2018.03.06
作りながら学ぶ強化学習 -初歩からPyTorchによる深層強化学習まで
第11回 ディープラーニングとニューラルネットワークの歴史
SEやプログラマ、エンジニア、一般の方を対象に、少しずつ実際にプログラムを作りながら、強化学習および深層強化学習について解説していきます。
本連載をまとめ、さらに多くの記事を追加した書籍『つくりながら学ぶ!深層強化学習』を2018年7月に発売しました!

(上の書籍画像をクリックすると購入サイトに移動できます)
はじめに
前回は倒立振子課題であるCartPoleプログラムをQ学習を用いて制御する方法を解説しました。 今回は深層強化学習のカギとなる技術であるディープラーニング(深層学習)について解説します。
ディープラーニングとは
ディープラーニングを一言で表すと、「層の深いニューラルネットワーク」です。 ですがこれだけの説明ではよく分かりませんので、人類がディープラーニングにたどり着くまでの歴史を追いながら、ひとつずつ解説していきます。
マッカロック・ピッツモデル
ニューラルネットワークとは、人間のニューロン(神経)の活動を模倣した機械学習手法の一種です。例えば、手書き数字の画像を分類したいとします。その場合、入力データは画像であり、縦ピクセル数 × 横ピクセル数 × RGB値の入力データとなります。このデータをニューラルネットワークに入力として与えます。そして出力からその画像の数値ラベル(0-9)を読み取り、手書き数字の画像を分類します。
ニューラルネットワークの原形となったモデルは、マッカロック・ピッツモデル(The McCulloch-Pitts Model)です[1]。形式ニューロンとも呼ばれ、ニューロンの活動を数理的に最も単純な形で模倣したモデルであり、1943年に発表されました。マッカロックは外科医で神経科学者であり、ピッツは数学者でした。神経科学者と数学者の共著論文でこのモデルが誕生しました。
マッカロック・ピッツモデルを数式で表すと以下の通りです。図で表すと、図11.1となります。
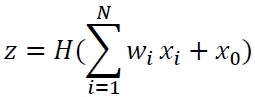
この式で、zは対象ニューロンの出力を表します。xiは対象としているニューロンとつながっているニューロン(i番目)の出力を表します。0か1の値を出力します。wiは対象ニューロンにつながるニューロン(i番目)との結合強度(結合の重み)です。x0は何らかの定数となります。 H()はヘビサイド関数と呼ばれ、中身が正の場合は1を、負の場合は0を出力する関数です。
例えば、(w1, w2) = (1, 1)のときに、x1=1, x2=1, x0=-1.5の場合、出力は H(0.5)=1となります。もし、x2=0だった場合には、出力はH(-0.5)=0となります。この例の結合パラメータの場合、マッカロック・ピッツモデルは論理演算のANDに相当します。
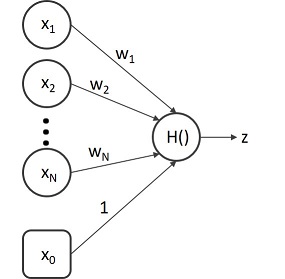
図11.1 マッカロック・ピッツモデル
マッカロック・ピッツモデルは神経科学の知見である、「全か無かの法則」を数理的に表したモデルとなります。全か無かの法則は、1871年にボウディッチが発見した法則であり、ある一定上の強さの入力がないとニューロンはまったく反応せず、ある閾値を越えると突然次のニューロンへと出力を伝えるという法則です。ニューロンが次のニューロンへと出力を伝えられるのは「発火」と呼ばれる現象が起こるからです。つまりニューロンは、発火状態でない、もしくは発火状態の2状態で表されるデジタル素子として働いていることを示した生理学的知見です。
パーセプトロン
マッカロック・ピッツモデルをたくさんつなげて多層にすれば、様々な入出力関係を再現でき、関数として使用できるのではないかと考えたのが、心理学者であったローゼンブラットです。彼はその考えをパーセプトロンと名づけ、1958年に発表しました[2]。図11.2となります。このようなニューロン素子をたくさんつなげたものをニューラルネットワークと呼びます。1943年のマッカロック・ピッツモデルの発表から15年も経っており、「やっとたくさんつなげるアイデアが出てきたのか、なんて進展が遅いんだ」と感じますが実際はそうではありません。
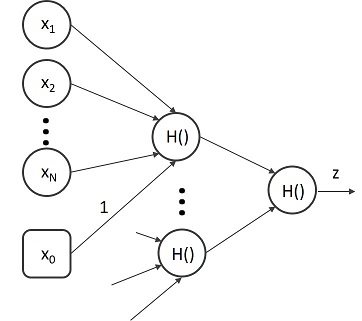
図11.2 パーセプトロン
いろんな入出力関係をパーセプトロンで再現するためには、ニューロン間の結合強度wiを都度課題に合わせて調整してあげる必要があります。ローゼンブラットは、課題ごとにこの結合強度をどう学習させれば良いのか「パーセプトロンの学習則」としてまとめました。パーセプトロンの学習則の詳細はここでは触れませんが、15年の時間がかかった理由のひとつに学習則を構築する必要性があったことが挙げられます。
またこれまでニューロンとニューロンはシナプスという部分で機能的につながっているという点までは理解されていましたが、シナプスでニューロンが物理的に直接つながっているという「ゴルジの説」と、シナプスでは物理的にはつながっていないという「カハールの説」が共存していました。この大きな謎が電子顕微鏡の発達により、ローゼンブラットのパーセプトロンの発表直前の1950年代に明らかとなり、シナプスで間接的にニューロンがつなげていることが分かりました。また1952年には生理学者のホジキンとハクスレーによって、カハールの説に基づく神経の詳細な数理モデル(Hodgkin–Huxley model)が構築されました。
このようなニューロンの生理学的知見の進展と、ニューロンの活動を模したパーセプトロンの出現は1960年代の世界中を熱狂させ、第1次ニューラルネットワークブームを引き起こしました。きっと当時の人たちは「人の脳と同じ仕組みで動くものが作れた。これを使えば人の脳と同じ知的なものが作れるはずだ!!」と思ったでしょう。もしかしたら、現代のディープラーニングブームと非常によく似ていたのかもしれません。ですが、その後パーセプトロンの限界を指摘する声が生まれました。
パーセプトロンの限界
パーセプトロンの限界を提唱したのは、なんとローゼンブラットの高校の同級生で、数学、認知科学そしてニューラルネットワークの研究者であるミンスキーでした。
ミンスキーは1層のパーセプトロンではXORのような入出力関係は表せないことを示します。人々はこれによりパーセプトロンへの期待を失い、第一次ニューラルネットワークブームが終了することへとつながりました。
ですが、本質的な問題は実はこの点ではありません。パーセプトロンも多層にすればXORを表現することはでき、
z = H(x1+x2-2H(x1+x2-1.5)-0.5)
とすれば、x1, x2のXORはパーセプトロンで表現することができます。例えば、x1=1, x2=1の場合z= H(1+1-2-0.5)=0となります。
本質的な問題は、ローゼンブラットの提唱したパーセプトロンの学習則では、この多層パーセプトロンの結合強度wiを学習できない点にありました。
それでは「学習則は脳の知見を元に学習すれば良いのでは?」と直感的に思いますが、この時点では脳内でニューロンの結合強度(シナプス間強度)が変化しているのかどうか明らかではなかったのです。仮説レベルではヘッブ則(Hebb's rule)と呼ばれる仮説が1949年に心理学者ヘッブに提唱されていましたが(マッカロックピッツモデルより後である点に注意)、実際に確認はされてはいませんでした(1973年BlissとLømoによって初めて確認)。加えて、ヘッブ則は多層パーセプトロンの学習則として適用できるものではありませんでした。
バックプロパゲーションの出現
第1次ニューラルネットワークブームが去り冬の時代を迎えていたニューラルネットワークをもう一度盛り上げたのが、1986年にラメルハートらが提唱したバックプロパゲーション(誤差逆伝搬法)です[3]。ラメルハートらと書きましたが、この「ら」が後に非常に重要となります。正確には、ラメルハート、ヒントン、ウィリアウムズの3人による共著論文となっています。
パーセプトロンではニューロンの特性である「全か無かの法則」に従い、出力をヘビサイド関数で表していました。再掲しますと、ヘビサイド関数H()は、中身が正の場合は1を、負の場合は0を出力する関数です。この関数は入力0を境に出力が急激に0から1に変化するため、数学的に取り扱いが難しいものとなっていました。
そこでラメルハートらはヘビサイド関数の使用はやめて、ロジスティック関数(シグモイド関数)を使うことにしました。ロジスティック関数は以下の式で表されます。
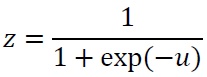
uは入力を示し、ロジスティック関数を図で表すと以下の図11.3となります。図のとおり、入力0付近で滑らかに出力が0から1へと変化し、変化の途中では0.5など、中途半端な値を出力します。
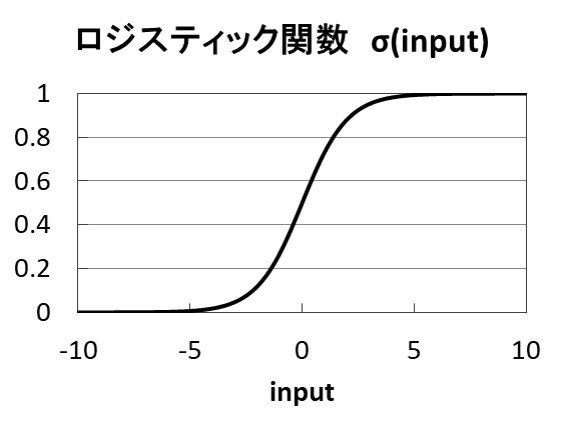
図11.3 ロジスティック関数(シグモイド関数)
もはや0、1以外を出力する時点でニューロンの発火をベースとした生理学的知見である「全か無かの法則」からは離れてしまいます(ただし単一神経ではなく、神経細胞集団や、単一神経の確率的な挙動として考えた場合にはロジスティック関数でも生理学的に妥当とも考えられます)。
ヘビサイド関数からロジスティック関数に変更したことで、数学的に取り扱いやすくなり、微分操作ができるようになりました。
微分操作ができると何が嬉しいか解説します。適当な結合強度をニューラルネットワークに設定して、入力を与え出力を計算したときに、期待した出力と異なる場合に、その誤差とシグモイド関数の微分を用いれば、非線形問題を解く多層ニューラルネットワークの結合強度が学習可能となるのです。この学習法則をバックプロパゲーション(誤差逆伝搬法)と呼びます。ここではその数理的な詳細は触れません。
なお、ラメルハートら以前に理化学研究所の甘利先生が1967年にバックプロパゲーションの概念を提唱していましたが、世界的にはラメルハートらの論文がスタンダードになってしまったという経緯などもあります。
ロジスティック関数の導入とバックプロパゲーションによって、パーセプトロンの限界であった非線形問題の学習が実現され、「これを使えば人の脳と同じ知的なものが作れるはずだ!!」と第2次ニューラルネットワークブームが到来します。
しかしながらこれまたブームが終焉します。複雑な入出力関係を学習させるには1層のニューロンの数を増やすか、層をつなげるしかありません。ニューラルネットワークを何層もつなげることを、層を深くする(deepにする)と呼びます。1層あたりのニューロンを増やす方法はあまり効率が良くなく、層を深くすることが重要でした。しかし、深いニューラルネットワークはラメルハートらの手法ではうまく結合強度を学習することができませんでした。その理由は勾配消失・爆発問題と呼ばれる現象が発生するためですが、ここでは詳細は触れません。
結局、「複雑な入出力関係はニューラルネットワークでは実現できないのか・・・」となり、第2次ニューラルネットワークブームが去ってしまいます。
ディープラーニングの誕生
深い層を持つニューラルネットワークでは結合強度がうまく学習できない問題に対して、挑戦しつづけたのがヒントンです。どこかで聞いた名前ですが、そう、バックプロパゲーションの提唱でラメルハートらの「ら」に含まれていた第二著者のヒントンです。彼はロジスティック関数の導入とバックプロパゲーションの提唱後も、深い層を持つニューラルネットワークの実現に挑戦し続けていました。
ヒントンは2006年に「ディープラーニング」と呼ばれるアイデアでこの深い層を持つニューラルネットワークを実現させます[4]。彼のアイデアは、深い層を持つニューラルネットワークの結合強度をランダムな初期値から全て一気に学習させるのではなく、各層ごとに先にある程度の初期値を当たりをつけて与える作戦でした。各層ごとの結合強度の初期値を求めるため、彼はニューラルネットワークを1層ずつ切り出し、層への入力情報と層の出力情報がうまく情報圧縮できるように結合強度を与えれば良いと考えました。
例えば図11.4のように、N次元の入力xを結合強度行列Wのネットワークに与え、例えば2次元の出力a1とa2を得ます。その後、Wの転置(Transpose)を結合強度として持つネットワークに、得られた2次元の出力a1とa2を入力として与え、N次元の出力yを求めます。通常であれば、xとyはまったく異なる値になりますが、これができるだけ同じになるよう結合強度行列Wを学習させてあげます。この考え方はオートエンコーダと呼ばれます。
図11.4のオートエンコーダはN次元のデータを一度2次元に圧縮し、再度復元していることになります。つまり図11.4の左側の結合強度行列Wのニューラルネットワークは、N次元の入力を2次元にうまく情報圧縮するネットワークとなります。こうして各層が情報圧縮の機能を持つ状態の結合強度から学習を始めれば、多層ニューラルネットワークがうまく学習できることをヒントンらは提唱しました。なおオートエンコーダの結合行列の学習には制限ボルツマンマシンという手法が使われました。
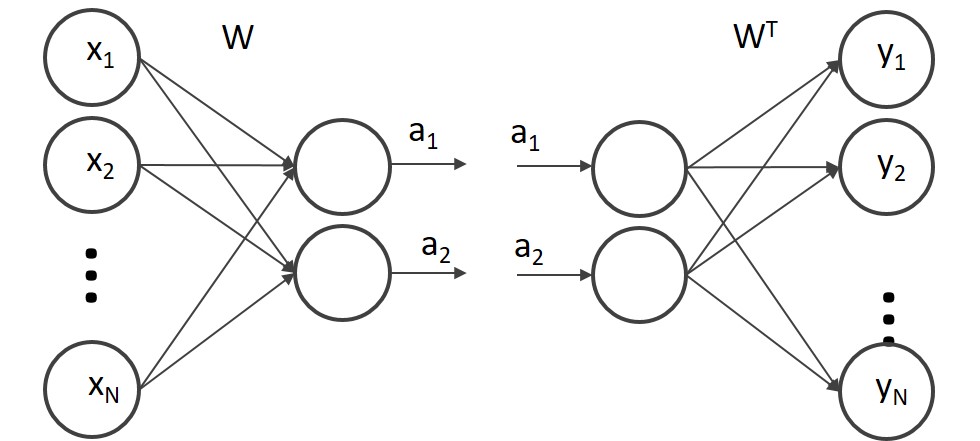
図11.4 オートエンコーダー
2012年の画像認識コンテスト「ILSVRC(ImageNet Large Scale Visual Recognition Challenge)」で、ヒントンらはディープラーニングを用いた画像認識システムを提案し、歴代の優勝記録を大幅に更新する認識精度で優勝しました。この出来事がディープラーニングに注目が集まるきっかけとなります。
現在のディープラーニングでは、初期のヒントンのアイデアであった、オートエンコーダや制限ボルツマンマシンは使用されておらず、主にロジスティック関数を図11.5に示すReLU(relu rectified linear unit)などに置き換えて、バックプロパゲーションで実現されています。
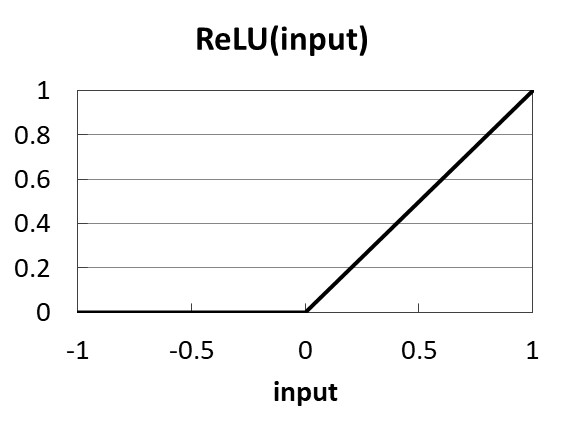
図11.5 ReLU
ヒントンらが層を重ねたニューラルネットワークであるディープラーニングを提案し、さらに改良が加えられてディープラーニングが取扱いやすくなり、2018年現在は第3次ニューラルネットワークブームや第3次人工知能ブームと呼ばれています。
振り返ってみると結果的には、ニューロンへの入力の総和を出力へと変換する関数(活性化関数)がヘビサイド関数からシグモイド関数に代わり、そしてReLUなどへと変わっていき、それに付随してニューラルネットワークの可能性が広がっていったように感じます。
このような歴史を経てニューラルネットワークは進歩し、ディープラーニングの出現により複雑な入出力関係も表現できるようになって、2018年現在のAIブームが到来しました。
まとめ
今回は人類がディープラーニングにたどり着くまでの歴史を追いながら、ディープラーニングについて解説しました。次回はPyTorchと呼ばれるライブラリを利用してディープラーニングを実装する手法を解説します。
引用
[1] McCulloch, Warren S., and Walter Pitts. "A logical calculus of the ideas immanent in nervous activity." The bulletin of mathematical biophysics 5.4 (1943): 115-133.
[2] Rosenblatt, Frank. "The perceptron: a probabilistic model for information storage and organization in the brain." Psychological review 65.6 (1958): 386.
[3] Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. "Learning representations by back-propagating errors." nature 323.6088 (1986): 533.
[4] Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." science 313.5786 (2006): 504-507.
Manateeではメルマガ会員を募集中!


