2018.03.20
作りながら学ぶ強化学習 -初歩からPyTorchによる深層強化学習まで
第13回 PyTorchによるディープラーニング実装入門(2)
SEやプログラマ、エンジニア、一般の方を対象に、少しずつ実際にプログラムを作りながら、強化学習および深層強化学習について解説していきます。
本連載をまとめ、さらに多くの記事を追加した書籍『つくりながら学ぶ!深層強化学習』を2018年7月に発売しました!

(上の書籍画像をクリックすると購入サイトに移動できます)
前回に引き続き、実際にディープラーニングの実装を解説します。PyTorchと呼ばれるライブラリを使⽤し、⼿書き数字の画像データ(MNIST)の分類を実⾏します。
2. DataLoderの作成
続いて正規化したMNISTデータをPyTorchのニューラルネットワークで扱えるDataLoaderという変数へと変換します。
DataLoaderへの変換は以下の4つの手続きからなります。
2.1. 訓練データとテストデータに分離
2.2. NumPyデータをTensorに変換
2.3. Datasetの作成
2.4. DatasetをDataLoderに変換
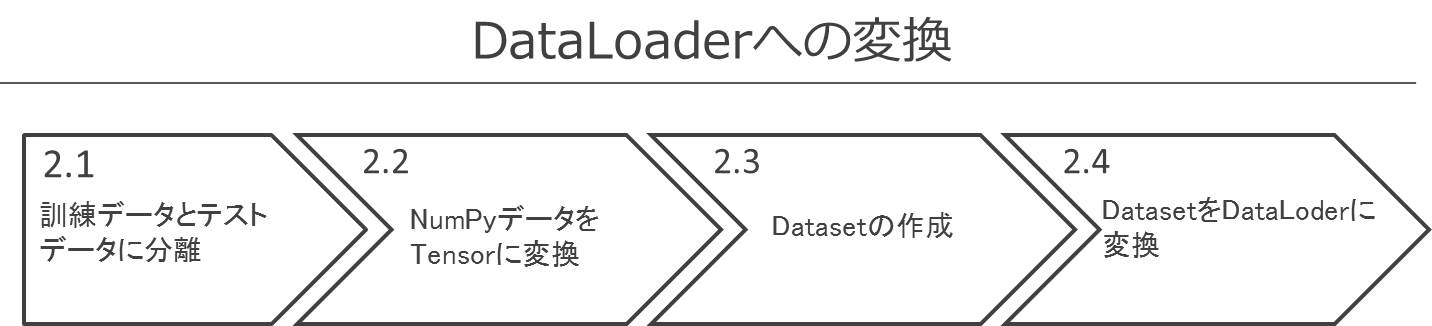
図12.4 DataLoderへの変換フロー
この変換部分のコードは以下の通りとなります。
# 2. DataLoderの作成
import torch
from torch.utils.data import TensorDataset, DataLoader
# 2.1 データを訓練とテストに分割(6:1)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=1/7, random_state=0)
# 2.2 データをPyTorchのTensorに変換
X_train = torch.Tensor(X_train)
X_test = torch.Tensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)
# 2.3 データとラベルをセットにしたDatasetを作成
ds_train = TensorDataset(X_train, y_train)
ds_test = TensorDataset(X_test, y_test)
# 2.4 データセットのミニバッチサイズを指定した、Dataloaderを作成
# Chainerのiterators.SerialIteratorと似ている
loader_train = DataLoader(ds_train, batch_size=64, shuffle=True)
loader_test = DataLoader(ds_test, batch_size=, shuffle=False)
2.1の訓練データとテストデータへの分割はscikit-learnのtrain_test_split関数を用いて行います。今回はデータを訓練データ6万件とテストデータ1万件に分割しています。
2.2ではNumpyデータをPytorchで扱える型の変数に変換します。torch.Tensorと呼ばれるPyTorch版のNumPyに変換します。ラベルのような整数データの場合はtorch.LongTensorを使用します。Tensor(テンソル)という言葉が聞きなれないですが、難しい概念ではありません。数値が1つだけの場合はスカラー、数値が1次元に並んでいるものはベクトル、2次元に並んでいるものは行列と呼ばれます。こうした多次元の数値表現のことをテンソルと呼びます(数学的には厳密な定義がありますが今回は気にする必要はありません)。
2.3ではTensorに変換された画像データとラベルデータをTensorDatasetで一組にしています。データのセットなので画像とラベルを組にしたものとなります。訓練データとテストデータでそれぞれ作成します。
2.4ではTensorDatasetを学習と推論がしやすいようにDataLoaderと呼ばれる形式に変換しています。DataLoaderではバッチサイズを指定します。バッチサイズとは、ニューラルネットワークの結合パラメータを学習する際に一度に使用するデータの数を決めます。データ全部を使用する方法をバッチ学習、一部を使用する方法をミニバッチ学習、データを1つずつ使用する方法をオンライン学習と呼びます。ミニバッチ学習を使用することが一般的です。テストデータはミニバッチにする必要はなさそうですが、データがたくさんあった場合に分散処理しやすいようにこちらもミニバッチにすることが多いです。さらにDataLoaderではデータをシャッフルするかどうか設定します。現在のDatasetは0-9まできれいに並んで格納されているのですが、訓練データに対してランダムな順番で学習を実行したいです。そこで訓練データのDataLoaderはデータをシャッフルさせます。テストデータは正答率を求めるだけなので、シャッフルの必要はありません。
※Chainerでは、iterators.SerialIterator()でデータをまとめていましたが、PyTorchではDataLoaderを使用します。
3. ネットワークの構築
続いて使用するニューラルネットワークを規定します。ここでは一番簡単な書き方を紹介します。これはTensorFlowとKerasライブラリを使用して書く方法と同じ書き方で、Define and Run形式の書き方となります。本記事の最後ではDefine by Run形式の書き方を紹介します。
# 3. ネットワークの構築
# Keras風の書き方 Define and Run
from torch import nn
model = nn.Sequential()
model.add_module('fc1', nn.Linear(28*28, 100))
model.add_module('relu1', nn.ReLU())
model.add_module('fc2', nn.Linear(100, 100))
model.add_module('relu2', nn.ReLU())
model.add_module('fc3', nn.Linear(100, 10))
print(model)
fc1は、28*28=784の入力を持ち、それを100個のニューロンに出力する層です。入力の784素子と、出力の100素子はすべて結合しています(Fully Connected層と呼びます)。relu1は、fc1の100個のニューロンの出力をReLUによって変換します。ReLUは入力が負のときは0を、正のときはそのまま入力を出力するユニットです。同様に、100個の入出力から成るニューロン層fc2を加え、relu2でReLUで変換します。そして最後にfc3で0-9のラベルに対応する10個のニューロンに出力を与えます。各層のニューロンの数、例えば100であったり、層の数は試行錯誤しながら決めることになります。今回の構築したネットワークですと、入力層、中間層fc1、中間層fc2、中間層fc3、出力層というディープニューラルネットワークを構築しています。
4. 誤差関数と最適化手法の設定
続いて、ネットワークの誤差関数と学習の手法を設定します。
誤差関数とはニューラルネットワークの出力と実際の正解である望ましい出力との誤差をどのような関数で計算するのかを決めます。今回のような分類問題では誤差関数にはクロスエントロピー誤差を使用します。
最適化手法とはニューラルネットワークの結合パラメータをどのような手法で更新学習するのかを決めます。今回は勾配法のなかでもAdamと呼ばれるアルゴリズムを使用するように設定します。以下のコード内のlrは学習率を示します。
# 4. 誤差関数と最適化手法の設定 from torch import optim # 誤差関数の設定 loss_fn = nn.CrossEntropyLoss() # 変数名にはcriterionも使われる # 重みを学習する際の最適化手法の選択 optimizer = optim.Adam(model.parameters(), lr=0.01)
5. 学習と推論の設定
続いて、学習と推論での動作を設定します。学習時と推論時の動作をそれぞれ設定します。
学習では訓練データを入力して出力を求めます。その後、出力と正解との誤差を誤差関数に従って計算し、誤差をバックプロパゲーションして、最後に結合パラメータを更新学習させます。
推論ではテストデータを入力して出力を求め、実際の正解と一致した割合を求めます。
注意点がいくつかあります。まず学習時にはmodel.train()を実行し、ネットワークを学習モードにします。推論時にはmodel.eval()を実行して、推論モードに切り替えます。これは今回のネットワークでは関係ないのですが、ドロップアウトやBatch Normalization(バッチノーマライゼーション)といった手法を使用した場合に重要となります。さらに、ニューラルネットワークに入力する前にデータをVariable()で変換します。PyTorchではこのVariable関数を使用することで、変数を微分可能なものに変換します。また学習時にはoptimizer.zero_grad()で毎回バックプロパゲーションの初期値をリセットしてあげます。
関数trainとtestの引数であるepochとはデータを一通り使用する1試行のことを意味します。ミニバッチ学習なので、1epochの間に少しずつデータを使用して学習を進め、全データを一通り使用したら1epoch終了となります。ディープラーニングをきちんと行う場合には、1epochごとに学習と推論時の誤差関数の値を出力・保存し、学習の進捗状況を確認することになります。今回はミニマムバージョンなので、この部分は省略しています。また学習過程を可視化するのにTensorFlowのTensorBoardをwrapしたtensorboardXというライブラリもあります。
※Chainerでは学習と推論の設定に学習はtraining.Trainer()を、推論はtrainer.extend(extensions.Evaluator())を使用して設定できましたが、PyTorchでは自分で書きます。
# 5. 学習と推論の設定
# 5-1. 学習1回でやることを定義します
# Chainerのtraining.Trainer()に対応するものはない
from torch.autograd import Variable
def train(epoch):
model.train() # ネットワークを学習モードに切り替える
# データローダーから1ミニバッチずつ取り出して計算する
for data, target in loader_train:
data, target = Variable(data), Variable(target) # 微分可能に変換
optimizer.zero_grad() # 一度計算された勾配結果を0にリセット
output = model(data) # 入力dataをinputし、出力を求める
loss = loss_fn(output, target) # 出力と訓練データの正解との誤差を求める
loss.backward() # 誤差のバックプロパゲーションを求める
optimizer.step() # バックプロパゲーションの値で重みを更新する
print("epoch{}:終了\n".format(epoch))
# 5. 学習と推論の設定
# 5-2. 推論1回でやることを定義します
# Chainerのtrainer.extend(extensions.Evaluator())に対応するものはない
def test():
model.eval() # ネットワークを推論モードに切り替える
correct = 0
# データローダーから1ミニバッチずつ取り出して計算する
for data, target in loader_test:
data, target = Variable(data), Variable(target) # 微分可能に変換
output = model(data) # 入力dataをinputし、出力を求める
# 推論する
pred = output.data.max(1, keepdim=True)[1] # 出力ラベルを求める
correct += pred.eq(target.data.view_as(pred)).sum() # 正解と一緒だったらカウントアップ
# 正解率を出力
data_num = len(loader_test.dataset) # データの総数
print('\nテストデータの正解率: {}/{} ({:.0f}%)\n'.format(correct,
data_num, 100. * correct / data_num))
6. 学習と推論の実行
最後にネットワークの結合パラメータの学習と、学習後にテストデータで精度を求めます。ですがその前に、学習せずにテストデータを推論をしてみましょう。以下のコードを実行してください。
# 学習なしにテストデータで推論してみよう test()
上記セルを実行すると、
テストデータの正解率: 1051/10000 (11%)
など、およそ10%程度の正解率が出力されます。まだネットワークが学習しておらず、数字が10種類あるのでランダムに選んだ場合とほぼ同じ結果です。
続いて、ニューラルネットワークの結合パラメータを学習させ、再度テストデータで推論してみましょう。今回は6万件の訓練データに対して3epoch学習させます。
# 6. 学習と推論の実行
for epoch in range(3):
train(epoch)
test()
すると、以下のような出力が得られます。
epoch0:終了 epoch1:終了 epoch2:終了 テストセットの正解率: 9616/10000 (96%)
学習後には正答率がおよそ95%程度となり、手書き数字をおおよそ正しく識別できるようになりました。
特定の画像データを推論したい場合は以下のような実装します。なお推論用に作成した関数test()では、出力ラベルを求める際に、pred = output.data.max(1, keepdim=True)[1]としていましたが、今回はpred = output.data.max(0, keepdim=True)[1] と、引数の1が0に変わっています。これはtest()は複数の画像からなるミニバッチを推論していたのに対して、以下のセルでは1つの画像を推論しているからです。
# 例えば2018番目の画像データを推論してみる
index = 2018
model.eval() # ネットワークを推論モードに切り替える
data = Variable(X_test[index])
output = model(data) # 入力dataをinputし、出力を求める
pred = output.data.max(0, keepdim=True)[1] # 出力ラベルを求める
print("予測結果は{}".format(pred))
X_test_show = (X_test[index]).numpy()
plt.imshow(X_test_show.reshape(28, 28), cmap='gray')
print("この画像データの正解ラベルは{:.0f}です".format(y_test[index]))
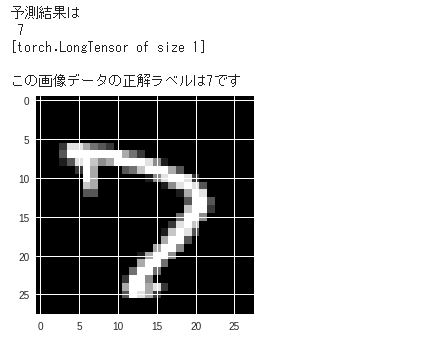
図12.5 学習後の出力結果
図12.3 学習後の出力結果
ニューラルネットワークの予想が7で、正解も7となっています。
以上が、PyTorchによるディープラーニングのミニマムバージョンの実装となります。
PyTorchの使い方の補足
上記の例ではネットワークの構築をDefine and Runで実装しましたが、ChainerのようにDefine by Runで実装するには以下のように変更します。
# 3. ネットワークの構築
# ニューラルネットワークの設定(Chainer風の書き方)
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self, n_in, n_mid, n_out):
super(Net, self).__init__()
self.fc1 = nn.Linear(n_in, n_mid) # Chainerと異なり、Noneは受けつけない。
self.fc2 = nn.Linear(n_mid, n_mid)
self.fc3 = nn.Linear(n_mid, n_out)
def forward(self, x):
# 入力xに合わせてforwardの計算を変えられる=Define by Run
h1 = F.relu(self.fc1(x))
h2 = F.relu(self.fc2(h1))
output = self.fc3(h2)
return output
model = Net(n_in=28*28, n_mid=100, n_out=10) # ネットワークのオブジェクトを生成
print(model)
入力データxに応じてforward計算式を変えられる点がDefine by Runの特徴です。
まとめ
今回は手書き数字画像であるMNISTを分類するディープラーニングをPyTorchで実装しました。次回は深層強化学習のDQN(Deep Q-learning)を実装するために、DQNについて解説を行います。
Manateeではメルマガ会員を募集中!



