2018.03.13
作りながら学ぶ強化学習 -初歩からPyTorchによる深層強化学習まで
第12回 PyTorchによるディープラーニング実装入門(1)
SEやプログラマ、エンジニア、一般の方を対象に、少しずつ実際にプログラムを作りながら、強化学習および深層強化学習について解説していきます。
本連載をまとめ、さらに多くの記事を追加した書籍『つくりながら学ぶ!深層強化学習』を2018年7月に発売しました!

(上の書籍画像をクリックすると購入サイトに移動できます)
はじめに
前回は人類がディープラーニングに至るまでの技術の変遷を追いながら、ニューラルネットワークの歴史を外観しました。 今回は実際にディープラーニングの実装を解説します。ディープラーニングの実装にはPyTorchと呼ばれるライブラリを使用し、手書き数字の画像データ(MNIST)の分類を実行します。今回と次回の2回に分けて解説を行ないます。
PyTorchとは
ディープラーニングを実装する際にはディープラーニング用のライブラリを使用するのが一般的です。ライブラリとしてはCaffe、TensorFlow、Keras、Chainerなどが有名です。KerasはTensorFlowやCaffeを使用しやすくするwrapperとなります。Chainerは日本のPreferred Networks社が開発したライブラリです。
PyTorchはこれらのライブラリよりも後発で、最近生まれたディープラーニング用ライブラリです。元々はTorch7と呼ばれるLua言語で書かれたライブラリでした。このTorch7とPreferred Networks社のChainerをベースに2017年2月に作られたPython用ライブラリがPyTorchとなります。Chainerをforkして作られました。
PyTorchおよびChainerの利点はDefine by Run(動的計算グラフ)と呼ばれる特徴です。Define by Runは入力データのサイズや次元数に合わせてニューラルネットワークの形や計算方法を変更することができます。例えばデータAは入力次元が4なのにデータBは入力次元が5といった場合に、入力次元に応じてニューラルネットワークの計算を変えるように実装することができます。このような入力データの次元がデータごとに異なる状況は自然言語処理ではとくに頻繁に発生します。
一方でTensorFlowの特徴はDefine and Run(静的計算グラフ)と呼ばれます。Define and Runではニューラルネットワークの計算方法をはじめに決めてしまうため、入力データの次元がデータごとに異なる状況に対応しづらいという特徴があります。なおPyTochはDefine and Runでコードを書くこともできます。
PyTorchは英語圏生まれの最新ライブラリであり、大変注目を集めています(TensorFlowにもEagerというDefine by Runバージョンが作られましたが)。最近の最新論文の内容をPyTorchで実装して発表する研究者が多く、PyTorchには代表的なディープラーニング手法の実装例がほとんどすぐに手に入るという利点があります。
以上説明したように、PyTorchは「Define by Runである」、「実装例が豊富にある」という利点を持ち、今後ますます注目が集まるライブラリです。そこで本連載ではPyTorchを使用して深層強化学習を実装します。
今回はPyTorchを使用して、手書き数字の画像データ(MNIST)を分類するディープラーニングを実装します。
PyTorchの実行環境整備
PyTorchは基本的にはmacOSとLinuxをサポートしています。公式サイト[1]にアクセスすると自分の実行環境を選択する画面があり、インストール用のコマンドが表示されます(図12.1)。ここでCUDAとはNVIDIAのGPUを使用するための環境です。
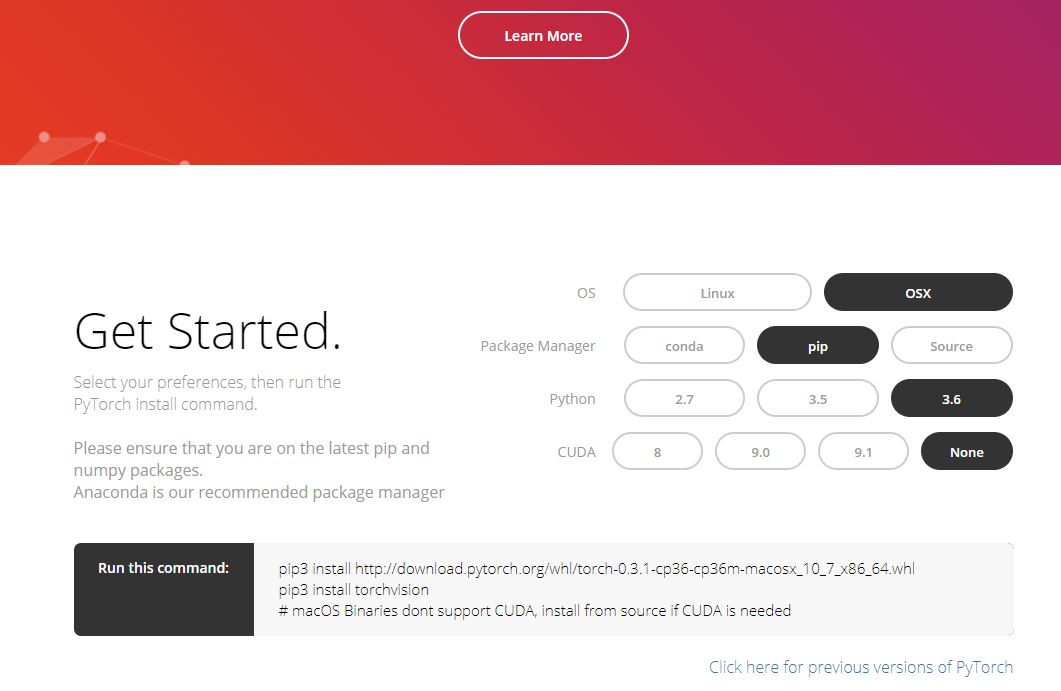
図12.1 PyTorchの公式サイト
OSがWindowsの場合には以下のサイト[2]の解説を元に、Anaconda上でインストールすることができます。
https://github.com/peterjc123/pytorch-scripts
この先はWindows 10のCUDA未使用という環境で解説を進めます。
Anacondaを立ち上げ、前回まで使用していた仮想環境でターミナルを開きます。そして以下のコマンドを1つずつ実行して、PyTorchとPyTorchと一緒に使用するtorchvisionライブラリをインストールしてください。torchvisionは主に画像データをPyTorchで扱いやすくする関数が組み込まれたライブラリです。
conda install -c peterjc123 pytorch-cpu pip install torchvision
以上でPyTorchを使用する環境の構築は終了です。ターミナルからJupyter Notebookを開き、Pythonの新規プログラムを作成して
import torch
を実行して、エラーが出ないことを確認してください(importする名前はpytorchではなくtorchである点に注意してください)。
PyTorchでMNIST
これからMNIST(Modified National Institute of Standards and Technology)と呼ばれる機械学習で最も一般的なチュートリアル課題をPyTorchで実装します。MNISTはアメリカ統計局職員および高校生が書いた手書き数字の画像データです。訓練データが6万枚、テストデータが1万枚提供されています。
今回実現したいことは、テストデータの画像をニューラルネットワークに入力したときに、その画像が0-9のどの数字なのかを分類するディープラーニングを構築することです。
構築の流れは主に、学習フェイズと推論フェイズに分かれます。学習フェイズでは訓練データを基にニューラルネットワークの素子間の結合強度を学習させます。推論フェイズではテストデータの手書き数字画像から、その数字を分類します。ここで訓練データとはニューラルネットワークの各ニューロン素子の間の結合強度(結合パラメータ)を学習させるためのデータを示し、テストデータとは学習したニューラルネットワークの精度を確かめるためのデータを示します。
MNISTデータの取得
Anacondaを立ち上げ、前回まで使用していた仮想環境でターミナルを開きます。そして以下のコマンドを実行して、scikit-learnと呼ばれるライブラリをインストールします。
scikit-learnは機械学習用のライブラリです。今回はMNISTの画像をダウンロードとダウンロードしたデータを訓練データとテストデータに分けるためにscikit-learnを使用します。
なお、PyTorchとtorchvisionの関数でMNISTのデータをダウンロードすることもできます。ですがその方法ではPyTorch特有のデータの取り扱い方を理解しづらいです。そのため今回はscikit-learnを使用してMNISTをダウンロードし、PyTorch用にデータを変換するところから実装します。
以下のコマンドをターミナルで実行し、scikit-learnをインストールしてください。
conda install scikit-learn
AnacondaからJupyter Notebookの新規Pythonファイルを作成し、以下のコマンドを実行して下さい。
# 手書き数字の画像データMNISTをダウンロード
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original', data_home=".") # data_homeは保存先を指定します
これで変数mnistにデータが格納されました。fetch_mldata()は手書き数字の画像データとラベルデータをダウンロードするのですが、ときおりダウンロード先のサーバーの都合でうまく動かない場合があります。その場合何回か実行しているとうまくいくので、繰り返してみてください。
PyTorchによるディープラーニングの実装
ここからPyTorchによるディープラーニングを実装します。今回は最低限の実装であるミニマムバージョンで解説します。PyTorchによるディープラーニングの実装は次の6ステップで行われます。
- データの前処理
- DataLoderの作成
- ネットワークの構築
- 誤差関数と最適化手法の設定
- 学習と推論の設定
- 学習と推論の実行

図12.2 PyTorchの実装フロー
1. データの前処理
データの前処理では、データをニューラルネットワークに投入できるように加工します。今回のMNISTデータの場合は、まずダウンロードしたデータを画像Xとラベルy(0-9)に分けて格納します。画像データはグレースケールの0-255の数値で表現されているので、255で割って0-1になるように正規化します。
# 1. データの前処理(画像データとラベルに分割し、正規化) X = mnist.data / 255 # 0-255を0-1に正規化 y = mnist.target
ここで1つ目の手書き文字の画像とラベルを可視化してみましょう。
# MNISTのデータの1つ目を可視化する
import matplotlib.pyplot as plt
% matplotlib inline
plt.imshow(X[0].reshape(28, 28), cmap='gray')
print("この画像データのラベルは{:.0f}です".format(y[0]))
すると以下の図12.3の結果が出力されます。変数Xには縦28×横28ピクセルの784の要素を持つNumpy形式のベクトルが7万画像分格納されています。

図12.3 MNISTの1つ目のデータを可視化
次回は2. DataLoderの作成から説明いたします。
引用
[1] PyTorch公式サイト http://pytorch.org/
[2] PyTorch for Windows https://github.com/peterjc123/pytorch-scripts
Manateeではメルマガ会員を募集中!


