2017.10.31
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第13回 機械学習で「ゆるふわスケッチ」アプリを作ろう
今回は、Google Brain の Magentaプロジェクトが公開している、Sketch-RNNと呼ばれる機械学習モデルを利用したアプリを作成します。手書きのサンプル画像に対して、機械学習モデルが類似のスケッチを描くというものです。決して上手なスケッチではありませんが、子供が描いたかのような「ゆるふわ」な感じが自然で楽しめるアプリです。
1. はじめに
機械学習の世界では、近年、ディープラーニングを利用した「生成モデル」の研究が盛んに行われています。これは、人間が作成した音楽や画像のデータを元にして、類似のデータを生成する機械学習モデルを作り出そうという試みです。冒頭で紹介したMagentaプロジェクトは、機械学習を利用して、新しい音楽や芸術作品を生み出そうというプロジェクトですが、ここでもまた、各種の生成モデルが活用されています。
画像の生成モデルを学習するアルゴリズムとしては、DCGAN(Deep Convolutional Generative Adversarial Network)が有名ですが、今回利用する「Sketch-RNN: A Generative Model for Vector Drawings」は、時系列データを取り扱うRNN(Recurrent Neural Network)と、入力データに類似のデータを生成するVAE(Variational Autoencoder)と呼ばれる仕組みを組み合わせたもので、線画のストローク情報、すなわち、1本1本の線を引いていく順序を示すデータを生成することが可能です。今回のアプリでは、マウスを用いて描いた線画のストローク情報を元にして、類似の線画を自動生成します。
この時、入力画像とまったく同じデータを生成しても面白くありません。既存のデータセットを用いて学習したモデルは、入力画像を参考にしながら、学習データに類似のデータを生成します。たとえば、「ネコ」と「バス」のデータで学習したモデルは、どのような入力画像に対しても、ネコ、あるいは、バスの画像を生成しようとします。できるだけきれいな画像を生成するには、どのようなサンプルを与えるとよいのか、小さな子どもに絵のお手本を見せるような気持ちで遊んでみるとよいでしょう。
2. Sketch-RNNについて
今回使用する機械学習モデル「Sketch-RNN」の仕組みを簡単に説明します。図1は、Sketch-RNNのGitHubリポジトリに掲載されているニューラルネットワークの構造図です。
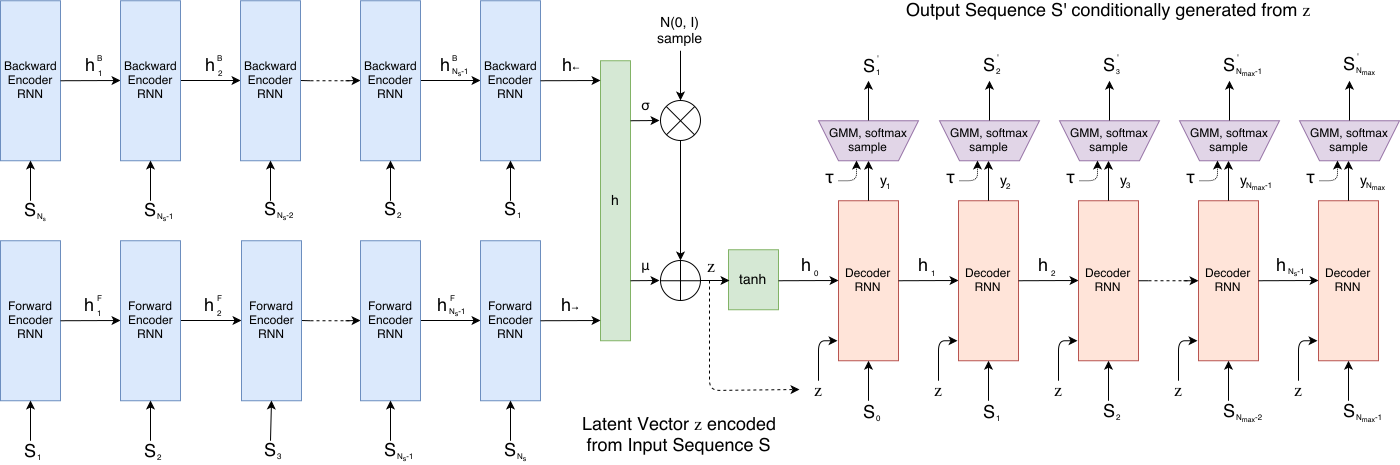
一見すると複雑に見えますが、全体の仕組みは比較的シンプルです。まず、左側の水色の部分は、入力データを「特徴ベクトル」と呼ばれる128個の数値データに変換します。この128個の数値の中に、入力画像の特徴を表わすエッセンスが凝縮されていると考えてください。今回の場合、入力データは、線画のストローク情報になるので、RNNを用いて、これを時系列データとして取り扱っています。そして、右側の赤色の部分は、特徴ベクトルから新たな画像データを生成する部分です。こちらもRNNを用いて、これまでのストロークに対して、次のストロークを「どの方向にどのぐらいの長さで引くのか」という情報を次々に生成していきます。この情報には、ペンを上げ下げする情報も付随しており、出力されたストローク情報をつなぎ合わせると、一枚の線画が得られるというわけです。
そして、既存の線画のストロークデータを用いて、このニューラルネットワークに対する学習処理を行います。ここでは、入力画像に対して、なるべく同じような画像が出力されるように学習を行います。一般にこのような方法で学習された機械学習モデルは、オートエンコーダーと呼ばれます。学習が終わったオートエンコーダーは、入力部分(水色の部分)と出力部分(赤色の部分)を分けて利用します。入力部分に新しいデータを入力すると、それを特徴ベクトルに変換する処理が行われます。次に、この特徴ベクトルを出力部分に与えると、それを元にして、新しい画像データが生成されます。
このようにして出来上がったオートエンコーダーの動作は、学習時に使用したデータによって大きく変わります。たとえば、「ネコ」の画像だけを用いて学習したオートエンコーダーの出力部分は、「ネコ」に類似の画像を出力するようにチューニングが行われます。言い換えると、どのような特徴ベクトルを与えたとしても、必ず、ネコのような画像が生成されるのです。これにより、「入力画像を参考にしながら、それに類似したネコの画像を生成する」といった処理が実現されます。
3. 学習データの紹介
今回のアプリでは、Magentaプロジェクトが公開している事前学習済みのモデルを使用します。これらのモデルの学習には、GoogleがAI Experimentsで公開しているお絵かきゲーム「Quick, Draw!」のプレイヤーから提供されたデータセットである「The Quick, Draw! Dataset」が使用されています(図2)。

この中から特に、「ネコとバス」「ゾウとブタ」「フラミンゴ」「フクロウ」のデータを用いて学習した4種類のモデルを使用しています。たとえば、「ネコとバス」で学習したモデルでは、どのような画像を入力しても、ネコ、もしくは、バスに類似した画像が出力されます。この際、入力画像の形によって、ネコになったりバスになったりする点が面白い所です。「ネコとバスがまざった画像」を入力するとどうなるのか試してみるのも面白いかも知れません。
4. サンプルアプリのインストール手順
それでは、さっそくサンプルアプリをインストールして利用してみましょう。今回のアプリは、Webブラウザから利用可能なWebアプリケーションになっており、Google Compute Engine(GCE)の仮想マシン上で実行します。PythonのWebアプリケーションフレームワークである、Flaskを用いて作成されており、Flaskのコードの中からTensorFlowによる認識処理を実行する形になります。
仮想マシンインスタンスの作成
はじめに、準備として、Google Cloud Platform(GCP)にアカウントを登録して、新しいプロジェクトを作成します。この手順については、第0回の記事を参考にしてください。プロジェクトが作成できたら、コンソール画面の「Compute Engine」メニューから「VMインスタンス」を選び、新しい仮想マシンインスタンスを次のような構成で作成します。
・仮想CPUコア:4個
・メモリー容量:8GB
・ゲストOS:Debian GNU/Linux 9 (stretch)
・「HTTPトラフィックを許可する」にチェックを入れる
・「静的IPアドレス」を割り当て
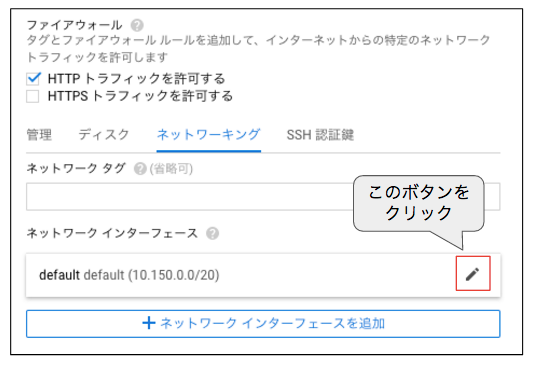
最後の静的IPアドレスを割り当てる際は、インスタンス作成のメニューで「Management, disks, networking, SSH keys」を開いて、「ネットワーキング」のタブから「default」インターフェースの編集ボタン(鉛筆のアイコン)をクリックします(図3)。その後、「外部IP」のプルダウンメニューから「IPアドレスを作成」を選択して、任意の名前を指定します。この時に割り当てられるIPアドレスは、仮想マシンインスタンスを停止しても変化することがなく、外部からアプリにアクセスする際の固定的なIPアドレスとして使用することができます。
コンソール画面の「Compute Engine」→「VMインスタンス」から仮想マシンインスタンスの一覧が確認できます。仮想マシンインスタンスが起動したら、右にある「SSH」ボタンを押します。新しいウィンドウでSSH端末の画面が開いて、自動的にゲストOSへのログインが行われます。ログインした後は、次のコマンドで作業ユーザーをrootに切り替えておきます。
# sudo -i ← #より右側を入力します
この後の作業は、すべてrootユーザーの状態で行います。
前提パッケージのインストール
まず、次のコマンドで前提パッケージをインストールします。
# apt-get update # apt-get install -y build-essential python-pip unzip python-cairosvg git # pip install ipython==5.5.0 rdp==0.8 svgwrite==1.1.6 tensorflow==1.3.0 Flask==0.12.2 # pip install magenta
続いて、次のコマンドを実行して、学習済みモデルのバイナリファイルをダウンロードします。
# mkdir -p /opt/sketch_demo/models # cd /opt/sketch_demo/models # curl -OL http://download.magenta.tensorflow.org/models/sketch_rnn.zip # unzip sketch_rnn.zip
アプリのインストールと起動
いよいよ、アプリをインストールして、起動していきます。次のコマンドで、アプリのコードをダウンロードしてインストールします。
# cd $HOME # git clone https://github.com/GoogleCloudPlatform/tensorflow-sketch-rnn-example # cp -a tensorflow-sketch-rnn-example/sketch_demo /opt/ # cp /opt/sketch_demo/sketch_demo.service /etc/systemd/system/
このアプリでは、Webブラウザから接続した際に簡易的な認証処理が行われるようになっています。ファイル /opt/sketch_demo/auth_decorator.py をエディタで開いて、次の username とpassw0rdの部分を書き換えることで、認証用のユーザー名とパスワードを変更することができます。このままのユーザー名/パスワードで使用する場合は、書き換えなくても構いません。
USERNAME = 'username' PASSWORD = 'passw0rd'
最後に次のコマンドを実行すると、アプリが起動します。
# systemctl daemon-reload
# systemctl enable sketch_demo
# systemctl start sketch_demo
# systemctl status sketch_demo
sketch_demo.service - Sketch-RNN demo
Loaded: loaded (/etc/systemd/system/sketch_demo.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2017-10-21 05:59:12 UTC; 10s ago
Main PID: 2049 (start_app.sh)
Tasks: 10 (limit: 4915)
CGroup: /system.slice/sketch_demo.service
├─2049 /bin/bash /opt/sketch_demo/start_app.sh
├─2050 /usr/bin/python /opt/sketch_demo/backend.py -p 8081 -d /opt/sketch_demo/models/catbu
├─2051 /usr/bin/python /opt/sketch_demo/backend.py -p 8082 -d /opt/sketch_demo/models/eleph
├─2052 /usr/bin/python /opt/sketch_demo/backend.py -p 8083 -d /opt/sketch_demo/models/flami
├─2053 /usr/bin/python /opt/sketch_demo/backend.py -p 8084 -d /opt/sketch_demo/models/owl/l
└─2054 /usr/bin/python /opt/sketch_demo/app.py
Oct 21 05:59:17 sketch-demo start_app.sh[2049]: INFO:tensorflow:Input dropout mode = 0.
Oct 21 05:59:17 sketch-demo start_app.sh[2049]: INFO:tensorflow:Output dropout mode = 0.
Oct 21 05:59:17 sketch-demo start_app.sh[2049]: INFO:tensorflow:Recurrent dropout mode = 0.
...
最後のコマンドは、アプリの稼動状態をチェックするものです。アプリを起動した直後にモデルのデータを読み込む処理が実施されますが、読み込みが完了するまで1分程度かかりますので、そのまましばらく待つようにしてください。その後は、Webブラウザから、最初に設定した静的IPアドレスにアクセスすることで、アプリを使用することができます。
アプリにアクセスすると、図4のような画面が表示されます。上部のキャンバスにマウスで線画を描いて「Submit」ボタンを押すと、機械学習モデルで生成された3種類の画像が表示されます。ここでは、画像生成の際に乱数の要素を加えており、左から右に向かって、順に乱数の影響を大きくしています。そのため、右に行くほど、より乱雑な画像となります。
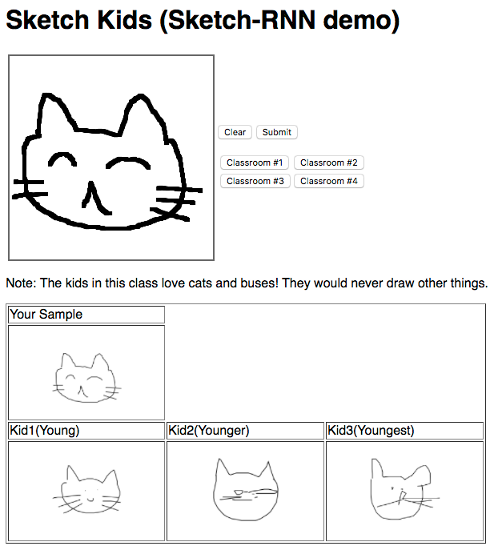
また、「Classroom #1」~「Classroom #4」のボタンで画像を生成するモデルを切り替えることができます。このアプリでは、4つの教室にいる子供がお手本を見ながら絵を描くという設定になっており、教室によって子供が描く絵の種類が変わるという想定です。それぞれ、「ネコとバス」「ゾウとブタ」「フラミンゴ」「フクロウ」のデータで学習したモデルが用意されています。
5. サンプルアプリの解説
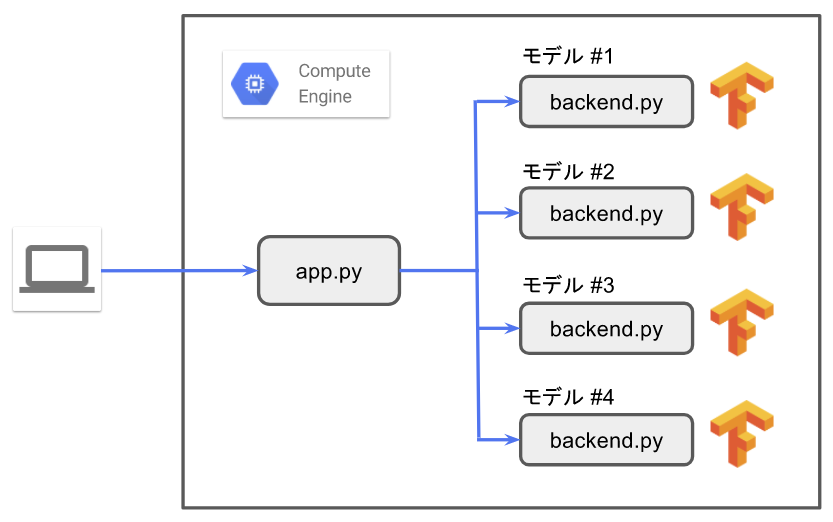
このサンプルアプリでは、複数のモデルを同時に使用するため、モデルごとに個別のバックエンドプロセス(backend.py)を起動して、それぞれ、localhostの異なるポート番号(8081~8084)で、REST APIによるアクセスを受け付けるようにしています。これとは別に、クライアントからのアクセスを受け付けるフロントエンドのプロセス(app.py)があり、クライアントから受けとったスケッチデータを指定された教室(モデル)に応じて、対応するバックエンドに転送します(図5)。バックエンドからは、生成された画像データが返却されるので、それらのデータは、フロントエンドから、再び、クライアントに返送されます。
画像生成の中心となる処理は、バックエンドのプログラムファイル sketch_demo/backend.py に記載されており、専用のクラス SketchGenerator としてまとめてあります。このクラスのインスタンスが生成されると、TensorFlowのグラフの作成と学習済みモデルの読み込みが行われます。その後、encodeメソッドにユーザーが描いたサンプルのスケッチデータを受け渡すと、オートエンコーダーの入力部分により、特徴ベクトルへの変換が行われます。さらに、この特徴ベクトルをdecodeメソッドに受け渡すと、これを元にして新しい画像が生成されます。この際、decodeメソッドの持つtemperatureオプションにより、乱数の影響度を調整することが可能です。これらの処理内容の詳細については、Sketch-RNNのGitHubリポジトリで公開されている、Jupyter Notebookの内容が参考になるでしょう。
6. 後片付け
サンプルアプリの動作確認ができたら、公開中のアプリは停止しておきましょう。アプリの起動/停止処理は、次のコマンドで行うことができます。
# systemctl stop sketch_demo ← アプリの停止 # systemctl start sketch_demo ← アプリの起動
ただし、アプリを停止しても、仮想マシンインスタンスや固定IPアドレスに対する課金は継続します。作成したプロジェクトを削除すれば、課金を完全に停止することができます。プロジェクトを削除する際は、Cloud Consoleの「IAMと管理」→「設定」メニューで、「削除」ボタンを押します。この時もプロジェクトIDの入力を求められるので、該当のIDを入力すると削除処理が行われます。
Manateeではメルマガ会員を募集中!
