2018.02.27
作りながら学ぶ強化学習 -初歩からPyTorchによる深層強化学習まで
第10回 CartPole課題をQ学習で制御する
SEやプログラマ、エンジニア、一般の方を対象に、少しずつ実際にプログラムを作りながら、強化学習および深層強化学習について解説していきます。
本連載をまとめ、さらに多くの記事を追加した書籍『つくりながら学ぶ!深層強化学習』を2018年7月に発売しました!

(上の書籍画像をクリックすると購入サイトに移動できます)
はじめに
前回は倒立振子課題であるOpenAI GymのCartPoleプログラムについて、実行環境の構築方法を解説しました。今回は強化学習の1つであるQ学習を用いてCartPole課題を制御する方法を解説し、実装します。
Q学習によるCartPoleの制御
CartPole課題は前回までの迷路課題と比べ、2点難しいところがあります。1点目はOpenAI Gymの作法に合わせてプログラムを書く必要がある点です。2点目は状態の定義が迷路と異なる点です。迷路の場合、状態とはどのマスにいるかを示しており、非常に単純でした。一方でCartPoleの場合は状態の定義が複雑になります。
CartPole課題におけるQテーブルの実装方法
CartPoleの状態は
- カート位置(-2.4~2.4)
- カート速度(-Inf~Inf)
- 棒の角度(-41.8°~41.8°)
- 棒の角速度(-Inf~Inf)
の4変数で表されます[1]。カッコ内の数字はそれぞれの変数がとりうる範囲を示しており、これらの4変数は連続値となります。CartPole課題は迷路とは異なり、状態を表す変数が複数存在し、さらにそれぞれ連続値をとる点が難しい原因です。
このようなCartPoleの状態に対して、迷路と同じようにQ関数を表形式で表現します。そのためには連続値を離散化する必要があります。例えばカートの位置を6つの値(0~5)で離散化する場合には、位置が-2.4~-1.6の場合は0、-1.6~-0.8は1、-0.8~0.0は2、・・・、1.6~2.4は5という値に変換します。ただし、端に行き過ぎた瞬間などには-2.4を越えた位置に行く可能性もあるので、-Inf~-1.6を0とし、1.6~Infを5とします。すると連続値だったカートの位置は0~5の6つの数字で表されます。他の変数も同様に6つの値で離散化する場合、変数が4種類あるので、64=1296通りで、CartPoleの状態が表されます。つまり迷路に例えると、マスが1296個あるイメージです。
CartPoleの行動は、カートを右に押す、カートを左に押すの2通りです。カートに対して右か左に加速度を与える操作を行います。
よって、CartPoleのQ関数は各状態を6つの値で離散化したとすれば、1296行×2列の表形式で表すことができます。迷路のときと同様に表の中の値は、各状態で各行動を採用した際にその後得られるであろう割引報酬和を示します。これでCartPole課題でも迷路のときと同じようにQ関数を表形式で表すことができます。
CartPole課題におけるQ学習の実装
今回の実装からクラスを定義して実装します。今回実装するクラスはAgent、Brain、Environmentの3つです。AgentはCartPole課題の場合、棒付き台車そのものです。そしてAgentは周囲の状態に合わせて、自分のQ関数を更新する関数update_q_functionと、次の行動を決定する関数get_actionを持ちます。BrainはAgentの頭脳となる部分です。Brainに今回はQテーブルを用いたQ学習を実装します。BrainはAgentが観測した周囲の状態を離散化する関数digitize_stateと、Qテーブルを更新する関数update_Qtable、Qテーブルから行動を決定する関数decide_actionを持ちます。今回AgentとBrainにクラスを分けたのは、今後Q学習をSarsaに変更したりDeepLearningを用いた手法に変更したりする際に、このBrainクラスだけを変更すれば良いようにする意図があります。EnvironmentはOpenAI gymの実行環境です。今回はCartPoleを実行する環境であり、実行関数runを持ちます。
上記のクラス構造を意識しながら実装します。まずはじめに必要なライブラリのインポートと、前回と同様にOpenAI gymの実行結果をGIF動画として保存する関数display_frames_as_gifを定義します。実装する際は、前回構築した仮想環境から、Jupyter Notebookを立ち上げてください。
# Jupyterでmatplotlibを使用する宣言と、使用するライブラリの定義 import gym import numpy as np import matplotlib.pyplot as plt %matplotlib inline
# 動画の描画関数の宣言
# 参考URL http://nbviewer.jupyter.org/github/patrickmineault
# /xcorr-notebooks/blob/master/Render%20OpenAI%20gym%20as%20GIF.ipynb
from JSAnimation.IPython_display import display_animation
from matplotlib import animation
from IPython.display import display
def display_frames_as_gif(frames):
"""
Displays a list of frames as a gif, with controls
"""
plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0),
dpi=72)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames),
interval=50)
anim.save('movie_cartpole.mp4') # 動画のファイル名と保存です
display(display_animation(anim, default_mode='loop'))
続いて、今回使用する定数を以下のように定義します。MAX_STEPSは1試行の最大ステップ数です。CartPole-v0の場合は200step立ち続ければゲーム攻略となるので200としています。NUM_EPISODESは最大の試行回数です。今回は1000と設定し、この試行数以内にゲームの攻略を目指します。
# 定数の設定 ENV = 'CartPole-v0' # 使用する課題名 NUM_DIZITIZED = 6 # 各状態の離散値への分割数 GAMMA = 0.99 # 時間割引率 ETA = 0.5 # 学習係数 MAX_STEPS = 200 # 1試行のstep数 NUM_EPISODES = 1000 # 最大試行回数
次にAgentクラスを定義します。Agentクラスはコンストラクタ(init)でCartPoleの状態変数の数と行動の種類数を格納します。また自身の頭脳となるBrainクラスを生成します。さきほど説明した通り、Q関数の更新と行動の決定をBrainクラスを通じて実行するメソッドを持ちます。
# CartPoleで動くエージェントクラスです、棒付き台車そのものになります
class Agent:
def __init__(self, num_states, num_actions):
# 課題の状態と行動の数を設定
self.num_states = num_states # CartPoleは状態数4を取得
self.num_actions = num_actions # CartPoleの行動(右に左に押す)の2を取得
self.brain = Brain(num_states, num_actions) # エージェントが行動を決定するための脳を生成
def update_q_function(self, observation, action, reward, observation_next):
# Q関数の更新
self.brain.update_Qtable(observation, action, reward, observation_next)
def get_action(self, observation, step):
# 行動の決定
action = self.brain.decide_action(observation, step)
return action
次にAgentが持つ頭脳となるクラスBrainを定義します。今回はQ学習を実装しています。少し長くて難しそうですが、やっていることは単純です。
関数binsとdigitize_stateを用いて、4変数の連続状態を1296通りの離散値へと変換しています。関数binsでnp.linspaceのあとに[1:-1]がついているのは、離散化する際に端を-InfとInfに設定するためです。関数digitize_stateにおいて、pole_angleを-0.5から0.5で離散化しているのは、この変数がプログラム内では[radian]で表されているからです。0.5[radian] = 約29[°]となります。関数digitize_stateのreturnの部分は一見難しそうですが、離散化された状態をNUM_DIZITIZED=6の場合には6進数で表現しています。例えば、 カート位置, カート速度, 棒の角度, 棒の角速度)=(1, 2, 3, 4) だった場合には、
1 ∗ 60 + 2 ∗ 61 + 3 ∗ 62 + 4 ∗ 63 = 985
となり、状態985と定義されます。
Qテーブルの更新方法は迷路課題のときと同様です。行動の決定は試行数が少ないときは探索行動が多くなるようにε-greedy法としています。この部分の実装には引用[2]も参考にさせていただきました。
# エージェントが持つ脳となるクラスです、Q学習を実行します
class Brain:
def __init__(self, num_states, num_actions):
self.num_states = num_states # CartPoleは状態数4を取得
self.num_actions = num_actions # CartPoleの行動(右に左に押す)の2を取得
# 状態を分割数^(4変数)にデジタル変換したQ関数(表)を作成
self.q_table = np.random.uniform(low=0, high=1, size=(NUM_DIZITIZED**self.num_states, self.num_actions))
def bins(self, clip_min, clip_max, num):
#観測した状態(連続値)を離散値にデジタル変換する
return np.linspace(clip_min, clip_max, num + 1)[1:-1]
def digitize_state(self, observation):
# 観測したobservation状態を、離散値に変換する
cart_pos, cart_v, pole_angle, pole_v = observation
digitized = [
np.digitize(cart_pos, bins=self.bins(-2.4, 2.4, NUM_DIZITIZED)),
np.digitize(cart_v, bins=self.bins(-3.0, 3.0, NUM_DIZITIZED)),
np.digitize(pole_angle, bins=self.bins(-0.5, 0.5, NUM_DIZITIZED)),
np.digitize(pole_v, bins=self.bins(-2.0, 2.0, NUM_DIZITIZED))
]
return sum([x * (NUM_DIZITIZED**i) for i, x in enumerate(digitized)])
def update_Qtable(self, observation, action, reward, observation_next):
# QテーブルをQ学習により更新
# 観測を離散化
state = self.digitize_state(observation)
state_next = self.digitize_state(observation_next)
Max_Q_next = max(self.q_table[state_next][:])
self.q_table[state, action] = self.q_table[state, action] + ETA * (reward + GAMMA * Max_Q_next - self.q_table[state, action])
def decide_action(self, observation, episode):
# ε-greedy法で徐々に最適行動のみを採用する
state = self.digitize_state(observation)
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0, 1):
action = np.argmax(self.q_table[state][:])
else:
action = np.random.choice(self.num_actions) # 0,1の行動をランダムに返す
return action
最後のクラスであるEnvironmentを定義します。今回は10回連続で195step以上立ち続ければ強化学習成功とし、動画を保存のためにもう1回実行してしています。self.env = gym.make(ENV)で、実施する課題を設定しています。self.env.observation_space.shape[0]は課題が持つ状態変数の数を示します。self.env.action_space.nは課題が持つ行動の数を示します。
OpenAI Gymを実行する際に、各試行の最初に以下の命令observation = self.env.reset()を実行する必要があります。observationには状態を表す変数の値が格納されます。
observation_next, reward_notuse, done, info_notuse = self.env.step(action) は、actionを実行するメソッドです。その結果、実行後の次のステップでの状態observation_nextと、元々CartPole-v0で決められているルールでの報酬、実行終了フラグであるdone、その他情報のinfoが出力されます。doneは200step経過するか、棒が20.9度以上傾いたり、カート位置が±2.4の範囲外まで移動するとTrueとなります。今回はこの関数で出力される報酬と情報は使用しないので、notuseを記載しています。
episode_finalは、10試行連続で成功した場合にTrueとなるフラグです。episode_finalがTrueの試行では各stepでの画像をframesに格納していき、最後に動画を保存・再生します。
# CartPoleを実行する環境のクラスです
class Environment:
def __init__(self):
self.env = gym.make(ENV) # 実行する課題を設定
self.num_states = self.env.observation_space.shape[0] # 課題の状態と行動の数を設定
self.num_actions = self.env.action_space.n # CartPoleの行動(右に左に押す)の2を取得
self.agent = Agent(self.num_states, self.num_actions) # 環境内で行動するAgentを生成
def run(self):
# 実行
complete_episodes = 0 # 195step以上連続で立ち続けた試行数
episode_final = False # 最後の試行フラグ
for episode in range(NUM_EPISODES):
# 試行数分繰り返す
observation = self.env.reset() # 環境の初期化
episode_reward = 0 # エピソードでの報酬
# 1エピソードのループ
for step in range(MAX_STEPS):
if episode_final is True:
# framesに各時刻の画像を追加していく
frames.append(self.env.render(mode='rgb_array'))
action = self.agent.get_action(observation, episode) # 行動を求める
# 行動a_tの実行により、s_{t+1}, r_{t+1}を求める
observation_next, reward_notuse, done, info_notuse = self.env.step(action)
# 報酬を与える
if done: # ステップ数が200経過するか、一定角度以上傾くとdoneはtrueになる
if step < 195:
reward = -1 # 途中でこけたら罰則として報酬-1を与える
self.complete_episodes = 0
else:
reward = 1 # 立ったまま終了時は報酬1を与える
self.complete_episodes = self.complete_episodes + 1 # 連続記録を更新
else:
reward = 0
episode_reward += reward # 報酬を追加
# step+1の状態observation_nextを用いて,Q関数を更新する
self.agent.update_q_function(
observation, action, reward, observation_next)
# 観測の更新
observation = observation_next
# 終了時の処理
if done:
print('{0} Episode: Finished after {1} time steps'.format(
episode, step+1))
break
if episode_final is True:
# 動画を保存と描画
display_frames_as_gif(frames)
break
if self.complete_episodes >= 10:
print('10回連続成功')
frames = []
episode_final = True # 次の試行を描画を行う最終試行とする
以上で実装は完了です。上記の各クラス間の情報の流れと、順番を可視化すると以下の図10.1のようになります。
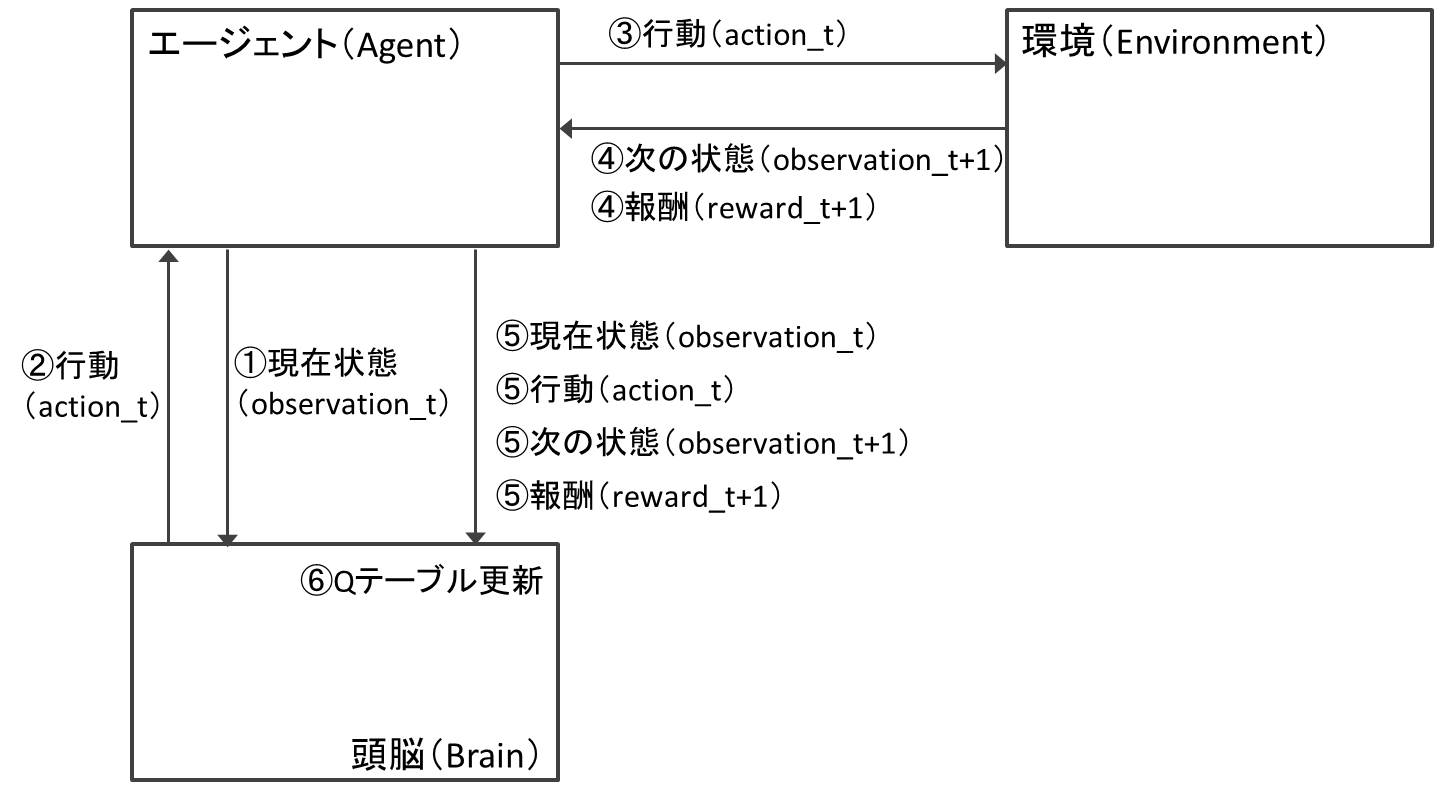
図10.1 CartPole課題におけるQ学習実装の概要図
最後に環境Environmentを生成し、関数runを実行します。
# main クラス cartpole_env = Environment() cartpole_env.run()
すると以下の図10.2のように各試行ごとに何ステップ立ち続けたのかが出力され、10連続で200ステップ立ち続ければ終了します。
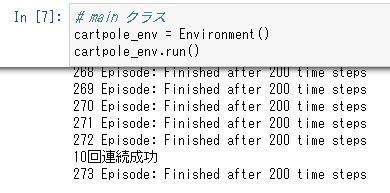
図10.2 main関数実行の結果
成功した後に保存された動画の様子が以下の図10.3です。うまく立ち続けている様子が分かります。
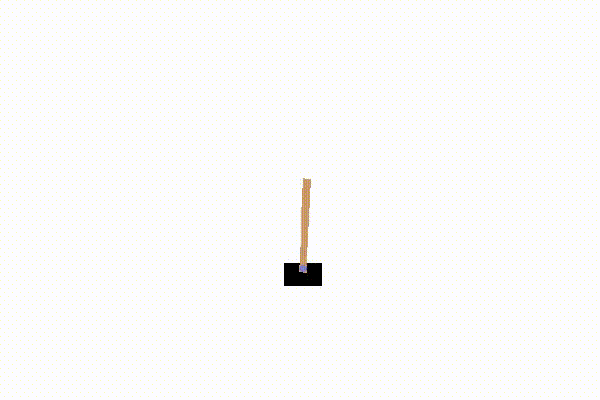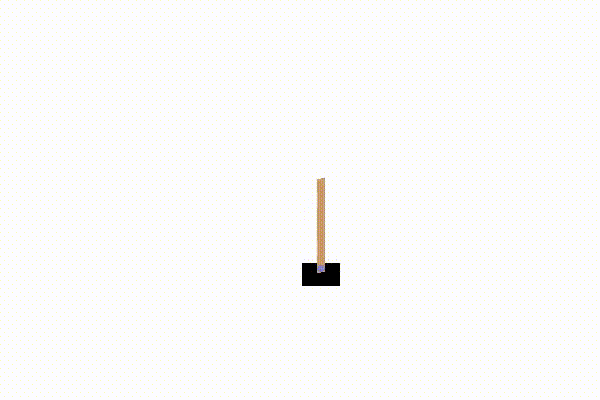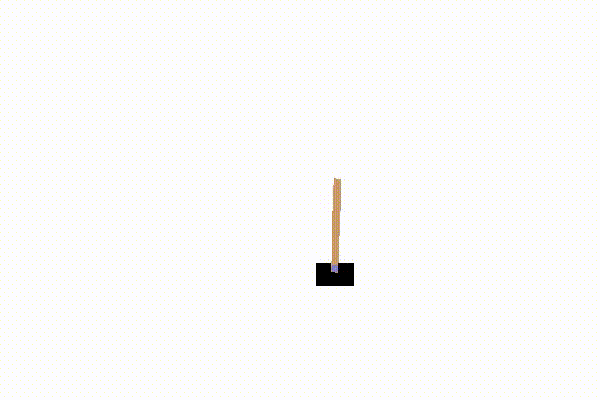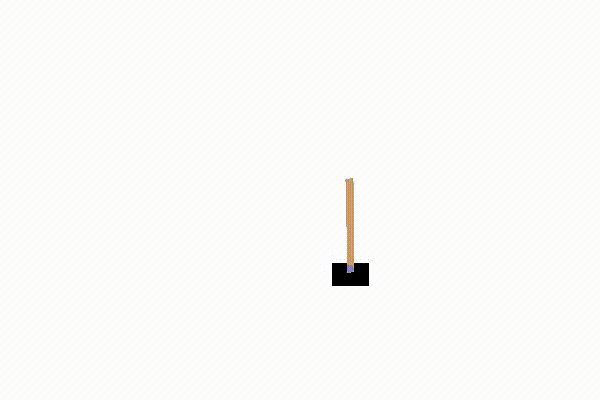
図10.3 Q学習により強化学習された結果の様子(再生繰り返し)
本連載では分かりやすさを優先して、OSにWindows 10、実行環境にJupyter notebookを使用しOpenAI Gymを実行しています。そのため動作が不安定な面があり、ipykernel_launcher.pyというウィンドウが開いたあと、そのウィンドウがフリーズします。実行後に強制的に閉じてください。
まとめ
今回はOpenAI GymのCartPole課題をQ学習によって強化学習する手法を解説し、さらに実装を行いました。次回は深層強化学習の導入として、ディープラーニングについて解説します。
引用
[1] CartPole v0 https://github.com/openai/gym/wiki/CartPole-v0
[2] これさえ読めばすぐに理解できる強化学習の導入と実践 https://deepage.net/machine_learning/2017/08/10/reinforcement-learning.html




