2017.04.03
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第3回 Natural Language API で質問応答システムに挑戦
連載第3回目では、第2回目に続いて、Natural Language APIを使います。WikipediaのAPIと組み合わせて、質問文を元に検索を行い、その結果を返すシステムを作ってみましょう。
はじめに
今回はNatural Language APIの少しひねった使い方に挑戦してみましょう。
お題は「日本の首都はどこですか?」と話しかけたら「東京です」と返してくれるような質問応答システムです(ただし、この作例では回答候補とスコアを返すという形で結果を表示します)。
さすがにGoogleアシスタントのような高性能なものが簡単に作れるとまではいきませんが、Natural Language APIを工夫して使う例としては悪くないかと思います。
一見するとNatural Language APIの機能だけでは実現できなさそうなシステムを、どうやって作っていくのか。
その過程を通して皆さんに機械学習の面白さを少しでも伝えることができれば幸いです。
また、本記事で使用するサンプルアプリケーションはGitHub上で公開しています。
アイデアをまとめよう
質問応答システムの作り方は色々とあるかと思いますが、今回は次のような仕組みで作ることにしましょう。
1. 入力された質問文から検索に使えそうなキーワードを抽出
2. 抽出したキーワードを使ってWikipediaを検索し、最初にヒットした記事を持ってくる
3. 入力された質問文から何について訊かれているかを推定
※今回はLOCATIONとPERSONの2種類のカテゴリを用意して、「~はどこですか?」などの場所を尋ねる質問はLOCATION、「~は誰ですか?」などの人名を尋ねる質問はPERSONと分類します。
4. Wikipedia記事からLOCATIONやPERSONなど推定したカテゴリの単語を回答候補として抽出
5. 抽出した回答候補に対して何らかの基準でスコアをつけて、高いものを回答として返す
実際に人が調べ物をする手順と何となく似ていますね。
文章では少し分かりにくいので、具体例を図1に用意しました。
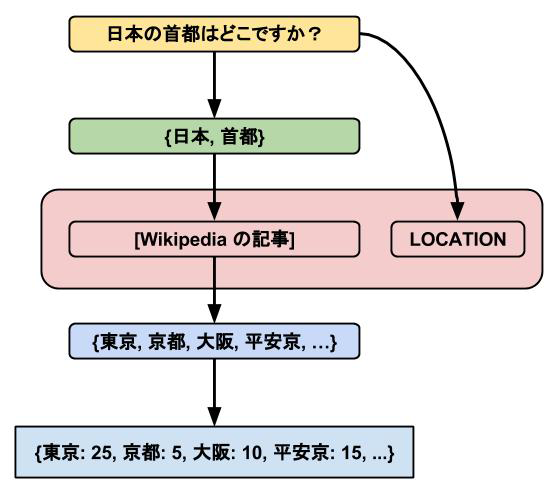
ここからは、上記の処理を行うためにNatural Language APIをどう活用できるのかを見ていきましょう。
また、今回はWikipediaの記事の多さや処理の簡単さを考慮して、英語の質問文に対して英語のWikipediaから回答候補を探しています。
それ以外の言語で質問された場合については、最後にTranslation APIを使って対応します。
Step 1:検索に使えそうなキーワードの抽出
Natural Language APIのEntity Recognitionという機能を使うと、{UNKNOWN, PERSON, LOCATION, ORGANIZATION, EVENT, WORK_OF_ART, CONSUMER_GOOD, OTHER}のうちいずれかに該当する主要な単語を抽出することができます。
今回は抽出された単語をすべて検索に使うことにしましょう。
Entity Recognitionの処理はgoogle-cloudライブラリを使うと次のように書くことができます。
def extract_entities(text): nl_client = language.Client() document = nl_client.document_from_text(text) entities = document.analyze_entities() return entitiesentity_response = extract_entities(question)# 抽出した entity から単語だけを取得query_words = [entity.name for entity in entity_response.entities] |
単語を抽出するだけでなく、その単語の重要度のスコアや、固有名詞と一般名詞どちらなのかなど様々な情報を返してくれるので、工夫次第で色々な用途が考えられる面白い機能です。
詳細な機能については公式ドキュメントを参照してみてください。
Step 2:Wikipediaの検索
WikipediaのAPIの使い方については本記事では割愛しますが、サンプルアプリケーションではStep 1で抽出した単語で検索して先頭の記事を取り出すという単純な使い方をしています。
Step 3:何について訊かれているか推定
今回はこの部分で楽をするために、対象言語を英語に限定しました。
次のように、whoが含まれていたらPERSON、whereが含まれていたらLOCATION、それ以外の質問にはOTHERを返します。
# 質問文を受け取ったら {PERSON, LOCATION, OTHER} のいずれかを返す関数def classify_question(question): if "who" in question.lower(): return "PERSON" elif "where" in question.lower(): return "LOCATION" else: return "OTHER" |
大文字と小文字の区別を無くすために、質問文をすべて小文字に変換してから判定をしています。
Step 4:回答候補の抽出
ここはまさにNatural Language APIのEntity Recognition機能がぴったりはまる部分です。
検索したWikipedia記事をEntity Recognition機能にかけて、Step 3で推定したカテゴリに該当する単語を抽出します。
Step 5:回答候補の採点
正解となる単語の周辺には検索語が多く出現しているということが経験的に知られています。
そこで、「回答候補と同じ文に、検索で使った単語がどれくらい出現しているか」で採点をすることにします。
実は英語の場合、「.」が文の区切り以外でも使われるので(Google Inc. など)、文字列を一文ごとに分けるのは簡単ではありませんが、そこはNatural Language APIの機能を使いました。
Sentiment AnalysisかSyntax Analysisのうちどちらかの機能を使うと、文字列を一文ごとに区切った結果を得ることができます。
Sentiment Analysisは一文ごとの感情分析、Syntax Analysisは構文解析をしてくれる機能です。
Syntax Analysisは返ってくる情報量が多すぎてメモリを消費してしまうので、今回はSentiment Analysisを使いました。
日本語を含む多言語への対応
ここまで質問文が英語で入力される前提で考えていましたが、Translation APIを使えば簡単に多言語対応させることができます。
Translation APIは元の言語が何かを自動で判定してくれます。
ですから、次のように質問文を英語に翻訳して欲しいということだけ記述しておけば、質問文がどんな言語で入力されても対応することができます。
from google.cloud import translatedef translate_text_to_english(text): translate_client = translate.Client() # target_language だけを指定しておけば元の文は何語でも OK result = translate_client.translate(text, target_language="en") return result["translatedText"] |
サンプルアプリケーションの解説
上記の手順で作成したサンプルコードをGitHub上に用意しておきましたので、早速実際に動かしてみましょう。
1. アプリケーションをデプロイしよう
第0回の記事を参考に、Google Cloud Platformのコンソールでプロジェクトを作成し、Natural Language APIとTranslation APIの有効化を忘れずに行っておいてください。
そして、 Cloud Shellの端末画面を開き、次のコマンドを打ち込んでください。
# リポジトリのダウンロードcd qa-system-sample# 必要なライブラリのインストールpip install -r requirements.txt -t lib |
最後にApp Engineにデプロイをして作業は完了です。
gcloud app create |
コマンドの後にregionを尋ねられるのでお好きなものを選択してください。
gcloud app deploy |
の後に表示される選択肢で「Y」と入力するとデプロイの処理が始まります。
# Google App Engineへデプロイgcloud app creategcloud app deploy |
2. 動作画面を確認しよう
デプロイしたアプリケーションのトップページは https://{your-project-id}.appspot.com です。
Cloud Shell上で次のコマンドを入力するとURLを表示することができます。
# デプロイしたアプリケーションのトップページのURLを表示gcloud app browse |
トップページへアクセスすると図2のような質問入力画面が表示されます。
最初はデフォルトで「日本の首都はどこですか?」という質問が入力されているはずです。
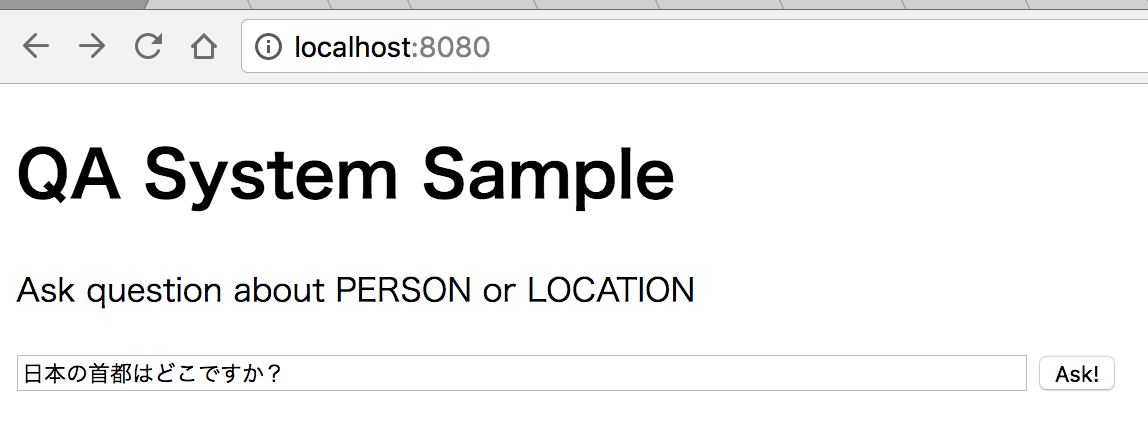
質問文を入力して「Ask!」と書かれたボタンを押してしばらくすると、図3のような結果表示画面へ移動します。
Candidates and Scoresのところに回答候補とスコアが表示されています。すべての候補を表示すると多すぎるので、上位5件だけを表示しています。Tokyoが最もが高いので、正しく答えられていますね。

他にも色々な質問を入力して試してみてください。
「GoogleのCEOは誰ですか?」など人名を答える質問にも対応しています。
簡単な仕組みなので上手く答えられないことも多いですが、途中の経過も詳しく表示しているので、どこで失敗してしまったかを観察してみるのも面白いと思います。
例えば検索したWikipediaの記事がそもそも見当違いなものであった場合は、検索に使うキーワードの抽出部分を変えれば良いなど、改良の方針を立てることができます。
おわりに
今回作った質問応答システムの精度はまだまだといったところですが、機械学習のAPIサービスを使えば工夫次第で色々なものを作れるという面白さが伝わっていると嬉しいです。
APIサービスはできることに限りがあります。
しかし、Googleが提供する高精度なモデルを使って、データ収集やアルゴリズムなど機械学習の大変な部分を全部飛ばしてアイデアで勝負できるのが素晴らしいところです。
逆に、APIサービスだけで完結させるために簡略化した部分はTensorFlowなどを使って本格的に作り込むことで、まだまだ改善ができるでしょう。
また、「日本の首都はどこですか?」という質問の回答候補に「Japan」など明らかに間違っている単語が混ざっているので、そういったものを排除するようなルールを人手で記述することでも精度を上げることができます。
皆さんも工夫を凝らして面白いアプリケーション作成に挑戦してみてください。

