2017.03.22
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第2回 ツイート分析アプリで学ぶ Natural Language API の使い方
連載第2回目では、GCP(Google Cloud Platform)のNatural Language APIを用いた簡易的なツイート分析のWebアプリケーションを紹介しながら、このAPIを利用する方法を解説します。Cloud Natural Language APIは、人間が使う自然言語を対象として構文解析や固有表現抽出などの処理を行う、「自然言語処理」の機能を提供しています。2017年3月現在、英語・日本語・スペイン語の3つの言語に対する各処理がサポートされています。
1.アプリケーションの全体像
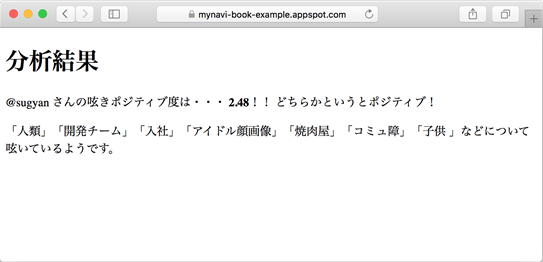
はじめに、サンプルアプリケーションの内容を説明しておきます。今回のアプリケーションは、Twitterのユーザーを指定して(図1)、そのユーザーの最近の呟きがどれくらいポジティブで どんな単語を呟いているのか(図2)、を機械的に傾向分析するものです。この分析のための「感情分析」と「エンティティ分析」の処理に、GCP(Google Cloud Platform)のNatural Language APIを利用しています。

なお、今回このアプリケーションではTwitter API利用のための認証情報はApplication-only authenticationを利用します。実際にアプリケーションを公開する際は、ユーザーごとのOAuth認証を使ってAccess Tokenを取得する、などの実装が必要でしょう。今回の内容はあくまで、APIサービスの利用方法を学ぶためのサンプルとして活用するようにしてください。
また、今回もGCPが提供するGoogle App Engine(GAE)の環境を用いてアプリケーションを実行します。
アプリケーションの全体像は、以下のようになります。
1. 入力された分析対象のユーザー名から直近のTwitterタイムラインを取得し、
2. そのテキストに対しNatural Language APIによってannotation付けを行い、
3. その情報を元に分析結果を作成して、Webページに表示します。
Cloud Datastoreへのデータ保存などは今回は行いません。 またWebアプリケーション全体は、第1回同様PythonのWebフレームワークであるFlaskを利用して作成されています。
2.Twitter API利用のための準備
今回は、Twitterからユーザーの呟き情報を取得して使いますので、そのための準備をします。 まず、API利用のためにTwitter Application Managementのページでアプリケーションを作成します。
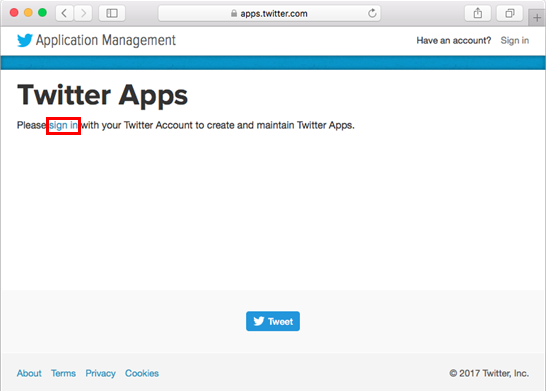
Twitterのアカウントで「Sign in」からログインし、「Create New App」のボタンから必要な項目を入力して新規にアプリケーションを登録します。
作成が済むと、「Keys and Access Tokens」のタブで、そのアプリケーションの「Consumer Key」と「Consumer Secret」を得ることができますので、どこかに保存しておいてください。
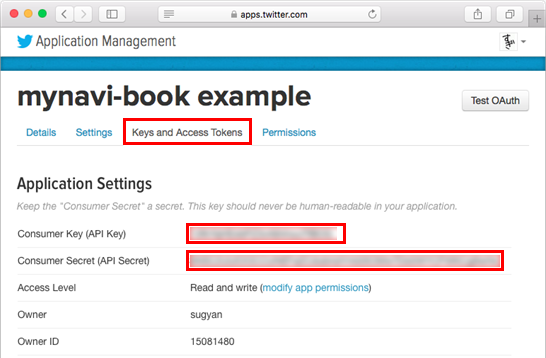
今回は、このアプリケーションのConsumer KeyとConsumer Secretだけを利用する、「Application-only authentication」を用います。 詳細についてはここでは説明しませんが、これを用いることによって、ユーザーごとのOAuth認証でAccess Tokenなどを取得しなくてもTwitter APIを利用することができます。
Application-only authentication — Twitter Developers
また、今回はPythonからTwitter APIを利用するためのライブラリとしてTweepyを使用しています。本記事ではTweepyの詳しい使い方などについては解説しませんが、今回のアプリケーションでは「指定したユーザーのタイムライン直近100件のうち、RetweetやReplyではないもの」を取得し使用したいと思います。コードとしては以下のようになります。
import tweepy
def collect_tweets(target):
auth = tweepy.AppAuthHandler('CONSUMER_KEY', 'CONSUMER_SECRET')
api = tweepy.API(auth)
tweets = []
for status in api.user_timeline(target, include_rts=False, count=100, exclude_replies=True):
tweets.append(status.text)
return '\n'.join(tweets)
3.アプリケーションの利用手順
それでは、実際にアプリケーションをデプロイして、動作確認を行ってみましょう。アプリケーションのコードは、GitHubの以下のリポジトリで公開されています。コードの内容については、この後で改めて説明します。
https://github.com/sugyan/appengine-nlapi-example
はじめに、第0回の「2. アカウントを登録しよう」から「3. プロジェクトを作成しよう」に従って、GCPのアカウント登録を行って新規のプロジェクトを作成しておきます。
続いて同じく第0回の「5. Vision APIで画像認識してみよう」の「[1] APIの有効化」を参考に、Natural Language APIを有効化しておきます。 なお、第1回にも書かれているように、GAEからNatural Language APIを使用する場合、APIキーの作成は不要になりますので、「[2] APIキーの発行」は不要です。
この後は、Cloud Shellのコマンド端末からデプロイ作業を進めます。Google Cloud Platformのコンソール画面の右上にあるボタン( )から、Cloud Shellの端末画面を開きます。
)から、Cloud Shellの端末画面を開きます。
コマンド端末が開いたら、次のコマンドでGitHubからサンプルコードをダウンロードします。1行目の「git」以降を入力して[Enter]キーを押します。
$ git clone https://github.com/sugyan/appengine-nlapi-example.git Cloning into 'appengine-nlapi-example'... ...
次に、ダウンロードしたサンプルコードのディレクトリにカレントディレクトリを変更します。以下の「cd」以降を入力して[Enter]キーを押します。
$ cd appengine-nlapi-example
ここで、カレントディレクトリにある設定ファイルapp.yamlをエディタで開いて、下記の部分を修正します。エディタでの編集については、第1回の「3.アプリケーションの利用手順」のこちらを参照してください。
env_variables: TWITTER_CONSUMER_KEY: 'CONSUMER KEY OF YOUR TWITTER APPLICATION' ←ここを修正 TWITTER_CONSUMER_SECRET: 'CONSUMER SECRET OF YOUR TWITTER APPLICATION' ←ここを修正
Twitter APIを利用するために、前節の準備で取得したConsumer KeyとConsumer Secretの値に書き換えます。
この後は、以下のコマンドを順に実行していきます。 まず、アプリケーションの実行に必要なライブラリ群をディレクトリlibの下にインストールします。以下の「pip」以降を入力して[Enter]キーを押します。
$ pip install -r requirements.txt -t lib
続いて、GAEのアプリケーション環境をセットアップします。 このあたりは第1回のときと同様です。1行目の「gcloud app create」を入力して[Enter]キーを押し、その後表示される選択肢から「asia-northeast1」の番号を入力します。
$ gcloud app create You are creating an app for project [PROJECT ID]. WARNING: Creating an App Engine application for a project is irreversible and the region cannot be changed. More information about regions is at https://cloud.google.com/appengine/docs/locations. Please choose the region where you want your App Engine application located: [1] asia-northeast1 (supports standard and flexible) [2] us-central (supports standard and flexible) [3] europe-west (supports standard) [4] us-east1 (supports standard and flexible) [5] cancel Please enter your numeric choice: 1 ← 1 を選択 ...
Cloud Datastoreは今回のアプリケーションでは利用しませんので、あとはもうデプロイするだけです。1行目の「gcloud app deploy」を入力して[Enter]キーを押し、その後続けるかどうかを確認されるので「Y」を入力します。
$ gcloud app deploy
You are about to deploy the following services:
- [PROJECT ID]/default/20170213t161504 (from [/home/[USER]/[PROJECT NAME]/app.yaml])
Deploying to URL: [https://[PROJECT ID].appspot.com]
Do you want to continue (Y/n)? Y ← Y を入力
...
上記の https://[PROJECT ID].appspot.com の部分に表示されたURLから、デプロイしたアプリケーションにアクセスすることができます。 フォームに自分や友人のTwitter ID(screen_name)を入力して、どのような分析結果が出るか試してみましょう。
4.google-cloudライブラリを用いたAPIサービスの利用方法
ここからは、今回のサンプルアプリケーションのプログラムコードについての説明です。 上で紹介した https://github.com/sugyan/appengine-nlapi-example を参照しながら説明を読むとよいでしょう。
このサンプルアプリケーションでは、google-cloud-languageライブラリを用いてNatural Language APIに対するアクセスを行っています。 これは、PythonのプログラムコードからNatural Language APIを呼び出すためのクライアントライブラリになります。 下記の公式Webサイトにある「Read the Docs」のリンクから、詳細なドキュメント参照することができます。
[google-cloudライブラリの公式Webサイト]
(https://googlecloudplatform.github.io/google-cloud-python/)
今回のアプリケーションコードの中では、設定ファイルrequirements.txtの以下の行(4行目)でライブラリのインストールが指示されており、これによってGAEの環境内でgoogle-cloud-languageライブラリが利用可能になります。
google-cloud-language==0.23.1
アプリケーションのメインとなるコードmain.pyでは、冒頭の下記の部分(9行目)で、このライブラリからNatural Language APIを使用するためのモジュールをインポートしています。
from google.cloud import language
そして、実際にNatural Language APIを用いて分析を行う関数は次になります(28~43行目)。
def process(text):
language_client = language.Client()
document = language_client.document_from_text(text)
annotated = document.annotate_text(include_syntax=False)
# calculate total score
total_score = 0.0
for sentence in annotated.sentences:
total_score += sentence.sentiment.magnitude * sentence.sentiment.score
# extract entities
entities = set()
for entity in annotated.entities:
if entity.entity_type not in [EntityType.OTHER, EntityType.UNKNOWN]:
entities.add(entity.name)
return total_score, entities
まず、29行目ではNatural Language APIを利用するためのクライアントオブジェクトを取得しています。 通常はAPIを利用するための認証設定が必要になりますが、GAEの環境では認証処理は自動で行われるので特別な設定は不要です。
その後、30行目で分析の対象とするテキスト文字列を指定し、最後に31行目のannotate_textメソッドで実際のラベルの分析結果を取得します。
現在Natural Language APIでは、analyze_entities(エンティティ分析)、analyze_sentiment(感情分析)、 analyze_syntax(構文解析)の3つの分析が可能です。 それぞれ別々に呼び出して使うこともできますが、同一の文書に対して複数の分析を行う場合は、それらの3つを統合したannotate_textを使うと便利でしょう。
今回のサンプルの場合は、構文解析は行いませんので、オプション指定(include_syntax=False)により構文解析の結果は得ないようにしています。
このannotate_textの応答から、以下のように感情分析のスコアを使ってポジティブ度を算出します。
total_score = 0.0
for sentence in annotated.sentences:
total_score += sentence.sentiment.magnitude * sentence.sentiment.score
annotated.sentencesは、感情分析の結果として一文ごとに分割され、それぞれの文に対しscoreとmagnitudeの値が付与されてきます。これがそれぞれ「感情」と「重要度」を示し、scoreは-1.0に近ければよりネガティブ、1.0に近ければよりポジティブということになります。
ここではそれぞれを掛け合わせた値の総和、を全体のポジティブ度として分析結果で使用しています。 重要度は無視して単純に「ポジティブ判定された文の割合を使う」など、ロジックを変えることで分析手法を変化させることもできそうです。 色々と試してみると良いでしょう。
次に、以下のコードで、エンティティ分析の結果を使って言及しているエンティティを抽出します。 エンティティ分析では、テキスト内のエンティティ(著名人、ランドマーク、日常的な物など、名前が付けられている「モノ」)に関する情報が抽出されます。
entities = set()
for entity in annotated.entities:
if entity.entity_type not in [EntityType.OTHER, EntityType.UNKNOWN]:
entities.add(entity.name)
annotated.entitiesにはエンティティ分析の結果としてiterableなentityオブジェクトが含まれてきますので、ここではentity_typeがOTHER, UNKNOWNのものを除外します。
entity_typeにはPERSON、EVENTなどがあります。詳しくは 公式ドキュメント を参照してください。 また、別文章から同一のエンティティが抽出されて重複することもありますので、ここではsetを使ってユニークに取得するようにしています。
最後に、それらの結果を使って分析結果のページで表示するコメントやエンティティ例を生成します(53~61行目)。
total_score, entities = process(text)
comment = 'ポジティブ!' if total_score > 0.0 else 'ネガティブ!'
if abs(total_score) > 10.0:
comment = 'とっても' + comment
elif abs(total_score) > 5.0:
comment = 'かなり' + comment
else:
comment = 'どちらかというと' + comment
samples = random.sample(entities, min(7, len(entities)))
scoreはポジティブなものが正、ネガティブなものが負、の値を持ちます。 従って、総和で計算したtotal_scoreに対しても「0より大きければポジティブ、小さければネガティブ」で決定できます。 どちらの場合でも、total_scoreの絶対値が大きければその傾向の強さを表せそうなので、大きさに応じて程度を表すコメントを付与してみました。
あとは「どんな単語を呟いているか」ということで、抽出されたエンティティからランダムに選択しています。 すべてを表示するとかなりの量になることもあるので、最大でも7つ程度までを選択、としています。
このように、google-cloud-languageライブラリを使用してPythonのプログラムコードから簡単にAPIを利用することができます。 Natural Language APIでは今回は使用しなかった構文解析の機能もあり、これを使って例えば「動詞の前に特定の語句を挿入してテキストを改変する」アプリケーションなども作ることができますね。
オリジナルのアプリケーションを作成する際は、公式ドキュメント「Using the API」も参考にするとよいでしょう。
5.分析結果の考察
色々なTwitterユーザーを指定して分析して試してみると、エンティティ分析によって取得されるエンティティがうまく切り出せていない場合が多いことに気付くでしょう。
Twitterのような不特定多数のユーザーが自由にテキストを投稿できるマイクロブログサービスなどでは、砕けた表現やネットスラングなど 独特の言い回しや特殊な固有名詞などが使われることが多くあります。 そういった文章は解析器が対応していないと正しく構文解析ができません。 このあたりは自然言語処理の難しさ・奥深さですね。 そういったものに対しても今後Natural Language APIが徐々に対応できるようになってくるかもしれませんが、自分で特化した解析器を作って用意する必要が出てくることもあるかもしれません。 どんなことを実現したいか、どの程度の精度が求められるか。必要となる自然言語処理の要件は、作ろうとするアプリケーションよって様々です。
6.後片付け
サンプルアプリケーションの動作確認ができたら、公開中のアプリケーションは停止しておきましょう。 第1回の「5.後片付け」と同じ内容になりますが、アプリケーションを停止するには、コンソール画面の「App Engine」→「設定」メニューから表示される画面で、「アプリケーションを無効にする」ボタンを押します。アプリケーションID(プロジェクトID)の入力を求められるので、該当のIDを入力すると停止処理が行われます。
【編集部注】この記事は、執筆時の2017年3月現在の情報に基づくものです。記事公開後、サービス内容や画面などに変更が発生する可能性がありますのでご注意ください。
Manateeではメルマガ会員を募集中!
