2016.08.24
第2回 rvestによるWebスクレイピング
データ分析の現場においては、使用するデータをWebから取得してこなければならないことが多々あります。本記事ではマイナビBOOKSに対してRを用いたWebスクレイピング(Scraping)を行い、"コンピュータ書籍 人気ランキング100位まで"の情報を取得してみます。

1. はじめに
データ分析を行うためには当然その元となるデータが必要です。 そのデータが、データベースに既に保存してある場合は、 Rから接続可能なデータベースドライバを経由して、そのままSQLなどを実行すれば問題ありませんが、欲しいデータがWebページ上にあり、かつ、そのサイトがAPIを提供してない場合には、 何らかの手段を用いてデータを取得しなければなりません。
もちろん、必要なデータの数があまり多くない場合には、Webページからコピー&ペーストすることでデータを抽出することもできますが、 データ分析の現場で使用するデータは何百、何千ページからなるWebページから取得してこなければならないことが多々あります。 そこで本記事ではRを用いて、Webページからのデータ取得作業を自動化するための技術(Scraping, スクレイピング)について紹介します。
2. Webスクレイピング(入門編)
では、早速Rからスクレイピングを実行してみましょう。 そのためにはggplot2やdplyrパッケージでおなじみのHadley Wickhamが開発したrvestパッケージ使うのが便利です。 このパッケージには、Webページから情報を抽出する作業を簡略化してくれる機能が多数あります。 本記事ではこのrvestパッケージを使用していきますので、まずはそのインストールを行います。
installed.packages("rvest")
次にパッケージを読み込み、read_html()1を用いてHTMLファイルをRのオブジェクト (正確にはxml_document, xml_nodeクラスのオブジェクト)としてダウンロードしましょう。 ここではみんなのRというR言語の入門書の情報を例に説明します。
# パッケージの読み込み
library("rvest")
# "みんなのR"のデータ取得
r_for_everyone <- read_html("https://book.mynavi.jp/ec/products/detail/id=39763")
作成されたオブジェクトの中身を調べるには以下のような関数を用いることができます。 この出力は相当な量あるので、紙面の都合上、ここではその結果の出力は割愛しました。
html_structure(r_for_everyone) as_list(r_for_everyone) xml_children(r_for_everyone) xml_children(r_for_everyone)[[2]] xml_contents(xml_children(r_for_everyone)[[2]])
さて、このr_for_everyoneオブジェクトから、欲しい情報を抽出するためには、 欲しい情報がHTML構造のどこに格納されているか知らなければなりません。 そのためには、特にGoogle Chromeのブラウザの場合、ディベロッパーツールを用いるのが便利です。 これはブラウザから「その他のツール → ディベロッパーツール」と辿り、アクセスすることが可能です。2
なお、Firefoxなど、その他のブラウザについても似たような機能がありますので、そちらを使っても全く問題ありません。
ここでは、書籍のタイトルを抽出することにしましょう。 ディベロッパーツールの画面をみると、どうやらタイトルはclass属性がtitleのh1タグに入っているようです。

指定したあるHTMLノードを抽出するためにはhtml_nodes()を用います。 なお、対象とするHTMLノードが1つしかないことが確実な場合は、関数名から最後のsを抜いたhtml_node()でも構いません。
html_nodes()において、タグや属性を指定するためには以下のルール(CSSセレクタ)に基づいて記述します。
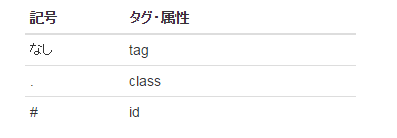
今回の場合「class属性がtitleとなるh1タグ」を抽出すればよいので、h1.titleと指定することになります。
# class属性がtitleとなるh1タグ title_nodes <- html_nodes(r_for_everyone, "h1.title")
何個のノードが取得できたのかをチェックしてみましょう。
length(title_nodes)
[1] 1
1 となったので、複数あることは特に気にせずこのデータを扱えば良いようです。 もし該当するノードが複数あった場合には、どれが所望のデータなのかを見極め、そこだけを使うようにする必要があります。
ノードに関連した属性などの情報については、html_text(), html_name(), html_attr(), html_children(), html_table()などの関数を用いて抽出することができます。 では、先ほどの取得した書籍タイトルノード(h1.title)の中身の文字列をhtml_text()を用いて抽出してみましょう。3
text <- html_text(title_nodes) print(text)
[1] "みんなのR データ分析と統計解析の新しい教科書"
無事にタイトルである「みんなのR データ分析と統計解析の新しい教科書」という文字列を取得することができました。 このように基本的には
・取得したいページに対しread_html()を適用し、必要なHTMLを読み込み
・取得したRオブジェクトに対しhtml_nodes()を適用し、必要なノードを取得し、
・取得したノードに対しhtml_text(), html_attr()などを適用し、必要な情報を取得する
という流れになります。
Manateeではメルマガ会員を募集中!


