/index.html
4. 写真に含まれる「文字」を認識してみよう
それでは、いよいよAndroid端末で、サンプルアプリを実行させてみましょう。
4-1 プロジェクトのビルド
Android Studioが起動している状態で、開発用PCとAndroid端末をUSBケーブルで接続します。メニューのRUNボタン(▶)、または[Shift]+[F10]をクリックします。実行するデバイスを選択するダイアログが表示されるので、ここではUSBケーブルで接続したAndroid端末を選び、[OK]ボタンをクリックします。

ビルドに少し時間がかかりますが、端末にアプリケーションがインストールされ実機確認ができます。なお、使用するUSBケーブルには、「データ転送用」のものと「充電用」のものがあります。充電専用のUSBケーブルでは実機確認ができませんので、注意してください。
4-2 動作確認
アプリケーションが起動すると、画像を選択するボタンが表示されれるので、クリックします。画像をカメラまたはギャラリーから選択するダイアログが表示されるので、どちらかを選びます。その際、アプリケーションに対してデバイスの使用権限を許可するかどうかのダイアログが表示されるので、[許可]を選びます。


ここで文字が含まれる写真をカメラで撮影、またはギャラリーから選択します。すると、画像がVision APIにアップロードされ、画像中の文字がデータとして認識されます。印刷した文字だけでなく、手書き文字も認識できますので、いろいろな画像を使って試してみてください。

応用例として、認識した文字をファイルに保存する機能や、Cloud Translation APIを使った翻訳機能、また音声合成APIなどと組み合わせた読み上げ機能など、実用的なアプリケーションを試してみてください。
5. おわりに
前回および今回にわたり、モバイル+機械学習を組み合わせたアプリケーションの簡単なアプリケーションを開発しました。カメラやセンサーなどを利用してデータを取得できるモバイル端末と機械学習APIを組み合わせることで、アイデア次第で実用的なアプリケーションが短期間で開発できるのがお分かりいただけたかと思います。業務システムなどでは、紙を使って処理しているフローを見直し、データを電子化することで、人間による手作業を減らすことにつながるかもしれません。
「モバイルアプリケーションの開発は、なんだか大変そう……」「機械学習は敷居が高くて……」。漠然とそういう思いをお持ちの方もいるかもしれませんが、まずは今回ご紹介したようなアプリケーションを、実際に手を動かして作ってみることで、ものづくりの面白さの第一歩を実感していただければと思います。
もちろん、本格的なモバイルアプリケーションの開発は、コーディングだけでなくハードウエアの知識も必要になります。また、機械学習を使ったアプリケーションを作るためには、収集するデータやアルゴリズム/数学などの深い知識が不可欠です。しかし、なにより「こんなアプリがあれば、きっと世の中が良くなるはずだ!」という気持ちが大事なので、どんどん手を動かし、皆さんの面白いアイデアを、ぜひ形にして「Google Play」で世界中に配信してみてください。

