2017.05.11
第5回 アクション回数に応じた定着率を集計する
ユーザーのサービス利用開始から日時が経過すると、ロイヤリティが高いユーザーに成長する、あるいは利用を中止して退会、登録は残っているものの再び利用することがない状態(休眠)になるなど、ユーザーの状態に変化が生じます。
・ユーザーが継続して利用する(リピート)
・ユーザーが利用を中止する(退会・休眠)
サービスを運営する側としては、継続して利用してもらうことを願っています。そのためには、まずどの程度のユーザーが継続して利用しているのかを把握して、目標に対する乖離をどのように埋めるか検討する必要があります。また、しばらくサービスの利用がなかったり、休眠の傾向があるユーザーに対しては、継続してもらうための工夫を常に考えたいと思っているはずです。
退会ユーザーに対する施策は実施が困難ですが、休眠ユーザーに対しては、メルマガやCM、広告などの施策で、利用を再開してもらいたいところです。
ユーザーのサービス利用に対する時系列の変化を数値化し可視化することで、現状の把握、施策の効果、今後の計画に役立つ糸口となるレポートと集計するSQLを解説するChapter5-2「ユーザー全体の時系列による状態変化を見付ける」から、5-2-4「アクション回数に応じた定着率を集計する」を紹介します。
本節では、下記に示す2つのテーブル、ユーザーマスタとアクションログを元に解説します。SNSに代表されるコミュニティサービスを想定してください。
●データ:ユーザーマスタ(mst_users)

●データ:アクションログ(action_log)
FacebookやTwitterなどに代表されるSNSの事例で、「登録後1週間以内に10人をフォローしたらユーザーはサービスを継続的に利用する」ことを耳にしたことはないでしょうか。このような調査結果から、大きな方針を示すことができれば、「○○さんは友達ではないですか?」、「人気のユーザーをフォローしましょう」などを表示するモジュールを開発したり、チュートリアルに人気ユーザーをフォローする導線を設けるなど、サービスの活性化に繋がる具体的な施策を検討できます。
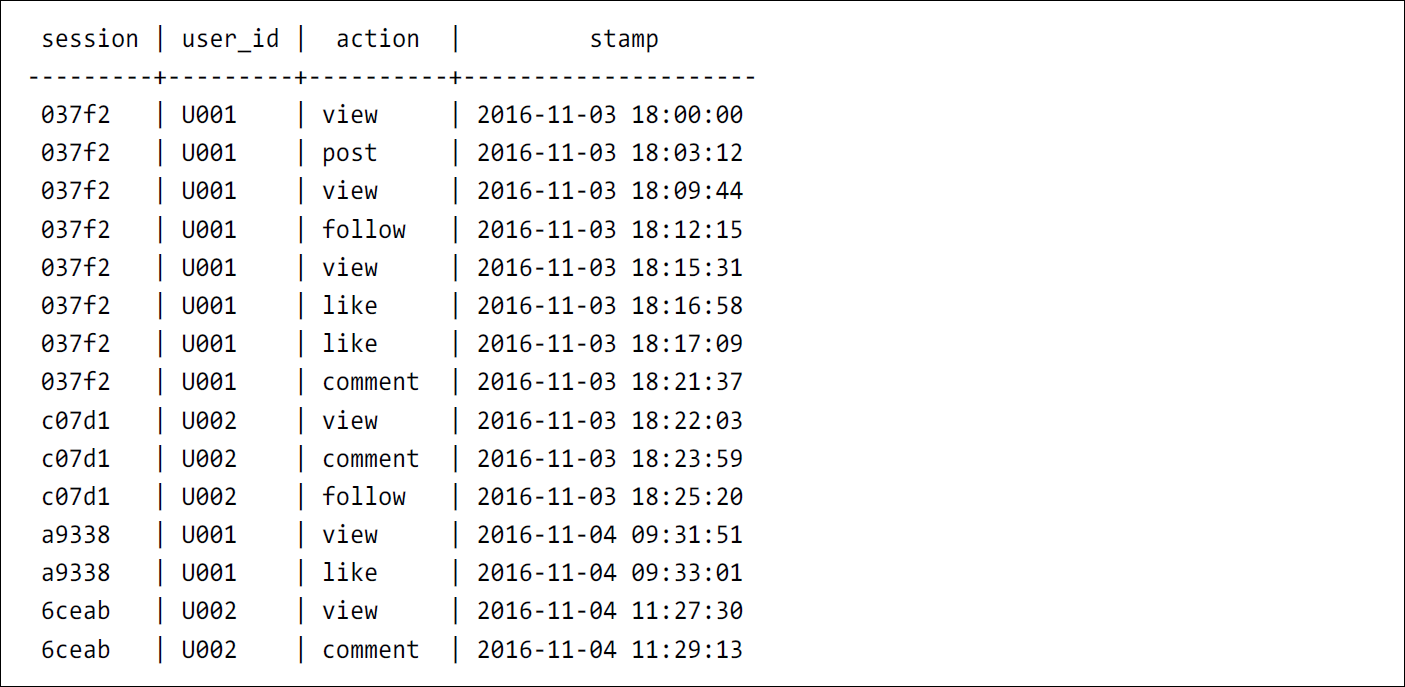
本項では例として、下図に示す通り、登録日と登録日以降の7 日以内(7 日定着判定期間)に実行したアクション数に応じて、14 日定着率に変化があるかを集計します。

本項では、下図に示す通り、各アクション別に度数分布表を作成し、達成者における14日定着率を 集計するクエリを紹介します。
まず、上図に示したアクションの階級マスタを一時テーブルとして定義し、定着率を求めるためのユーザーアクションフラグとの組み合わせを、CROSS JOINで求めます。そのコード例を下記に示します。
WITH
repeat_interval(index_name, interval_begin_date, interval_end_date) AS (
-- ■ PostgreSQLの場合、VALUES句で一時テーブルを作成できる
-- ■ Hive, Redshift, BigQuery, SparkSQLの場合、SELECT文で代用可能
-- ※3-4-5:擬似的なテーブルを作成する参照
VALUES ('14 day retention', 8, 14)
)
, action_log_with_index_date AS (
-- 略
)
, user_action_flag AS (
-- 略
)
, mst_action_bucket(action, min_count, max_count) AS (
-- アクションの階級マスタ
-- ■ PostgreSQLの場合、VALUES句で一時テーブルを作成できる
-- ■ Hive, Redshift, BigQuery, SparkSQLの場合、SELECT文とUNION ALLで代用可能
VALUES
('comment', 0, 0)
, ('comment', 1, 5)
, ('comment', 6, 10)
, ('comment', 11, 9999) -- 最大値として便宜上9999を入れている
, ('follow' , 0, 0)
, ('follow' , 1, 5)
, ('follow' , 6, 10)
, ('follow' , 11, 9999) -- 最大値として便宜上9999を入れている
)
, mst_user_action_bucket AS (
-- ユーザーマスタとアクション階級マスタの組み合わせを算出
SELECT
u.user_id
, u.register_date
, a.action
, a.min_count
, a.max_count
FROM
mst_users AS u
CROSS JOIN
mst_action_bucket AS a
)
SELECT *
FROM
mst_user_action_bucket
ORDER BY
user_id, action, min_count
;

user_id | register_date | action | min_count | max_count ---------+---------------+---------+-----------+----------- U001 | 2016-01-01 | comment | 0 | 0 U001 | 2016-01-01 | comment | 1 | 5 U001 | 2016-01-01 | comment | 6 | 10 U001 | 2016-01-01 | comment | 11 | 9999 U001 | 2016-01-01 | follow | 0 | 0 U001 | 2016-01-01 | follow | 1 | 5 U001 | 2016-01-01 | follow | 6 | 10 U001 | 2016-01-01 | follow | 11 | 9999 U002 | 2016-01-01 | comment | 0 | 0 …
次のステップ 上記コード例の出力結果に、登録後7日間のログをLEFT JOINし、登録後7日間のアクション度数を集計するクエリを、下記のコード例に示します。
なお、下記のコード例では、登録後7日間のログを結合するため、JOIN句内でBETWEEN句を用いますが、Hiveでは動作しません。別途WHERE句での絞り込みが必要となりますが割愛します。
WITH
repeat_interval AS (
-- 略
)
, action_log_with_index_date AS (
-- 略
)
, user_action_flag AS (
-- 略
)
, mst_action_bucket AS (
-- 略
)
, mst_user_action_bucket AS (
-- 略
)
, register_action_flag AS (
-- 登録日から7日後までのアクション数をカウントし、
-- アクション階級と14日定着の達成フラグを算出する
SELECT
m.user_id
, m.action
, m.min_count
, m.max_count
, COUNT(a.action) AS action_count
, CASE
WHEN COUNT(a.action) BETWEEN m.min_count AND m.max_count THEN 1
ELSE 0
END AS achieve
, index_name
, index_date_action
FROM
mst_user_action_bucket AS m
LEFT JOIN
action_log AS a
ON m.user_id = a.user_id
-- 登録日当日から7日後までのアクションログを結合
-- ■ PostgreSQL, Redshiftの場合は下記
AND CAST(a.stamp AS date)
BETWEEN CAST(m.register_date AS date)
AND CAST(m.register_date AS date) + interval '7 days'
-- ■ BigQueryの場合は下記
-- AND date(timestamp(a.stamp))
-- BETWEEN CAST(m.register_date AS date)
-- AND date_add(CAST(m.register_date AS date), interval 7 day)
-- ■ SparkSQLの場合は下記
-- AND CAST(a.stamp AS date)
-- BETWEEN CAST(m.register_date AS date)
-- AND date_add(CAST(m.register_date AS date), 7)
-- ■ Hiveの場合は、JOIN句でBETWEEN句が使用できないため、WHERE句での絞り込みが必要
AND m.action = a.action
LEFT JOIN
user_action_flag AS f
ON m.user_id = f.user_id
WHERE
f.index_date_action IS NOT NULL
GROUP BY
m.user_id
, m.action
, m.min_count
, m.max_count
, f.index_name
, f.index_date_action
)
SELECT *
FROM
register_action_flag
ORDER BY
user_id, action, min_count
;
-[ RECORD 1 ]-----+----------------- user_id | U001 action | comment min_count | 0 max_count | 0 action_count | 0 achieve | 1 index_name | 14 day retention index_date_action | 1 -[ RECORD 2 ]-----+----------------- user_id | U001 action | comment min_count | 1 max_count | 5 action_count | 0 achieve | 0 index_name | 14 day retention index_date_action | 1 ...
次のステップ 最後に、上記コード例で求めたアクション度数別に、14日定着率を集計します。
WITH
repeat_interval AS (
-- 略
)
, action_log_with_index_date AS (
-- 略
)
, user_action_flag AS (
-- 略
)
, mst_action_bucket AS (
-- 略
)
, mst_user_action_bucket AS (
-- 略
)
, register_action_flag AS (
-- 略
)
SELECT
action
-- ■ PostgreSQL, Redshiftの場合は下記で文字列を連結する
, min_count || ' ~ ' || max_count AS count_range
-- ■ BigQueryの場合は下記で文字列を連結する
-- , CONCAT(CAST(min_count AS string), ' ~ ', CAST(max_count AS string))
-- AS count_range
, SUM(CASE achieve WHEN 1 THEN 1 ELSE 0 END) AS achieve
, index_name
, AVG(CASE achieve WHEN 1 THEN 100.0 * index_date_action END) AS achieve_index_rate
FROM
register_action_flag
GROUP BY
index_name, action, min_count, max_count
ORDER BY
index_name, action, min_count;
action | count_range | achieve | index_name | achieve_index_rate ---------+-------------+---------+------------------+-------------------- comment | 0 ~ 0 | 24 | 14 day retention | 4.1666 comment | 1 ~ 5 | 3 | 14 day retention | 33.3333 comment | 6 ~ 10 | 0 | 14 day retention | comment | 11 ~ 9999 | 0 | 14 day retention | follow | 0 ~ 0 | 25 | 14 day retention | 4.0000 follow | 1 ~ 5 | 2 | 14 day retention | 50.0000 follow | 6 ~ 10 | 0 | 14 day retention | follow | 11 ~ 9999 | 0 | 14 day retention |
本項ではユーザーが行ったアクションに着目して集計していますが、受けたアクション別(いいね、コメント、フォローなど)で集計すると、より活性化させるべきアクションが見えてくるはずです。
Manateeではメルマガ会員を募集中!
