2017.06.23
第3回 過去の隠れ層
書籍『詳解 ディープラーニング』の第5章では時系列データの扱いに特化したモデル:リカレントニューラルネットワークについて考えていきます。本連載ではニューラルネットワークに「時間」という概念を取り込んだモデルと、TensorFlow、Kerasの実装について解説していきます。

電子書籍『詳解 ディープラーニング』をマナティで発売中!
(上の書籍画像をクリックすると購入サイトに移動できます)
時系列データを予測する、すなわち時間の概念をニューラルネットワークに取り入れるには、過去の状態をモデル内で保持しておかなければなりません。現在に対する過去からの(目に見えない)影響を把握しておかなければならないので、これを「過去の」隠れ層として定義する必要があります。この考え方を最も単純に表したグラフィカルモデルが下図になります。層自体は「入力層 - 隠れ層 - 出力層」と一般的なニューラルネットワークと変わりませんが、時刻 t における入力 x(t) に加え、時刻 t – 1 における隠れ層の値 h(t – 1) を保持しておき、それも時刻 t における隠れ層に伝える点がこれまでと大きく異なります。時刻 t の状態を t – 1 の状態として保持しフィードバックさせるので、過去の隠れ層の値 h(t – 1) には再帰的に過去の状態がすべて反映されていることになります。これがリカレント(=再帰型)ニューラルネットワークと呼ばれる理由です※1。
※1:これに対し、入力から出力までが一方向のネットワークをフィードフォワードニューラルネットワーク(feedforward neural networks)と呼びます。
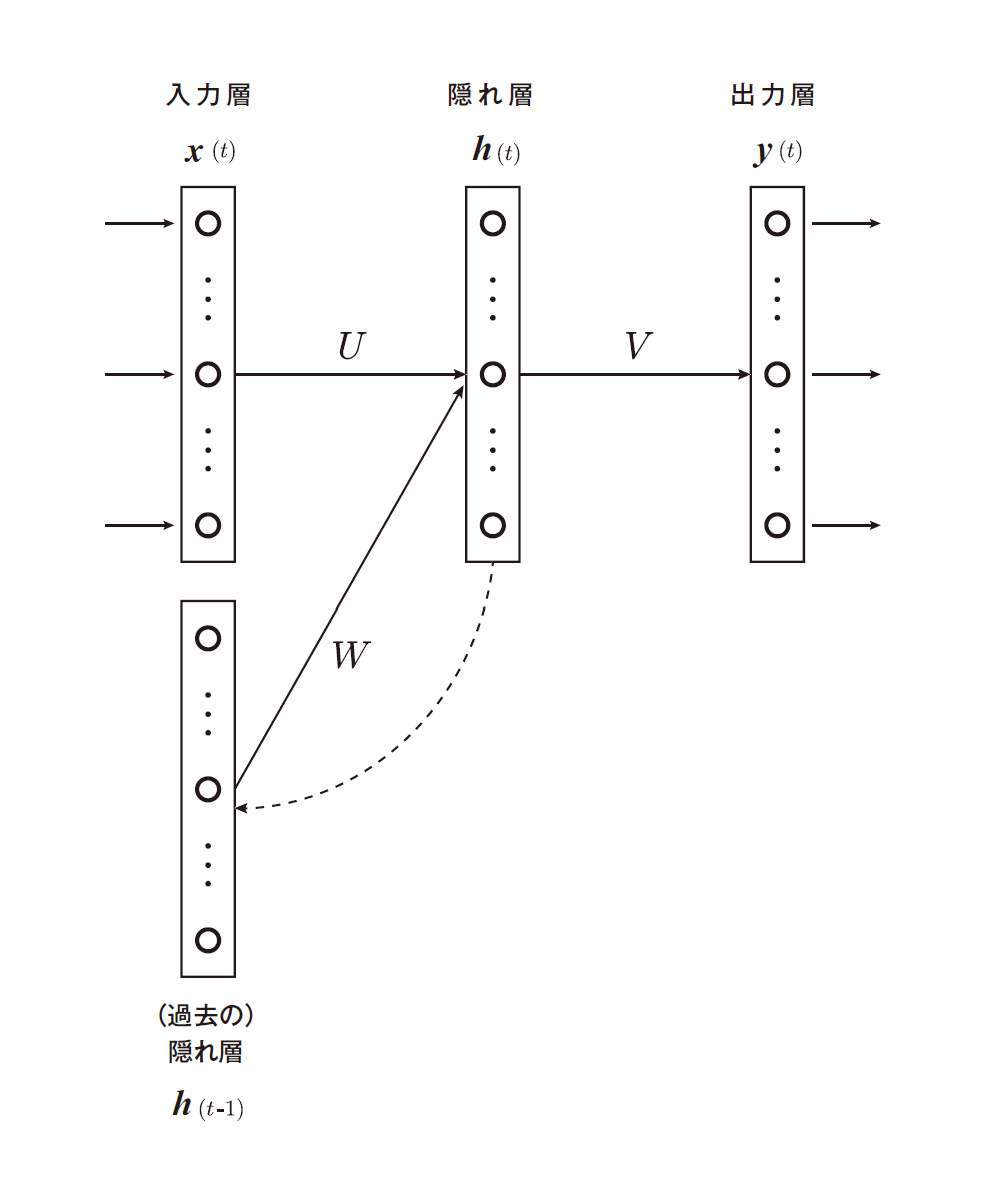
過去の隠れ層が加わったものの、モデルの出力を表す式は特別難しくなるわけではありません。素直に式を書いていくと、まず隠れ層は
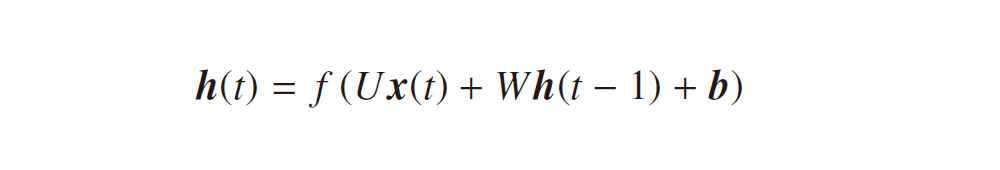
と表せ、また出力層は
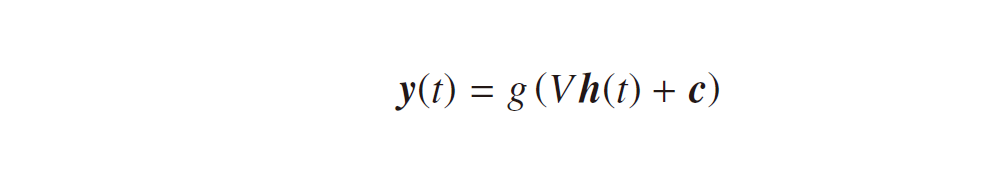
となります。ここで、f (・), g (・) は活性化関数、b, c はバイアスベクトルです。隠れ層の式に過去から順伝播してくる項 Wh(t – 1) が付きますが、それ以外は一般的なニューラルネットワークと違いはありません。なので、各モデルのパラメータも誤差逆伝播法により最適化できるはずです。誤差関数を E := E(U, V, W, b, c) として、それぞれのパラメータに対する勾配を考えてみましょう。これまで同様、隠れ層、出力層の活性化前の値をそれぞれ下記の p(t), q(t) で定義しておきます。
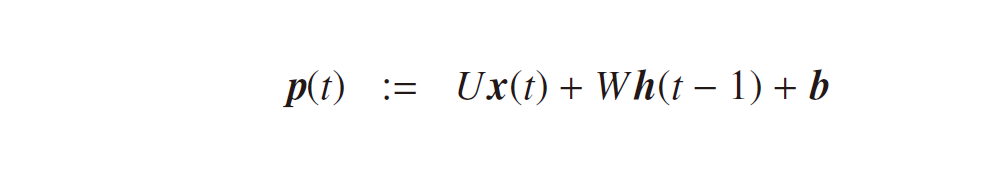
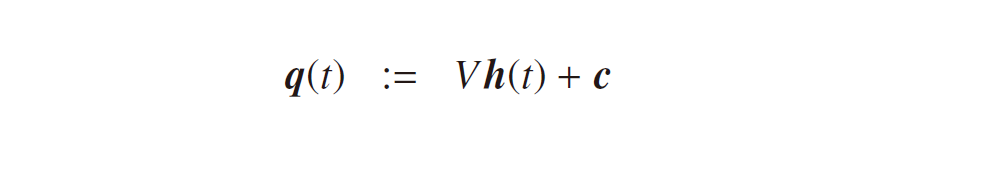
すると、隠れ層、出力層における誤差項

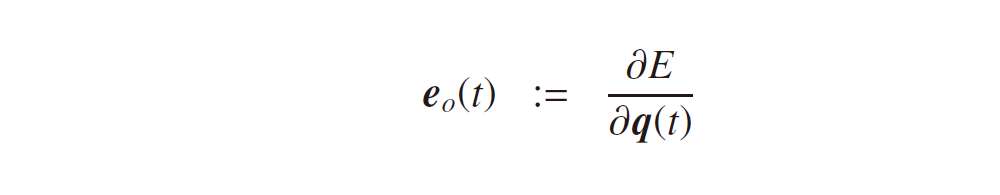
に対して、
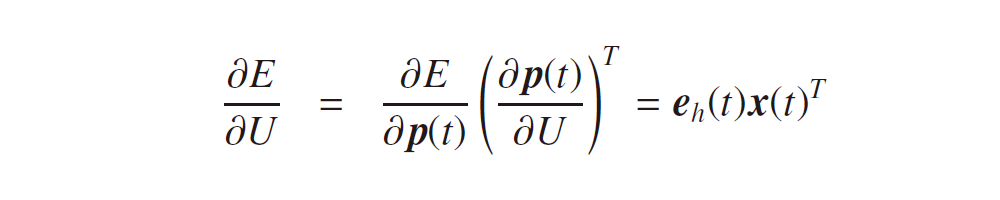
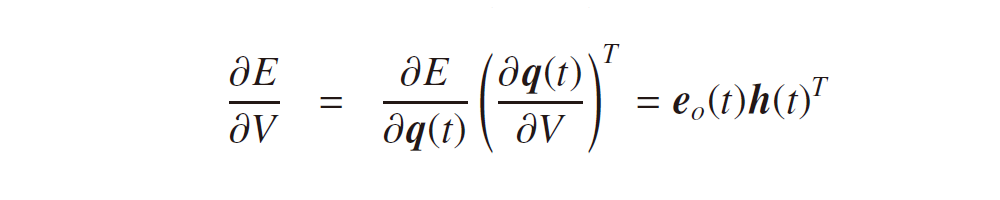
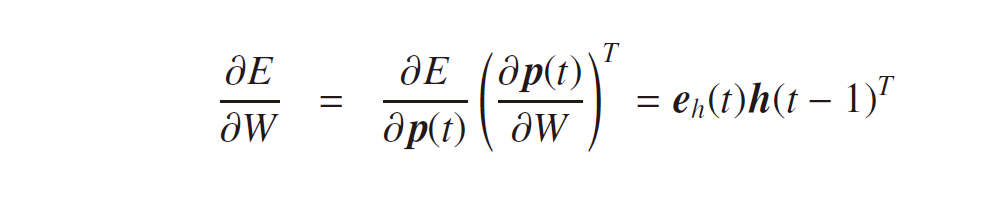

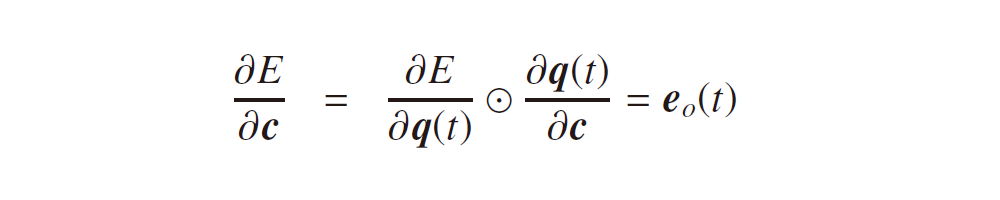
が求められ、式3-5および式3-6の誤差項のみを考えればよいことが分かります。過去の隠れ層という概念が追加されても、モデルの最適化を考える上でのアプローチは変わりません。
ただし、誤差関数 E については、特にsin 波の予測を考える場合に少し注意が必要です。これまで誤差関数として用いてきた交差エントロピー誤差関数は、出力層における活性化関数 g (・) がソフトマックス関数(あるいはシグモイド関数)において求められる形でしたが、sin 波の予測では、出力が確率ではなくそのままの値を用いる必要があるので、g(x) = x すなわち式3-2は
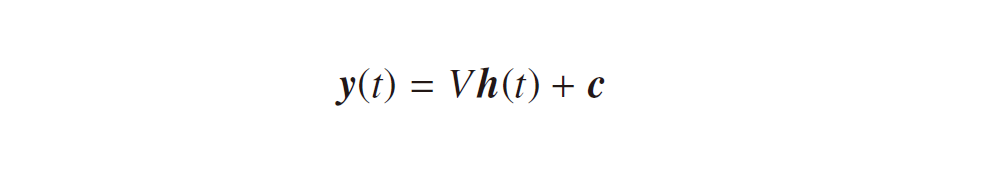
という線形活性の式になります。このときの誤差関数について考えなければなりません。とは言うものの、これは難しく考える必要はなく、誤差関数は最小化すべき「モデルの予測値 y(t) と正解の値 t(t) との誤差」を表す関数だという前提を踏まえると、例えば

という2乗誤差関数(squared error function)を与えればよいことになります※2 ※3。
※2:より厳密に書くと、この式3-13は
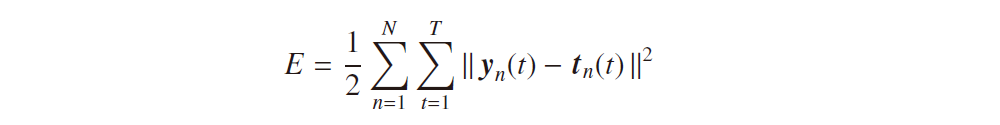
となりますが、両辺を N や T で割っても最適解に変化はないため、これらで割ったものを改めて E と置き直したとすると、E は2乗平均誤差関数(mean squared error function)と見ることもできます。
※3:このアプローチからも分かるように、交差エントロピー誤差関数を用いていたモデルにおいても2 乗(平均)誤差関数を用いることは可能です。
Manateeではメルマガ会員を募集中!