2017.07.14
第6回 リカレントニューラルネットワークの実装(2)
TensorFlowによるリカレントニューラルネットワーク(RNN)の実装について解説していきます。

電子書籍『詳解 ディープラーニング』をマナティで発売中!
(上の書籍画像をクリックすると購入サイトに移動できます)
TensorFlowによるリカレントニューラルネットワークの実装
リカレントニューラルネットワークにおいても、これまで同様 inference()、loss()、training() の構成は変わりません。順番に中身を見ていきましょう。
まず inference() ですが、シンプルに考えると簡易的な擬似コードは下記になるはずです。
def inference(x):
s = tanh(matmul(x, U) + matmul(s_prev, W) + b)
y = matmul(s, V) + c
return y
しかし、このままでは s_prev がどこまで時間をさかのぼるべきかを把握することができません。そこで、引数に時間 𝜏 に相当する maxlen をとり、
def inference(x, maxlen):
# ...
for t in range(maxlen):
s[t] = s[t - 1]
y = matmul(s[t], V) + c
return y
という計算をどこかで行う必要があります。TensorFlow では、この時系列に沿った状態を保持しておくための実装は tf.contrib.rnn.BasicRNNCell() を用いることで実現できます※。
※:もともとリカレントニューラルネットワーク用のAPI は tf.nn.rnn などで提供されていましたが、TensorFlowのバージョンが 1.0.0 から tf.contrib.rnn に移行されました。今後もバージョンアップに伴いAPI の仕様が変わるかもしれませんが、ここでは実装の大枠をつかむようにしましょう。
cell = tf.contrib.rnn.BasicRNNCell(n_hidden)
この cell は内部で state( 隠れ層の状態)を保持しており、これを次の時間に順々に渡していくことで、時間軸に沿った順伝播を実現します。最初の時間は入力層しかない(過去の隠れ層がない)ので、
initial_state = cell.zero_state(n_batch, tf.float32)
という「ゼロ」の状態を代わりに与えます。ここで、n_batch はデータ数となります。placeholder では学習データ数は None とすることができましたが、cell.zero_state() は実際の値を持っておかなければならないので、n_batch という引数を与えています。ドロップアウト時に用いた keep_prob と同じような扱いだと考えると分かりやすいかもしれません。
これらを用いると、入力層から出力層の手前までの出力を表す実装は下記のようになります。
state = initial_state
outputs = [] # 過去の隠れ層の出力を保存
with tf.variable_scope('RNN'):
for t in range(maxlen):
if t > 0:
tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(x[:, t, :], state)
outputs.append(cell_output)
output = outputs[-1]
基本的な流れは各時刻 t における出力 cell(x[:, t, :], state) を順次計算しているだけですが、リカレントニューラルネットワークでは過去の値をもとに現在の値を求めるので、過去を表す変数にアクセスできるようにしておかなければなりません。それを実現するために、
with tf.variable_scope('RNN'):
および
if t > 0:
tf.get_variable_scope().reuse_variables()
の2 つの実装が足されています。前者は変数に対して共用の名前(識別子)を付けるために必要になります。これにより、試しに print(outputs) で出力してみると、下記のように RNN/basic_rnn_cell_*/Tanh:0 という名前が各過去の層に付けられていることが分かります※。
※:この中身を見ても分かるように、隠れ層の活性化関数には双曲線正接関数 tanh(x) が使われています。これは BasicRNNCell(activation=tf.tanh) がデフォルトの引数で与えられているためです。一般的にはこのように tanh(x) が用いられることが多いですが、式「 h(t) = f (Ux(t) + Wh(t - 1) + b) 」からも分かるように、他の活性化関数を用いても問題ありません。
[<tf.Tensor 'RNN/basic_rnn_cell/Tanh:0' shape=(?, 20) dtype=float32>, <tf.Tensor 'RNN/basic_rnn_cell_1/Tanh:0' shape=(?, 20) dtype=float32>, ...(中略)..., <tf.Tensor 'RNN/basic_rnn_cell_23/Tanh:0' shape=(?, 20) dtype=float32>, <tf.Tensor 'RNN/basic_rnn_cell_24/Tanh:0' shape=(?, 20) dtype=float32>]
この名前が付いた変数を再利用することを明示しているのが後者になります。ここで得られた output を用いると、「隠れ層 - 出力層」はこれまでと同様下記のように表されます。
V = weight_variable([n_hidden, n_out]) c = bias_variable([n_out]) y = tf.matmul(output, V) + c # 線形活性
以上でモデルの出力をすべて表すことができました。inference() 全体を振り返ると、コードは以下のとおりです。
def inference(x, n_batch, maxlen=None, n_hidden=None, n_out=None):
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.01)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.zeros(shape, dtype=tf.float32)
return tf.Variable(initial)
cell = tf.contrib.rnn.BasicRNNCell(n_hidden)
initial_state = cell.zero_state(n_batch, tf.float32)
state = initial_state
outputs = [] # 過去の隠れ層の出力を保存
with tf.variable_scope('RNN'):
for t in range(maxlen):
if t > 0:
tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(x[:, t, :], state)
outputs.append(cell_output)
output = outputs[-1]
V = weight_variable([n_hidden, n_out])
c = bias_variable([n_out])
y = tf.matmul(output, V) + c # 線形活性
return y
残る loss() と training() ですが、こちらはこれまでとほとんど変わりません。loss() は、今回は2 乗平均誤差関数を用いるので、
def loss(y, t):
mse = tf.reduce_mean(tf.square(y - t))
return mse
となり、training() は Adam を用いる場合は、
def training(loss):
optimizer = \
tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.9, beta2=0.999)
train_step = optimizer.minimize(loss)
return train_step
となります。
以上を用いると、メインの処理で書くモデルの設定に関するコードは下記となります。
n_in = len(X[0][0]) # 1 n_hidden = 20 n_out = len(Y[0]) # 1 x = tf.placeholder(tf.float32, shape=[None, maxlen, n_in]) t = tf.placeholder(tf.float32, shape=[None, n_out]) n_batch = tf.placeholder(tf.int32) y = inference(x, n_batch, maxlen=maxlen, n_hidden=n_hidden, n_out=n_out) loss = loss(y, t) train_step = training(loss)
n_batch は訓練データと検証データとで値が変わるので、placeholder としています。また、実際のモデルの学習もこれまでの実装と同じように記述できます。
epochs = 500
batch_size = 10
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
n_batches = N_train // batch_size
for epoch in range(epochs):
X_, Y_ = shuffle(X_train, Y_train)
for i in range(n_batches):
start = i * batch_size
end = start + batch_size
sess.run(train_step, feed_dict={
x: X_[start:end],
t: Y_[start:end],
n_batch: batch_size
})
# 検証データを用いた評価
val_loss = loss.eval(session=sess, feed_dict={
x: X_validation,
t: Y_validation,
n_batch: N_validation
})
history['val_loss'].append(val_loss)
print('epoch:', epoch,
' validation loss:', val_loss)
# Early Stopping チェック
if early_stopping.validate(val_loss):
break
これでモデルの学習が行えるようになりました。実行してみると、下図のとおり確かにsin 波を学習できていることが確認できます。
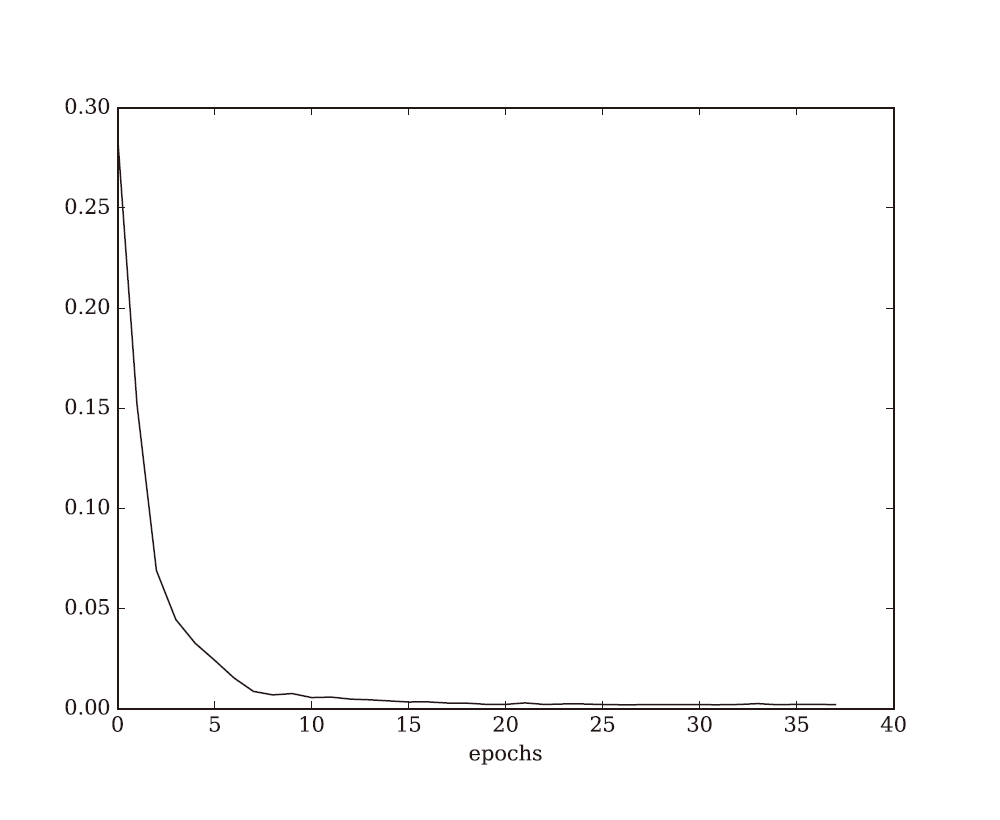
誤差が小さくなり学習が進むことは分かったので、実際に学習したリカレントニューラルネットワークのモデルを使ってsin 波を生成できるかを見てみましょう。元データのはじめの長さ 𝜏 (すなわち1 データ)だけを切り出し 𝜏 + 1 を予測、それをまたモデルの入力に用いて 𝜏 + 2 を予測、という流れを繰り返していくことになります。これにより、2𝜏 + 1 からは完全にモデルの予測値のみが入力となった出力となります。コードでは、まずは、
truncate = maxlen Z = X[:1] # 元データの最初の一部だけ切り出し
によりデータの先頭 𝜏 を切り出します。また、図示のために次の original および predicted を定義しておきます。
original = [f[i] for i in range(maxlen)] predicted = [None for i in range(maxlen)]
この predicted に予測値を随時追加していくことになります。逐次的に予測をするコードは下記になります。
for i in range(length_of_sequences - maxlen + 1):
# 最後の時系列データから未来を予測
z_ = Z[-1:]
y_ = y.eval(session=sess, feed_dict={
x: Z[-1:],
n_batch: 1
})
# 予測結果を用いて新しい時系列データを生成
sequence_ = np.concatenate(
(z_.reshape(maxlen, n_in)[1:], y_), axis=0) \
.reshape(1, maxlen, n_in)
Z = np.append(Z, sequence_, axis=0)
predicted.append(y_.reshape(-1))
出力のサイズを入力のサイズに合わせるために予測値 y_ を加工する処理がやや煩雑に見えますが、行っていることはあくまでも「直近の予測値をまたモデルの入力に用いる」だけです。この結果を、
plt.rc('font', family='serif')
plt.figure()
plt.plot(toy_problem(T, ampl=0), linestyle='dotted', color='#aaaaaa')
plt.plot(original, linestyle='dashed', color='black')
plt.plot(predicted, color='black')
plt.show()
により図示すると、次図が得られます。真のsin 波(図の点線)と若干のずれはあるものの、確かに波の特徴を捉えた時系列データの予測ができていることが分かります。
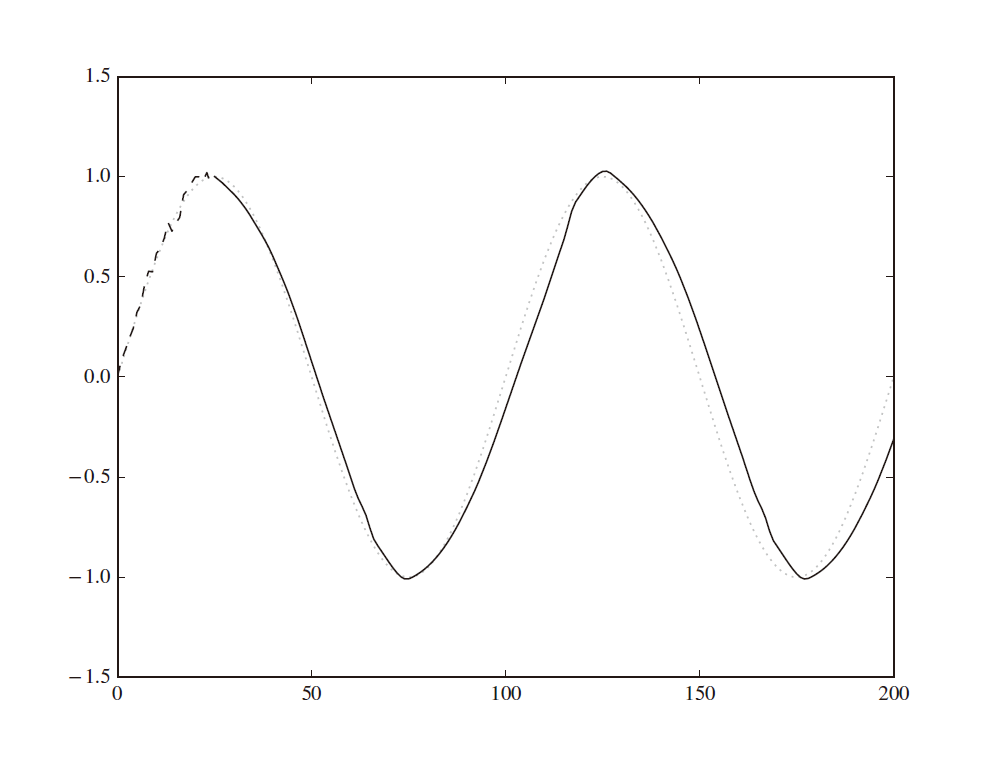
以上、TensorFlowによる実装について紹介しました。次回はKerasによるリカレントニューラルネットワークの実装について解説します。
Manateeではメルマガ会員を募集中!