2016.08.25
第3回 機械学習のためのベイズ最適化入門
応用範囲が広く幅広い視点からの説明になりがちなベイズ最適化について、本記事では機械学習のハイパーパラメータ探索に利用することに限定して解説します。

1. はじめに
最近、ベイズ最適化という手法が注目を集めています。 ベイズ最適化 (Bayesian Optimization) とは、形状がわからない関数 (ブラックボックス関数) の最大値 (または最小値) を求めるための手法です。 ベイズ最適化についての入門記事は Web 上にすでにいくつかありますが、ベイズ最適化は応用範囲が広く、入門記事は様々な応用に向けた幅広い視点からの説明になりがちです。 本記事では、機械学習ユーザに向けて、ベイズ最適化を機械学習のハイパーパラメータ探索に利用することに限定して説明します。 これにより、機械学習に対して、ベイズ最適化がどのように利用できるのかを分かりやすく解説したいと思います。
2. ハイパーパラメータ探索
機械学習の手法には、必ずと言ってよいほどハイパーパラメータが存在します。 ハイパーパラメータとは、機械学習手法が持つパラメータの中で、データからの学習では決まらないパラメータのことを言います。 例えば、サポートベクターマシン (SVM) における、誤分類に対するペナルティの大きさを制御するパラメータや、ランダムフォレストにおける、個々の決定木に使う特徴量の数などです。 これらのパラメータは、データを学習する前にあらかじめ決めておかなければなりません。
このようなハイパーパラメータは、これぐらいの値が良いなどの知見がある場合にはそれを使うこともありますが、精度の良い機械学習モデルを作成したい場合には、いくつかのハイパーパラメータを使って実際にモデルを学習してみて、一番精度が良くなるものを使うということが行われます。
このように、機械学習で良い精度を出すために、良いハイパーパラメータの値を探すことを、ハイパーパラメータ探索と言います。
3. グリッドサーチ
機械学習のハイパーパラメータ探索の方法として、グリッドサーチという手法がよく使われます。 グリッドサーチとは、ハイパーパラメータの探索空間を格子状 (グリッド) に区切り、交点となるハイパーパラメータの組み合わせについて、すべて調べるという方法です。
具体的な例を見てみましょう。 いま、機械学習手法として、RBF カーネルを用いた SVM を使用するとします。 RBF カーネルを用いた SVM には2つのハイパーパラメータがあります。 誤分類に対するペナルティの大きさを制御する C と、RBF カーネルのバンド幅を制御する gamma です。
これらのハイパーパラメータについて、C の探索範囲を [10-4, 105], gamma の探索範囲を [10-5, 104] とし、10 × 10 の次のような格子を作成します。
1 2 3 4 5 6 | C_range <- 10 ^ seq(-4, 5, length.out = 10)gamma_range <- 10 ^ seq(-5, 4, length.out = 10)grid <- expand.grid(C = C_range, gamma = gamma_range)library(ggplot2)ggplot(grid, aes(x = C, y = gamma)) + geom_point() + scale_x_log10() + scale_y_log10() |
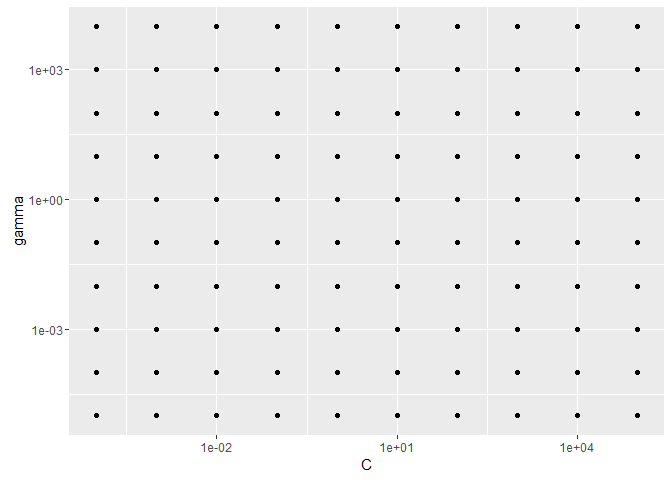
これら1つひとつの格子点に対して、モデルを学習していきます。 今回は、有名な iris データセットを使って「あやめの品種」を分類するモデルを作ることにします。 SVM のグリッドサーチは、e1071 パッケージの tune.svm() によって簡単に実行できます。 ここでは、モデルの評価方法として 10-fold 交差検証を使っています。
1 2 3 4 5 6 7 8 9 10 11 12 13 | library(e1071)set.seed(71)# SVM に対するグリッドサーチの実行tune_result <- tune.svm(Species ~ ., data = iris, scale = TRUE, gamma = gamma_range, cost = C_range, tunecontrol = tune.control(sampling = "cross", cross = 10))# 結果の表示ggplot(tune_result$performances, aes(x = cost, y = gamma)) + geom_point(aes(size = 1-error)) + scale_x_log10() + scale_y_log10() + xlab("C") + guides(size = guide_legend(title = "正答率", reverse = TRUE)) |
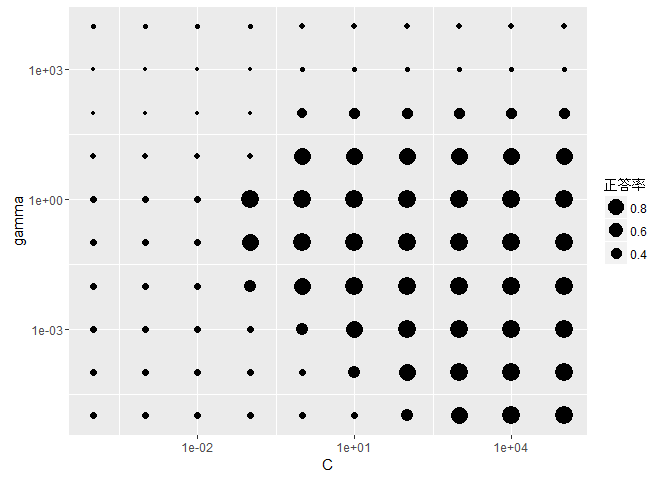
上の図では、正答率の高いものほど大きい丸で表しています。 このように、すべての格子点 (ハイパーパラメータの組み合わせ) でモデルを作り、 最も良い評価値となるハイパーパラメータを選択するというのがグリッドサーチです。
1 2 3 4 | # 最適なハイパーパラメータtune_result$best.parameters# そのときの正答率1 - tune_result$best.performance |
今回のグリッドサーチで求まった最適なハイパーパラメータは C = 10, gamma = 0.1 であり、そのときの正答率は 0.973 でした。
4. ベイズ最適化
ベイズ最適化を使うと、機械学習のハイパーパラメータ探索を効率よく行うことができます。
上記のグリッドサーチの例において、次の図のように4つの点で評価値が分かっているとします。
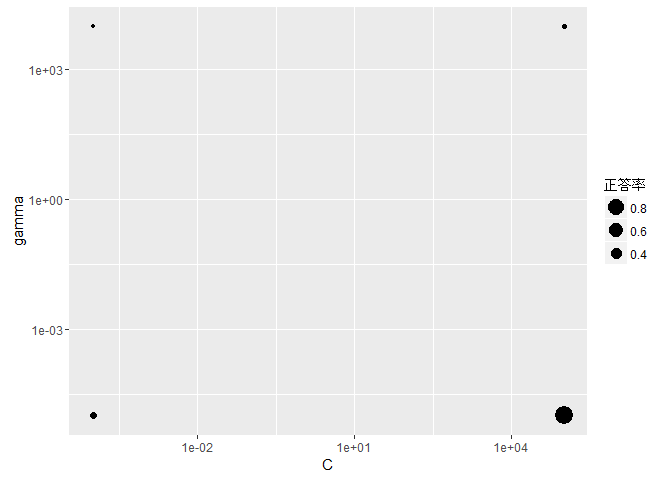
このとき、最大値を効率よく見つけるためには次にどこを調べたらよいでしょうか? なんとなく右下あたりを調べた方が良さそうだと感じないでしょうか。 また、真ん中あたりがスカスカなので、このあたりを調べてみないとよく分からないと思うのも自然だと思います。
まずは真ん中あたりを1つ評価し、評価値が小さければ右下を重点的に調べればよく、大きければ探索範囲を広げたほうがいいというふうに、1つ評価を行っては次にどこを調べるかを決めるというような探索を、人間は自然に行うことができます。
これと同じ様に、すでに持っている情報から、次にどの点を調べた方がいいかを判断し、実際に評価を行い、その結果を次の判断に利用するということを自動的に行ってくれるのがベイズ最適化です。 これにより、すべての点を評価しなくても、効率的に最適値にたどり着くことができます。
実際に、上記の例において、グリッドサーチではなく、ベイズ最適化を使ってハイパーパラメータ探索を行ってみます。
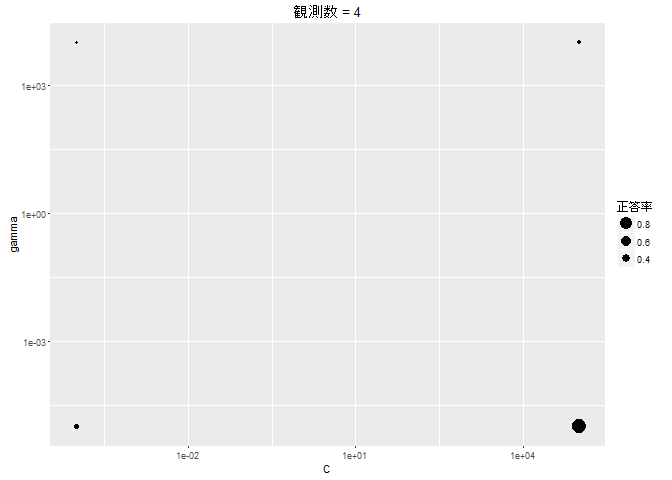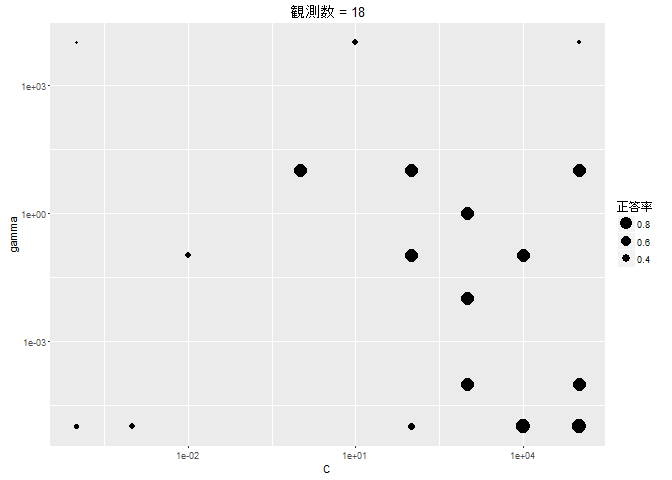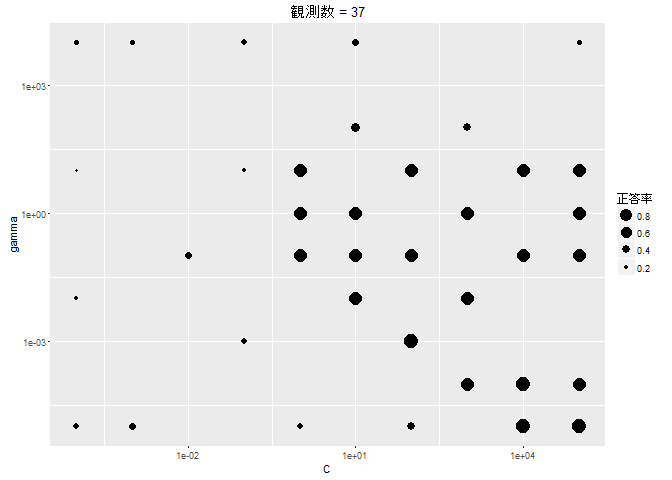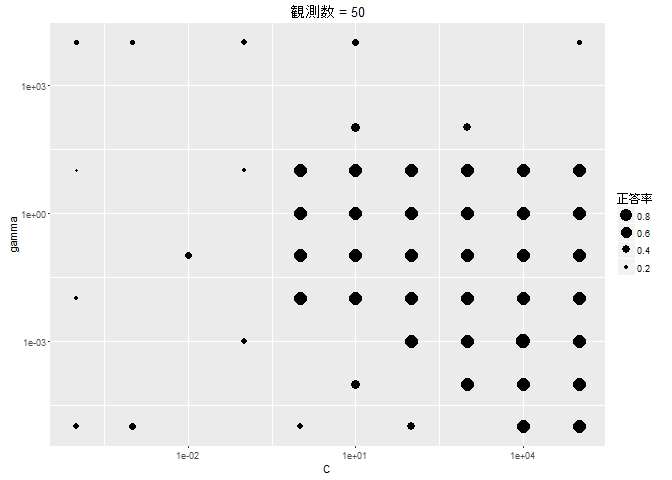
このように、ベイズ最適化では、評価値が大きくなりそうなところを重点的に観測し、逆に小さくなりそうなところは観測しません。 また、あまり観測されていないエリアに対して時々観測を行い、局所解におちいるのを防ぐ動きをします。 今回、10 × 10 = 100 のグリッドに対して、50 回しか評価を行っていませんが、見事に最適値にたどり着いています。 グリッドサーチに比べて、ベイズ最適化ではモデルを評価する回数を半分に抑えることができました。



