2017.07.07
第5回 リカレントニューラルネットワークの実装(1)
時系列データの例としてsin波をとりあげます。学習したリカレントニューラルネットワークのモデルを使ってsin波を生成してみましょう。今回の記事では時系列データの準備を行います。

電子書籍『詳解 ディープラーニング』をマナティで発売中!
(上の書籍画像をクリックすると購入サイトに移動できます)
一般的なニューラルネットワークと比べ、リカレントニューラルネットワークはBPTT など式の見た目が複雑な箇所はあるものの、ライブラリを使う際はモデルの出力部分だけを記述すれば最適化に相当する処理はライブラリが担ってくれるので、特段難しいわけではありません。TensorFlow、Keras それぞれの実装について順番に見ていきましょう。予測に用いるデータは下記の式で表されるノイズ入りのsin 波ですが、
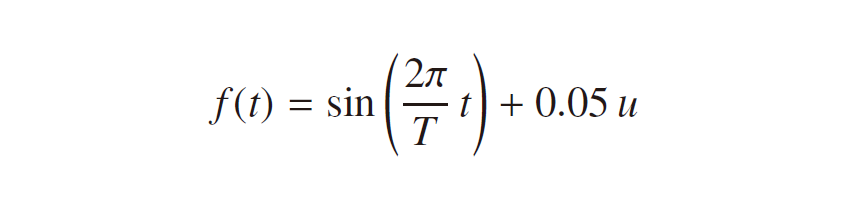
これを生成するコードは下記のようになります。
def sin(x, T=100):
return np.sin(2.0 * np.pi * x / T)
def toy_problem(T=100, ampl=0.05):
x = np.arange(0, 2 * T + 1)
noise = ampl * np.random.uniform(low=-1.0, high=1.0, size=len(x))
return sin(x) + noise
これにより、例えば
T = 100 f = toy_problem(T)
とすると、t = 0, ..., 200 におけるデータが得られます。ここで得られた f を全データセットとして実験することにします。
時系列データの準備
具体的な実装に入る前に、「sin 波の予測」について課題を明確にしておきましょう。ここで言う予測とはすなわち、時刻 1, ..., t までのノイズ入りsin 波の値 f (1), ..., f (t) が与えられたとき、時刻 t + 1 の値 f (t + 1) を予測することができるか、ということを指します。もし予測値 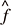 (t + 1) が適切であれば、それを用いて (t + 2), ..., (t + n), ... と、再帰的に遠い未来の状態も予測できるようになります。
(t + 1) が適切であれば、それを用いて (t + 2), ..., (t + n), ... と、再帰的に遠い未来の状態も予測できるようになります。
モデルの入力は、理想的には過去すべての時系列データの値 f (1), ..., f (t) をそのまま用いることですが、BPTT における計算の都合上、今回は 𝜏 = 25 で区切ることにします。これにより長期の時間依存に関する情報はデータから抜け落ちてしまうものの、データセットとしては、
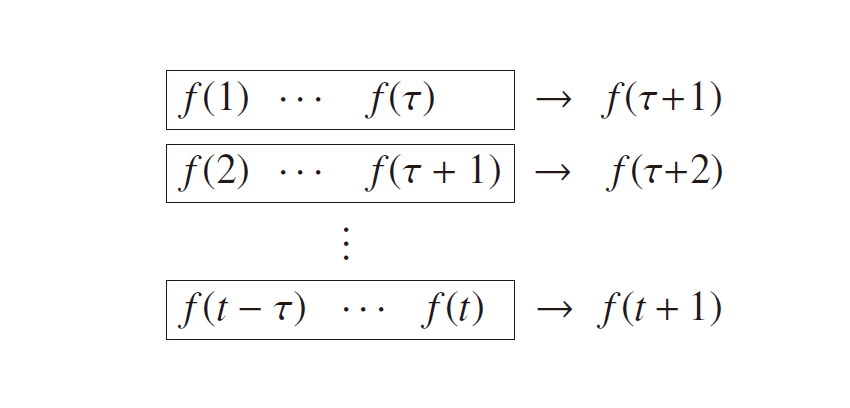
の t - 𝜏 + 1 個になるので、時間 𝜏 に含まれる時系列情報の学習が進めやすくなります。先ほどの全データ f に対して、この 𝜏 ごとにデータを分割していく実装が下記になります。
length_of_sequences = 2 * T # 全時系列の長さ
maxlen = 25 # 1 つの時系列データの長さ
data = []
target = []
for i in range(0, length_of_sequences - maxlen + 1):
data.append(f[i: i + maxlen])
target.append(f[i + maxlen])
ここで、maxlen が 𝜏 に相当します。また、data が予測に用いる長さ 𝜏 の時系列データ群であり、target が予測によって得られるべきデータ群になります。
さて、モデルに data および target のデータ群を与えるには、ここからさらに1 つの時刻ごとにデータを区切っていく必要があります。
今回はsin 波の値のみがデータになるので、各入力は 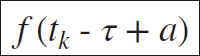 と1 次元ですが、より複雑な問題ではこれが2 次元以上になることもあるので注意してください。すなわち、データ数を N、入力の次元数を I (=1) とすると、モデルに用いる全入力 X は次元が (N, 𝜏, I ) となります。コードでは reshape() を用いて下記のように書き表すことができます。
と1 次元ですが、より複雑な問題ではこれが2 次元以上になることもあるので注意してください。すなわち、データ数を N、入力の次元数を I (=1) とすると、モデルに用いる全入力 X は次元が (N, 𝜏, I ) となります。コードでは reshape() を用いて下記のように書き表すことができます。
X = np.array(data).reshape(len(data), maxlen, 1)
同様に、target についてもモデルの出力の次元数(= 1)に対応できるように変形する必要があるので、
Y = np.array(target).reshape(len(data), 1)
とします。これらは下記のコードと等価です。
X = np.zeros((len(data), maxlen, 1), dtype=float)
Y = np.zeros((len(data), 1), dtype=float)
for i, seq in enumerate(data):
for t, value in enumerate(seq):
X[i, t, 0] = value
Y[i, 0] = target[i]
これで時系列データの準備ができました。実験のために、これまで同様、訓練データ・検証データに分割しておきます。
N_train = int(len(data) * 0.9)
N_validation = len(data) - N_train
X_train, X_validation, Y_train, Y_validation = \
train_test_split(X, Y, test_size=N_validation)
次回以降はTensorFlowとKerasによるsin波の学習と予測について解説していきます。
Manateeではメルマガ会員を募集中!