2017.06.16
第2回 単純パーセプトロン(2)
書籍「詳解ディープラーニング」の第3章では、ディープラーニングの要である「ニューラルネットワーク」について学んでいきます。前回の記事で解説した「単純パーセプトロン」のPythonでの実装について解説します。

電子書籍『詳解 ディープラーニング』をマナティで発売中!
(上の書籍画像をクリックすると購入サイトに移動できます)
実装
パーセプトロンの式をベクトルを用いて表すことには、数式として扱いやすくなるという利点がありました。これに加え、実装上も、ベクトルと配列を対応付けることによってより直観的な実装を行えるようになるという利点があります。簡単な例で見ていくことにしましょう。これまでは論理ゲートの入力 0, 1 の組み合わせの分類を考えてきましたが、より一般化して、2 種類の正規分布に従うデータの分類を考えてみることにします。分類結果を可視化できるように、今回は入力のニューロン数を 2 とします。
ニューロンが発火しないデータは平均値が 0、発火するデータは平均値が 5 とし、それぞれ 10ずつデータがあるとします。このデータを生成するコードは下記になります。
import numpy as nprng = np.random.RandomState(123)d = 2 # データの次元N = 10 # 各パターンのデータ数mean = 5 # ニューロンが発火するデータの平均値x1 = rng.randn(N, d) + np.array([0, 0])x2 = rng.randn(N, d) + np.array([mean, mean]) |
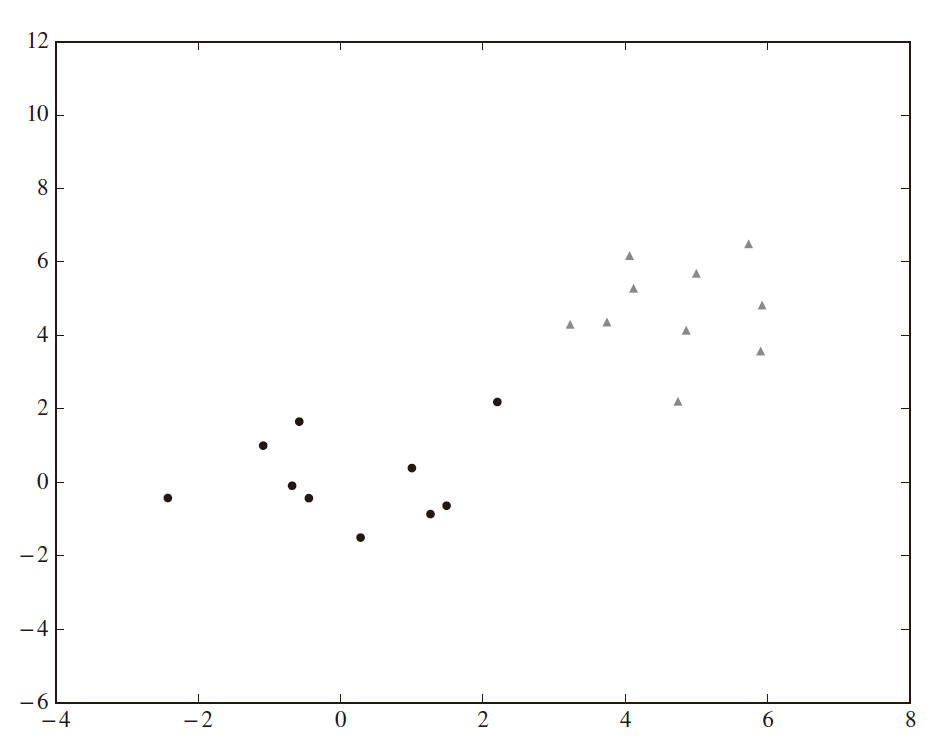
np.random.RandomState() によって、乱数の状態を定めています。実験では、正規分布に従うデータを複数得るためにデータをランダムに生成する必要がありますが、何も工夫をしないと、毎回生成されるデータの値が異なってしまいます。これでももちろん実験はできますが、毎回データの値が違うと、得られる結果もばらばらになってしまうため、得られた結果が本当に正しいのか評価しにくくなってしまいます。毎回「同じランダム状態」を作り、同じ条件下で実験結果を比較・評価できるようするための実装が必要となります。生成したデータ x1 および x2 を図示してみると、下図のような分布になっていることが確認できます。この生成した2 種類のデータをまとめて処理するために、x1、x2 をひとまとめにしておきます。
x = np.concatenate((x1, x2), axis=0) |
では、生成したデータをパーセプトロンで分類してみましょう。モデルのパラメータは重みベクトル w およびバイアス b なので、まずはこれを初期化します。
w = np.zeros(d)b = 0 |
出力は y = f (wTx + b) で表されました。これを関数で定義すると、
def y(x): return step(np.dot(w, x) + b)def step(x): return 1 * (x > 0) |
となります。この step(x) がステップ関数を表します。このように、ほぼ数式の見た目どおりの記述となるので、直観的に実装できるのが分かるかと思います。
パラメータを更新するには、正しい出力値が必要になるので、これを下記のように定義しておきます。
def t(i): if i < N: return 0 else: return 1 |
先ほど定義した x は、最初の N 個にニューロンが発火しないデータ x1 が、残りの N 個にニューロンが発火するデータ x2 が入っているので、このように実装できます。これで学習に必要な値(関数)は揃ったので、誤り訂正学習法を実装してみましょう。
誤り訂正学習法では、すべてのデータが正しく分類されるまで学習を繰り返します。なので、大枠としては下記のようになるはずです。
while True: # # パラメータの更新処理 # if ' データがすべて正しく分類されていたら': break |
この パラメータの更新処理 の部分に、w, b の更新式、およびデータがすべて正しく分類されているかの判別ロジックを実装することになります。これらを実装すると、下記のようになります。
while True: classified = True for i in range(N * 2): delta_w = (t(i) - y(x[i])) * x[i] delta_b = (t(i) - y(x[i])) w += delta_w b += delta_b classified *= all(delta_w == 0) * (delta_b == 0) if classified: break |
delta_w および delta_b はそれぞれ数式の Δw, Δb に対応しています。ここも数式どおりなので詳しい説明は不要でしょう。classified はデータがすべて分類されているか判別するためのフラグであり、
classified *= all(delta_w == 0) * (delta_b == 0) |
の部分で、20 個のデータのどれか1 つでも Δw ≠ 0 または Δb ≠ 0 だったら classified = 0 となるので、また学習を繰り返すことになります。
以上を実行すると、w: [ 2.14037745 1.2763927 ]、b: -9 という結果が得られるので、x =(x1 x2)T とすると、
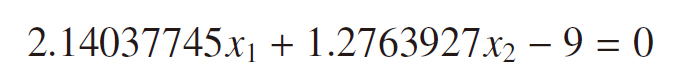
が、ニューロンが発火するかどうかの境界線になることが分かります。この直線を図示すると、下図となることが確認できます。
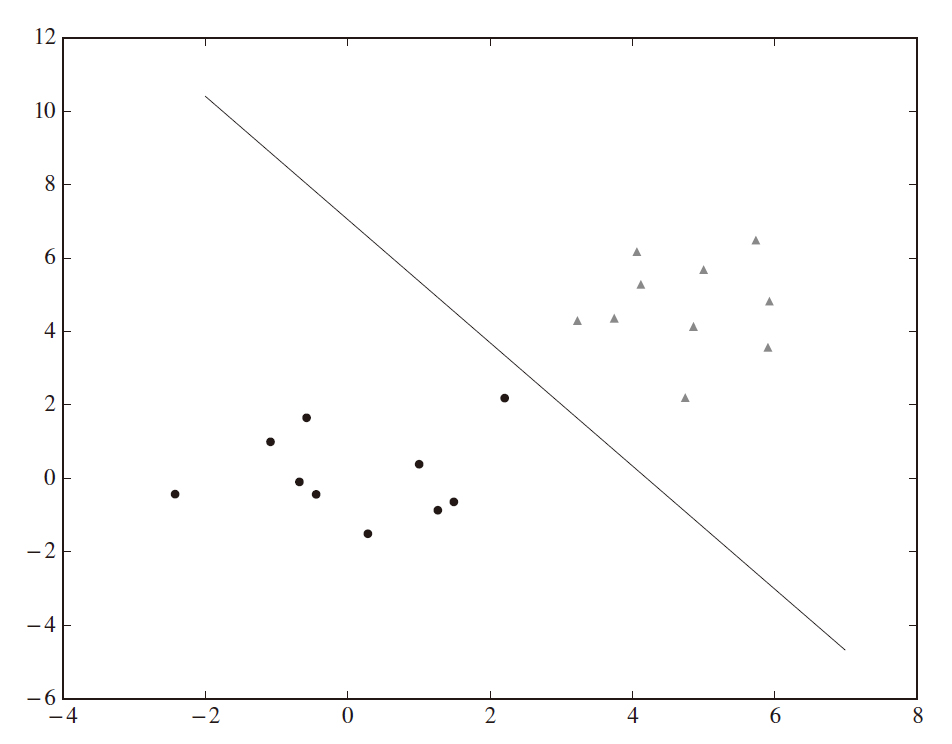
よって、例えば (0, 0) だとニューロンは発火せず、 (5, 5) だとニューロンは発火するはずです。実験してみると、
print(y([0, 0]))print(y([5, 5])) |
の結果がそれぞれ 0、1 になることが確認できます。
単純パーセプトロンはニューラルネットワークの中で一番単純なモデルなので、TensorFlow や Keras などのライブラリを使わずとも簡単に実装できてしまいます。今回ははじめて数式を実装に落とし込んだので丁寧に見ていきましたが、モデルが複雑になっても、今回のように順を追えば理論から実装までスムーズに進めるはずです。以降、徐々に扱うモデルが複雑になっていきますが、しっかりと理解していきましょう。
