2018.04.03
作りながら学ぶ強化学習 -初歩からPyTorchによる深層強化学習まで
第15回 CartPole課題で深層強化学習DQNを実装
SEやプログラマ、エンジニア、一般の方を対象に、少しずつ実際にプログラムを作りながら、強化学習および深層強化学習について解説していきます。
本連載をまとめ、さらに多くの記事を追加した書籍『つくりながら学ぶ!深層強化学習』を2018年7月に発売しました!

(上の書籍画像をクリックすると購入サイトに移動できます)
はじめに
前回は、深層強化学習DQN(Deep Q-Network)について、その概念やアルゴリズムの解説を行いました。今回はPyTorchを使用して、CartPole課題に対しDQNを実装します。連載の最終回となります。
PyTorchでDQNを実装する際の注意点
PyTorchでDQNを実装する際の注意点を5つ紹介します。この5つの注意点を意識しておけば、よりスムーズに実装を理解することができます。
・1つ目の注意点は「Experience Replay」と「Fixed Target Q-Network」を実現するために、ミニバッチ学習を実装する点です。表形式表現のQ学習では、各stepごとにそのstepの内容を学習してQ関数をアップデートしていました。しかしDQNではミニバッチ学習を行います。DQNでは各stepのデータ(状態st 、行動at 、つぎの状態st+1 、報酬rt+1 )をメモリに保存しておきます。ミニバッチとはこのメモリから複数step分のデータをランダムに取り出したデータの固まりを指します。このミニバッチを訓練データとしてニューラルネットワークの結合パラメータを学習させるので、ミニバッチ学習と呼びます。ここで注意したい点は、棒が倒れたり、200step経ち続けたstepはつぎの状態st+1が存在しない点です。そのため、つぎの状態が存在するのかしないのかで、処理を変えるように実装を工夫する必要があります。
・2つ目の注意点はPyTorchでのミニバッチの扱いです。PyTorchはミニバッチを効率よく扱えるようになっていますが、その実装には慣れが必要です。今回の実装例で、どうミニバッチを扱っているのかを理解し、慣れてください。
・3つ目の注意点は変数の型です。以前PyTorchの実装例で扱ったMNIST課題(手書き数字の分類)とは異なり、DQNではOpenAIのCartPoleとPyTorchのニューラルネットワークの間をデータが行き来します。CartPoleはNumpy型で変数を扱いますが、PyTorchはTorch.Tensorのテンソル型で変数を扱います。そのため、NumpyとTensorの間で型変換が必要となる部分が多いので、実装には注意が必要です。
・4つ目の注意点は、変数のサイズです。とくにTorch.Tensorのサイズに注意が必要です。size 1とsize 1×1など、同じものを扱っていますが、ミニバッチ学習する際の便宜上テンソルのサイズを変換している部分があります。
・5つ目の注意点は、namedtupleの使用です。namedtupleを使用することで、CartPoleから得られた観測値にフィールド名をつけて保存できるため扱いやすくなります。この点については実装で詳しく紹介します。
これら5つの点を意識していただければ、これから解説する実装を理解しやすいです。
DQNの実装
これまでと同様に、Anacondaを立ち上げ、PyTorchをインストールした仮想環境でJupyter Notebookを起動してください。
最初のセルでは、使用する一般的ライブラリを宣言します。
# Jupyterでmatplotlibを使用する宣言と、使用するライブラリの定義import gymimport numpy as npimport matplotlib.pyplot as plt%matplotlib inline |
次のセルでは、Jupyter Notebookで動画を表示、保存する関数display_frames_as_gifを宣言します。これまでの記事連載で紹介したものとまったく同じです。
# 動画の描画関数の宣言# /xcorr-notebooks/blob/master/Render%20OpenAI%20gym%20as%20GIF.ipynbfrom JSAnimation.IPython_display import display_animationfrom matplotlib import animationfrom IPython.display import displaydef display_frames_as_gif(frames): """ Displays a list of frames as a gif, with controls """ plt.figure(figsize=(frames[0].shape[1] / 72.0, frames[0].shape[0] / 72.0), dpi=72) patch = plt.imshow(frames[0]) plt.axis('off') def animate(i): patch.set_data(frames[i]) anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=50) anim.save('movie_cartpole_DQN.mp4') # 動画のファイル名と保存です display(display_animation(anim, default_mode='loop')) |
続いて、namedtupleの使用例を実装します。
# 本コードでは、namedtupleを使用します。# namedtupleを使うことで、値をフィールド名とペアで格納できます。# すると値に対して、フィールド名でアクセスできて便利です。# https://docs.python.jp/3/library/collections.html#collections.namedtuple# 以下は使用例ですfrom collections import namedtupleTr = namedtuple('tr', ('name_a', 'value_b'))Tr_object = Tr('名前Aです', 100)print(Tr_object) # 出力:tr(name_a='名前Aです', value_b=100)print(Tr_object.value_b) # 出力:100 |
上記セルを実行すると、
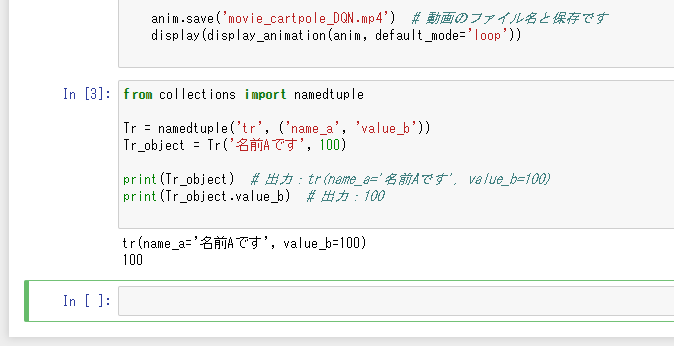
と出力されます。 このように数値100などに対して、変数のフィールド名(Tr_object.value_b)でアクセスできるようになります。状態や行動の値にアクセスしやすくするために、DQN実装時にもnamedtupleを使用します。
続いて、実際に使用するnamedtupleであるTransitionを定義します。このTransitionを使用することで4つの数値を代入したときに、それぞれの値を、state、action、next_state、rewardで呼び出せるようになります。
# namedtupleを生成from collections import namedtupleTransition = namedtuple( 'Transition', ('state', 'action', 'next_state', 'reward')) |
次に、今回使用する定数を定義します。
# 定数の設定ENV = 'CartPole-v0' # 使用する課題名GAMMA = 0.99 # 時間割引率MAX_STEPS = 200 # 1試行のstep数NUM_EPISODES = 500 # 最大試行回数 |
続いて、ミニバッチ学習を実現するために経験データを保存しておくメモリのクラスを定義します。このクラスは経験データを保存する関数pushと、ランダムに経験データを取り出す関数sampleを用意します。またlenに対して、memoryの長さを返すように定義します。このメモリクラスは経験の数がCAPACITY以上になった場合には、インデックスを前に戻して、古い記憶から上書きしていきます。
# 経験を保存するメモリクラスを定義しますclass ReplayMemory: def __init__(self, CAPACITY): self.capacity = CAPACITY # メモリの最大長さ self.memory = [] # 経験を保存する変数 self.index = 0 # 保存するindexを示す変数 def push(self, state, action, state_next, reward): """state, action, state_next, rewardをメモリに保存します""" if len(self.memory) < self.capacity: self.memory.append(None) # メモリが満タンでないときは足す # namedtupleのTransitionを使用し、値とフィールド名をペアにして保存します self.memory[self.index] = Transition(state, action, state_next, reward) self.index = (self.index + 1) % self.capacity # 保存するindexを1つずらす def sample(self, batch_size): """batch_size分だけ、ランダムに保存内容を取り出します""" return random.sample(self.memory, batch_size) def __len__(self): return len(self.memory) |
次にBrainクラスを実装します。ここがDQNの中心部になります。前回の表形式のQ学習ではBrainクラスでQ関数の表を保持していましたが、今回はニューラルネットワークを保持します。メソッドは関数replayと関数decide_actionです。replayはメモリクラスからランダムにミニバッチを取り出して、ニューラルネットワークを学習しQ関数を更新します。decide_actionは現在の状態に対して、Q値が最大となる行動のindexを返します。ただし、ε-greedy法で徐々に最適行動のみを採用します。
Brainクラスは少し長いです。一見するだけでは理解するのは難しいですが、コード内にコメントを豊富に掲載しています。1つずつ順番に理解するよう、挑戦してみてください。
# エージェントが持つ脳となるクラスです、DQNを実行します# Q関数をディープラーニングのネットワークをクラスとして定義import randomimport torchfrom torch import nnfrom torch import optimimport torch.nn.functional as Ffrom torch.autograd import VariableBATCH_SIZE = 32CAPACITY = 10000class Brain: def __init__(self, num_states, num_actions): self.num_states = num_states # CartPoleは状態数4を取得 self.num_actions = num_actions # CartPoleの行動(右に左に押す)の2を取得 # 経験を記憶するメモリオブジェクトを生成 self.memory = ReplayMemory(CAPACITY) # ニューラルネットワークを構築 self.model = nn.Sequential() self.model.add_module('fc1', nn.Linear(self.num_states, 32)) self.model.add_module('relu1', nn.ReLU()) self.model.add_module('fc2', nn.Linear(32, 32)) self.model.add_module('relu2', nn.ReLU()) self.model.add_module('fc3', nn.Linear(32, self.num_actions)) print(self.model) # ネットワークの形を出力 # 最適化手法の設定 self.optimizer = optim.Adam(self.model.parameters(), lr=0.0001) def replay(self): """Experience Replayでネットワークの重みを学習 """ # メモリサイズがミニバッチより小さい間は何もしない if len(self.memory) < BATCH_SIZE: return # メモリからミニバッチ分のデータを取り出す transitions = self.memory.sample(BATCH_SIZE) # ミニバッチの作成----------------- # transitionsは1stepごとの(state, action, state_next, reward)が、BATCH_SIZE分格納されている # つまり、(state, action, state_next, reward)×BATCH_SIZE # これをミニバッチにしたい。つまり # (state×BATCH_SIZE, action×BATCH_SIZE, state_next×BATCH_SIZE, reward×BATCH_SIZE)にする batch = Transition(*zip(*transitions)) # cartpoleがdoneになっておらず、next_stateがあるかをチェックするマスクを作成 non_final_mask = torch.ByteTensor(tuple(map(lambda s: s is not None, batch.next_state))) # バッチから状態、行動、報酬を格納(non_finalはdoneになっていないstate) # catはConcatenates(結合)のことです。 # 例えばstateの場合、[torch.FloatTensor of size 1x4]がBATCH_SIZE分並んでいるのですが、 # それを size BATCH_SIZEx4 に変換します state_batch = Variable(torch.cat(batch.state)) action_batch = Variable(torch.cat(batch.action)) reward_batch = Variable(torch.cat(batch.reward)) non_final_next_states = Variable(torch.cat([s for s in batch.next_state if s is not None])) # ミニバッチの作成終了------------------ # ネットワークを推論モードに切り替える self.model.eval() # Q(s_t, a_t)を求める # self.model(state_batch)は、[torch.FloatTensor of size BATCH_SIZEx2]になっており、 # 実行したアクションに対応する[torch.FloatTensor of size BATCH_SIZEx1]にするために # gatherを使用します。 state_action_values = self.model(state_batch).gather(1, action_batch) # max{Q(s_t+1, a)}値を求める。 # 次の状態がない場合は0にしておく next_state_values = Variable(torch.zeros( BATCH_SIZE).type(torch.FloatTensor)) # 次の状態がある場合の値を求める # 出力であるdataにアクセスし、max(1)で列方向の最大値の[値、index]を求めます # そしてその値(index=0)を出力します next_state_values[non_final_mask] = self.model( non_final_next_states).data.max(1)[0] # 教師となるQ(s_t, a_t)値を求める expected_state_action_values = reward_batch + GAMMA * next_state_values # ネットワークを訓練モードに切り替える self.model.train() # 損失関数を計算する。smooth_l1_lossはHuberlossです loss = F.smooth_l1_loss(state_action_values, expected_state_action_values) # ネットワークを更新します self.optimizer.zero_grad() # 勾配をリセット loss.backward() # バックプロパゲーションを計算 self.optimizer.step() # 結合パラメータを更新 def decide_action(self, state, episode): # ε-greedy法で徐々に最適行動のみを採用する epsilon = 0.5 * (1 / (episode + 1)) if epsilon <= np.random.uniform(0, 1): self.model.eval() # ネットワークを推論モードに切り替える action = self.model(Variable(state)).data.max(1)[1].view(1, 1) # ネットワークの出力の最大値のindexを取り出します = max(1)[1] # .view(1,1)はtorch.LongTensor of size 1 を size 1x1 に変換します else: # 0,1の行動をランダムに返す action = torch.LongTensor( [[random.randrange(self.num_actions)]]) # 0,1の行動をランダムに返す # actionは[torch.LongTensor of size 1x1]の形になります return action |
続いて棒付き台車であるAgentクラスを定義します。残りの実装部分は、表形式でのQ学習のときとほぼ同じになります。前回のQ学習との違いは関数memorizeの存在です。この関数を使用してメモリオブジェクトに経験したデータを格納します。その他の関数はQ学習の実装例と同じですが、引数が少し異なるので注意してください。
# CartPoleで動くエージェントクラスです、棒付き台車そのものになりますclass Agent: def __init__(self, num_states, num_actions): """課題の状態と行動の数を設定します""" self.num_states = num_states # CartPoleは状態数4を取得 self.num_actions = num_actions # CartPoleの行動(右に左に押す)の2を取得 self.brain = Brain(num_states, num_actions) # エージェントが行動を決定するための頭脳を生成 def update_q_function(self): """Q関数を更新します""" self.brain.replay() def get_action(self, state, step): """行動の決定します""" action = self.brain.decide_action(state, step) return action def memorize(self, state, action, state_next, reward): """memoryオブジェクトに、state, action, state_next, rewardの内容を保存します""" self.brain.memory.push(state, action, state_next, reward) |
続いて、CartPoleを実行する環境クラスを定義します。基本的に以前のQ学習と同じですが、中のコードが一部変化しています。前回のQ学習との大きな違いはCartPoleの観測結果observationをそのままstateとして使用する点です。前回の表形式表現のように離散化は行いません。中身の詳細はコードに詳しいコメントを載せているので、そちらをゆっくりご覧ください。
# CartPoleを実行する環境のクラスですclass Environment: def __init__(self): self.env = gym.make(ENV) # 実行する課題を設定 self.num_states = self.env.observation_space.shape[0] # 課題の状態と行動の数を設定 self.num_actions = self.env.action_space.n # CartPoleの行動(右に左に押す)の2を取得 # 環境内で行動するAgentを生成 self.agent = Agent(self.num_states, self.num_actions) self.total_step = np.zeros(10) # 10試行分の立ち続けたstep数を格納し、平均ステップ数を出力させます def run(self): """メインの実行""" complete_episodes = 0 # 195step以上連続で立ち続けた試行数 episode_final = False # 最後の試行フラグ frames = [] # 最後の試行を動画にするために画像を格納する変数 for episode in range(NUM_EPISODES): # 試行数分繰り返す observation = self.env.reset() # 環境の初期化 state = observation # 観測をそのまま状態sとして使用 state = torch.from_numpy(state).type( torch.FloatTensor) # numpy変数をPyTorchのテンソルに変換 # 今、FloatTensorof size 4になっているので、size 1x4に変換 state = torch.unsqueeze(state, 0) for step in range(MAX_STEPS): # 1エピソードのループ if episode_final is True: """framesに各時刻の画像を追加していく""" frames.append(self.env.render(mode='rgb_array')) action = self.agent.get_action(state, episode) # 行動を求める # 行動a_tの実行により、s_{t+1}とdoneフラグを求める # actionは、torch.LongTensor of size 1x1になっているので、[0,0]を指定して、中身を取り出す observation_next, _, done, _ = self.env.step(action[0, 0]) # episodeの終了評価と、state_nextを設定 if done: # ステップ数が200経過するか、一定角度以上傾くとdoneはtrueになる state_next = None # 次の状態はないので、Noneを格納 self.total_step = np.hstack( (self.total_step[1:], step + 1)) # step数を保存 if step < 195: reward = torch.FloatTensor( [-1.0]) # 途中でこけたら罰則として報酬-1を与える self.complete_episodes = 0 # 連続成功記録をリセット else: reward = torch.FloatTensor([1.0]) # 立ったまま終了時は報酬1を与える self.complete_episodes = self.complete_episodes + 1 # 連続記録を更新 else: reward = torch.FloatTensor([0.0]) # 普段は報酬0 state_next = observation_next # 観測をそのまま状態とする state_next = torch.from_numpy(state_next).type( torch.FloatTensor) # numpyとPyTorchのテンソルに # テンソルがsize 4になっているので、size 1x4に変換 state_next = torch.unsqueeze(state_next, 0) # メモリに経験を追加 self.agent.memorize(state, action, state_next, reward) # Experience ReplayでQ関数を更新する self.agent.update_q_function() # 観測の更新 state = state_next # 終了時の処理 if done: print('%d Episode: Finished after %d steps:10Average = %.1lf' % ( episode, step + 1, self.total_step.mean())) break if episode_final is True: # 動画を保存と描画 display_frames_as_gif(frames) break # 10連続で200step立ち続けたら成功 if self.complete_episodes >= 10: print('10回連続成功') episode_final = True # 次の試行を描画を行う最終試行とする |
最後に実行します。
# main クラスcartpole_env = Environment()cartpole_env.run() |
実行すると、おおよそ100~200ステップ程度で立ち続けるように学習できます。 うまくいかなかった場合は、何度か実行し直してみてください。
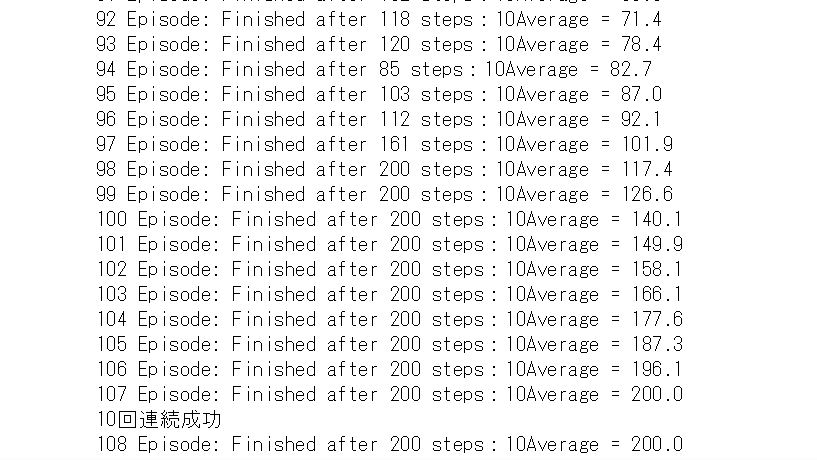
図15.1 CartPole課題でDQNを実行した結果

図15.2 CartPole課題でDQNを実行し学習した後の様子(繰り返し)
以上、CartPole課題に対してDQNを実装したコードの紹介と解説でした。
まとめ
今回はCartPole課題に対して、PyTorchを使用して深層強化学習のDQNを実装・解説しました。以上で本Web連載は終了となります。ここまでお付き合いいただき誠にありがとうございました。




