2018.03.27
作りながら学ぶ強化学習 -初歩からPyTorchによる深層強化学習まで
第14回 深層強化学習DQN(Deep Q-Network)の解説
SEやプログラマ、エンジニア、一般の方を対象に、少しずつ実際にプログラムを作りながら、強化学習および深層強化学習について解説していきます。
本連載をまとめ、さらに多くの記事を追加した書籍『つくりながら学ぶ!深層強化学習』を2018年7月に発売しました!

(上の書籍画像をクリックすると購入サイトに移動できます)
はじめに
前回は、PyTorchを用いてディープラーニングを実装する手法を解説しました。今回は強化学習にディープラーニングを適用する 深層強化学習 について解説します。深層強化学習のなかでも、最も基本的な手法である DQN(Deep Q-Network)について解説します。
表形式の強化学習が持つ問題点
強化学習にディープラーニングを適用すると言われても、始めはピンとこないかと思います。まずはこれまで実装してきた表形式の強化学習を振り返りましょう。対象とするアルゴリズムはQ学習です。
表形式のQ学習アルゴリズムでは、エージェントの状態に対応する行番号と、エージェントの行動に対応する列番号のセルに「行動価値Q(st,at)の値」が格納されていました。
エージェントの状態とは、迷路の場合には自分がいるマスの位置を示し、倒立振子課題CartPoleの場合は4つの変数をそれぞれ6分割に離散化して6進数に変換した値を示していました。行動価値Q(st, at)とは、時刻tで状態stであったとき、at の行動を採用した場合にその後得られるであろう時間割引報酬の総和を示していました。
表形式のQ学習の問題点は、状態変数の種類が多くなったり、各変数を細かく離散化すると表の行数がとても多くなることです。例えば状態を画像で取得すると状態変数は各ピクセルに対応するため、莫大な数の状態変数になります。行数が多い表形式できちんと強化学習するには、非常にたくさんの試行数を必要とします。これを表形式で強化学習させるのは現実的ではありません。
このように「状態が多くなると表形式の強化学習が困難である」という問題点を、ディープラーニングを用いて解決したいと思います。
強化学習とディープラーニングを組み合わせる
そこで、表形式で行動価値関数を表現することを止め、ディープラーニングで行動価値関数を表現することとします。
つまりニューラルネットワークへの入力は各状態変数の値となります。よってニューラルネットワークの入力層の素子の数は、状態変数の数と同じになります。例えばCartPoleであれば、位置、速度、角度、角速度の4変数だったので、入力素子は4つです。なお離散化は不要となります。出力層の素子の数は、行動の数となります。例えばCartPoleであれば、右に押すと左に押すの2種類だったので出力素子の数は2つです。
出力層の素子が出力する値は、行動価値関数Q(st, at)の値です。つまり、その素子に対応する行動を採用した場合にその後得られるであろう時間割引報酬の総和を出力します。出力層の各素子が出力する値を比較し、一番大きな値を出す素子に対応する行動を採用します。
続いて理解するべき点は、このような行動価値関数を出力する素子間の結合パラメータをどう学習させるのかです。言いかえると、どのような誤差関数を設定してバックプロパゲーションさせてあげれば良いのかとなります。ここでQ学習を使用します。
Q学習の場合、行動価値関数Qの更新式は
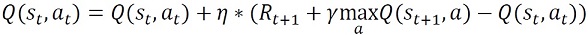
で表されたことを思い出してください。
これは最終的に以下の式で表される関係が成り立って欲しいからでした。
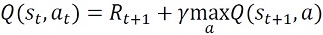
よって、例えば時刻tで状態s2であった場合に行動a1を採用したとすると、出力層の素子が出力する値はQ(s2, a1)であり、この出力値がRt+1 + ηmaxa Q(st+1,a)と近くなるようにします。単純にはこの2つの差の二乗を誤差関数Eとしてあげれば良いです。 つまり、

です。ただし、状態st+1は、実際にstから行動atを実施してみて求めます。この点は前回までの表形式と同じです。maxa Q(st+1, a)の値はニューラルネットワークに状態st+1を入力して求めてあげます。
以上の手続きが、強化学習の行動価値関数の表現にディープラーニングを用いる基本的な手法であり「DQN(Deep Q-Network)」と呼ばれます。以上を図で表すと、次の図14.1となります。
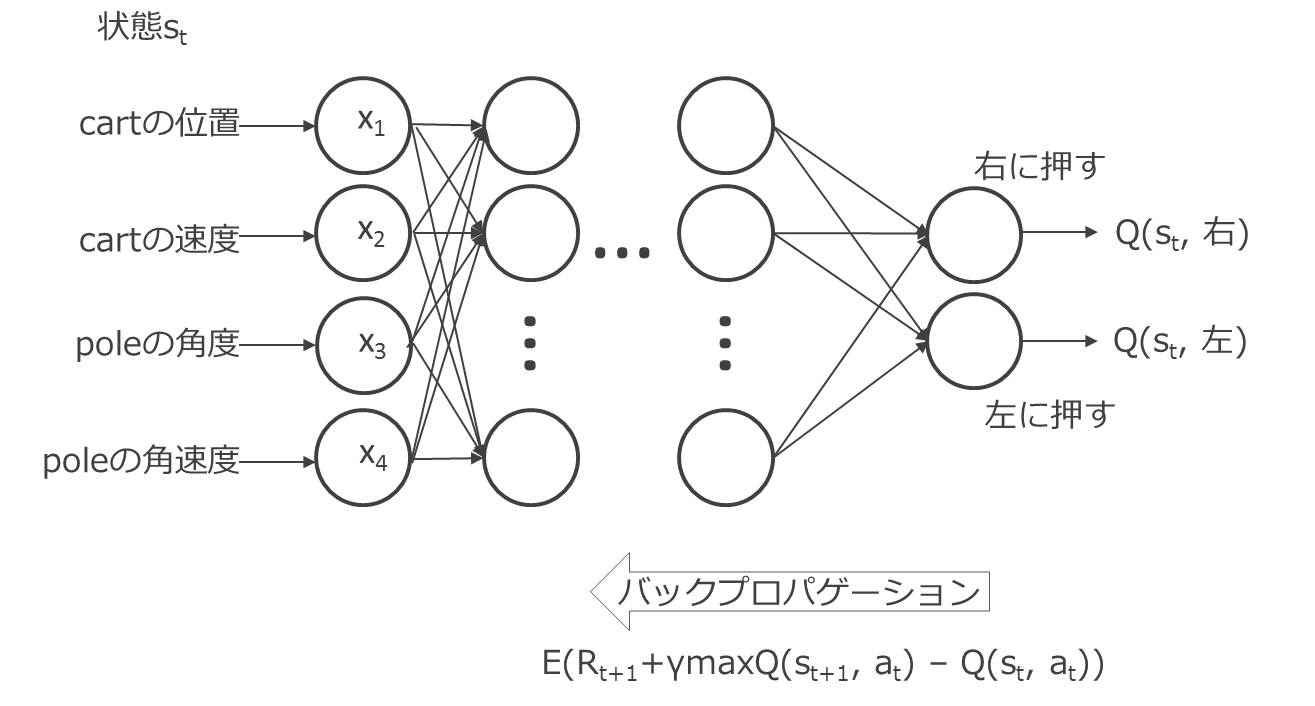
図14.1 倒立振子CartPole課題におけるDQN
DQN実装時の4つの工夫
最後に、DQNを実装する際の注意点を紹介します。安定した学習を実現させるために、DQNの実装には4つの工夫が必要となります[1]。
1つ目の工夫は Experience Replay と呼ばれる手法です。これは従来のQ学習のように1ステップごとにそのステップの内容(experience)を学習するのではなく、メモリに各ステップの内容を保存しておき、メモリから内容をランダムに取り出して(replay)、ニューラルネットワークに学習させる方法です。
各ステップごとにそのステップの内容を学習すると、時間的に相関が高い内容(つまり時刻tの学習内容と時刻t+1の学習内容はとても似ている)をニューラルネットワークが学習するので、学習が安定しづらいという問題が発生します。Experience Replayはこの問題を解決する工夫となります。
2つ目の工夫は Fixed Target Q-Network と呼ばれる手法です。ニューラルネットワークは主となるmain-networkとは別に、誤差関数で使用する行動価値を求めるtarget-networkを用意します。そしてQ学習で使用するmaxa Q(st+1, a)の値はtarget-networkから求めます。このtarget-networkは少し前の時間のmain-networkを使用するようにします。
ニューラルネットワークの学習に、そのニューラルネットワークの出力を使用すると学習が安定しづらいという問題が発生します。Fixed Target Q-Networkはこの問題を解決する工夫となります。Fixed Target Q-Networkはミニバッチ学習を行うことで実装することができます。
3つ目の工夫は 報酬のclipping です。これは各ステップで得られる報酬を-1, 0, 1のいずれかに固定しておく方法です。こうすることで、ゲーム内容(学習対象)によらず、同じハイパーパラメータでディープラーニングを実行しやすいというメリットがあります。
4つ目の工夫は誤差関数を二乗誤差ではなく Huber関数 を使用する手法です。Huber関数は以下の図14.2に示すように誤差が-1~1の間は二乗誤差の値となり、-1より小さいときや1より大きいときには誤差の絶対値をとる関数です。
誤差が大きい場合に二乗誤差を使用すると、誤差関数の出力が大きくなりすぎて学習が安定しづらいという問題が発生します。Huber関数はこの問題を解決する工夫となります。
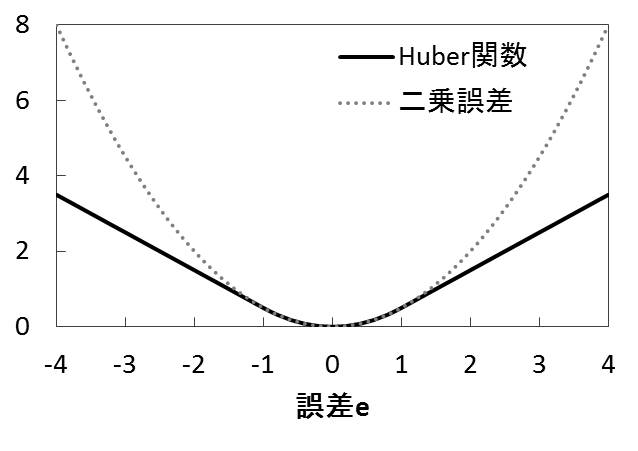
図14.2 Huber関数
以上の4点がDQN実装時の工夫点となります。
まとめ
今回は強化学習にディープラーニングを適用した深層強化学習、そのなかでも最も基本的な手法であるDQNについて解説しました。次回は最終記事となり、CartPole課題に対してDQNを実装する手法を解説します。
引用
[1] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.
Manateeではメルマガ会員を募集中!


