2018.11.12
機械学習で遊ぼう! APIサービスやTensorFlowを使ったサンプルレシピ集
第17回 TensorFlow.jsで「感情」を認識してみよう
JavaScriptライブラリ「TensorFlow.js」で機械学習がより身近に利用することができる様になりました。今回はWebカメラを通して「感情」をリアルタイムで判別するアプリケーションをつくってみましょう。

記事中の女性モデルは、フリー素材アイドルMika+Rikaの素材を使用させていただきました。
・フリー素材アイドルMika+Rika:mika-rika-free.jp
1.環境
前回「TensorFlow.jsで『じゃんけん』を判別してみよう」のアプリケーションと同様に学習はPython 3とKerasを使用し、学習済みモデルを使った推論はNode.jsとTensorFlow.jsを使用します。1
ライブラリのバーションは以下の通りです。
- Python 3.5.2 / keras 2.1.5 / tensorflow 1.7.0 / tensorflowjs 0.1.1
- Node.js 8.11.1 / tensorflow.js 0.12.0
Pythonの実行環境はGPUが利用できる環境が望ましいです。ハードウェアがGPUを利用できない場合、クラウドサービスGoogle Colabを利用してください。2
2. サンプルアプリのダウンロード方法
今回作成するアプリは以下のGitHubレポジトリに公開しています。
[github.com/PonDad/manatee/2_emotion_recognition-master/]
こちらに独自データを学習するための「python」フォルダと学習済みモデルを使用したアプリケーションを実行する「nodejs」フォルダが格納されています。
以下の通り実行すればアプリケーションを試すことができます。
$ git clone https://github.com/PonDad/manatee.git
$ cd manatee/2_emotion_recognition-master/nodejs/
$ npm install
$ npm start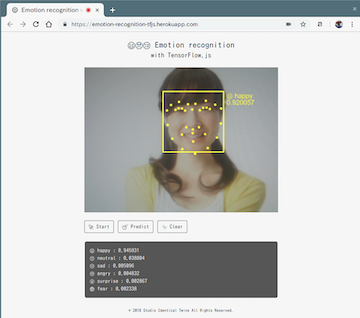
[フリー素材アイドルMika+Rika]
「Start」ボタンで学習済みモデルをTensorFlow.jsを使って読み込み、Webカメラを起動させます。
「Predict」ボタン(推論ボタン)でtracking.jsを使い、Webカメラの画像から顔部分をクリップしcanvas要素へと変換します。画像はTensorFlow.jsを使いテンソル形式へ変換し、学習済みモデルを使って7クラスの分類を行います。
終了する際は「Clear」ボタンで画面をリロードします。
TensorFlow.jsを実行するブラウザはGoogle Chromeが一番最適化されています。
3. 学習済みモデルの取得
感情認識の学習済みモデルは公開レポジトリoarriaga/face_classification - GitHub より取得します。
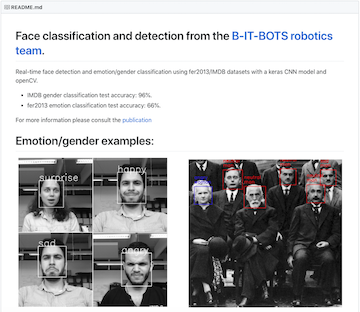
こちらはドイツにあるBonn-Rhein-Sieg 応用科学大学の研究グループが公開しているレポジトリです。ロボティックス分野の顔認識や音声認識などを使った自律システムを専門に研究しているようですね。
性別認識と感情認識の学習済みモデルがMITライセンスで公開されており、デモプログラムを使い画像の認識結果を取得することができます。
レポジトリの中で性別認識はIMDBデータセット、感情認識は fer2013データセットを使用しています。独自のデータセットを用いての学習も可能です。
感情認識のfer2013データセットChallenges in Representation Learning: Facial Expression Recognition Challenge - KaggleはKaggleのコンペ対象にもなっています。
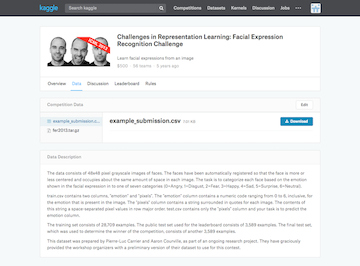
CSVデータには画像サイズ48x48ピクセルの白黒画像(色調0~255の1チャンネル画像)3,589枚分のデータが収められています。
ラベルが0~6になっており、(0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral)7つの感情分類に分ける分類問題です。
4. TensorFlow.jsモデルへのコンバート
前回と同じく、学習したモデルをTensorFlow.jsで読み込み可能な形式に変換します。
前回と異なり、今回は学習済みモデルからTensorFlow.jsモデルへコンバートします。「pythonフォルダ」のpredict.pyを使い実際にやってみましょう。
predict.py より抜粋
import numpy as np from keras.models import load_model from keras.preprocessing.image import ImageDataGenerator from keras.preprocessing import image
classes = ({0:'angry',1:'disgust',2:'fear',3:'happy',
4:'sad',5:'surprise',6:'neutral'})
image_path = './images/happy.jpg'
img = image.load_img(image_path, grayscale=True , target_size=(64, 64)) img_array = image.img_to_array(img) pImg = np.expand_dims(img_array, axis=0) / 255 model_path = './trained_models/fer2013_mini_XCEPTION.110-0.65.hdf5' emotions_XCEPTION = load_model(model_path, compile=False) prediction = emotions_XCEPTION.predict(pImg)[0]
top_indices = prediction.argsort()[-5:][::-1]
result = [(classes[i] , prediction[i]) for i in top_indices]
for x in result:
print(x)
まずは学習済みモデルを使い、顔画像を元に推論をします。学習済みモデルは上記レポジトリよりfer2013_mini_XCEPTION.110-0.65.hdf5を使わせてもらいます(ローカルPCのGPUで学習させた場合NVIDIAのGTX1080Tiで1時間前後掛かります)。サンプル用の笑顔の画像を読み込み実行してみます。
$ python3 predict.py
('happy', 0.9798463)
('neutral', 0.017535161)
('angry', 0.00083844905)
('surprise', 0.0007414131)
('fear', 0.0005858841)
スクリプトを実行すると'happy', 0.9798463(喜び97.9%)という結果が出ます。データセット画像が64x64ピクセルの白黒画像であったことに注意してください。KerasのImageDataGeneratorメソッドにあるload_img()を使い画像サイズと白黒画像指定をしています。3
推論と同じ3次元にするため、1次元チャンネルを追加し、白黒画像のパラメータ数255で割り正則化します。
モデルのコンバートは以下の様に行います。
predict.py より抜粋
from keras.preprocessing import image
save_path = '../nodejs/static/emotion_XCEPTION'
tfjs.converters.save_keras_model(emotions_XCEPTION, save_path)
print("[INFO] saved tf.js emotion model to disk..")
これで指定したパスにコンバートされた学習済みモデルが格納されます。
5. tracking.jsで顔を抽出する
Pythonを使用した機械学習で顔を抽出する際はOpenCVを使うことが多いかと思います。しかしブラウザ(クライアントサイド)で取得した画像データをOpenCVを使って処理しようとすると少し面倒です。
- 「クライアントサイドの画像データ取得」>「サーバサイドで画像データを受け取り」>「サーバサイドで画像処理」>「クライアントサイドにデータを送信」
この様な処理になります。そこでクライアントサイドで顔認証できる以下のJavaScriptライブラリtracking.jsを使用します。
クライアントサイドのJavaScriptだけで、画像から顔の座標を取得することができます。
顔認識のサンプルコードはtracking.js/examples/face_alignment_video.html - GitHubにあります。今回はのサンプルアプリケーションはこのサンプルをもとに作成していきます。
video要素をcanvas要素へ変換し顔部分の座標(四角で囲まれた部分とランドマーク)を返します。座標をもとに線と点をvideo要素上にcanvasで描写します。
今回のサンプルアプリケーションでは、感情認識のために顔部分を別のcanvas要素として切り出します。
顔部分の切り出しができれば前回と同様その画像をもとにTensorFlow.jsを使い推論を行うことができます。
6. 画像データを推論可能な形式に変更する
サンプルアプリケーションの処理は以下のとおりです。
- Webカメラを使い画像をストリーミングしブラウザに表示する。
- ブラウザに表示された
video要素からtracking.jsのメソッドを使い顔部分のcanvas要素を切り出す。 canvasデータをTensorFlow.jsのメソッドを使い推論可能なテンソルへ変換し、に画像の大きさ変更や次元の追加、テンソルの演算を行う。- 推論可能なテンソルを元に学習済みデータを使い推論を行う。
順を追いながら解説していきます。
6-1. Webカメラのストリーミング
predict.js より抜粋
var video = $('#main-stream-video').get(0);
var tracker = new tracking.LandmarksTracker();
function startWebcam() {
tracker.setInitialScale(4);
tracker.setStepSize(2);
tracker.setEdgesDensity(0.1);
tracking.track(video, tracker, { camera: true });
};
Webカメラの操作はtracking.jsのドキュメントに沿って記述します。ここでは顔のランドマークの座標を取得する指定をしてカメラを起動させています。4
6-2. video要素からcanvas要素を切り出す
predict.js より抜粋
let originalVideoWidth=640;
function captureWebcam(rect) {
var faceCanvas = $('#faceCanvas').get(0);
var faceContext = faceCanvas.getContext('2d');
//adjust original video size
var adjust = originalVideoWidth / video.width
faceContext.drawImage(video, rect.x * adjust , rect.y * adjust, rect.width * adjust, rect.height * adjust,0, 0, 100, 100);
tensor_image = preprocessImage(faceCanvas);
return tensor_image;
}
顔画像用のcanvasに、video要素から顔部分の切り出し位置を指定して切り出します。

tracking.jsに画像を読み込むと顔の座標を取得することができます。rect.x(x軸の開始位置)、rect.y(y軸の開始位置)、rect.width(画像の幅)、rect.height(画像の高さ)これらを利用して顔画像を切り取ります。5

1つ注意が必要なのが、座標はHTMLの表示領域を元に取得されますが、video要素はカメラの画素数そのままで取得されます。
このアプリケーションの場合だと、video要素の表示領域はwidth="320" height="240"と指定していますが、実際のWebカメラから取得される領域はwidth="640" height="480"となりますので、canvasに切り出す際カメラから取得した画像を1/2にしなければなりません。
Webカメラの画素数がwidth="640" height="480"になるのはMediaDevices.getUserMedia()メソッドの仕様です。6ここではブラウザの表示領域が小さいためCSSでzoom: 1.5;の指定をしています。
6-3. canvasデータを推論可能なテンソルへ変換する
predict.js より抜粋
function preprocessImage(image){
const channels = 1;
let tensor = tf.fromPixels(image, channels).resizeNearestNeighbor([64,64]).toFloat();
let offset = tf.scalar(255);
return tensor.div(offset).expandDims();
};
ここからの処理は前回と同様です。
まずtf.fromPixels().toFloat()メソッドでcanvasの画像をNumpy形式のテンソルに変換しています。デフォルトはカラー3チャンネルですが、今回は白黒画像のためチャンネル1と指定しています。ここではresizeNearestNeighbor()メソッドで画像サイズ64x64の指定をしています。
続いてtf.scalar()メソッドとtf.div()メソッドを使い画像の階調値255を0~1の値へと正則化します。
最後に.expandDims()メソッドで読み込み画像のチャンネル1を追加し3次元テンソルに変換します。7
predict.py より抜粋
img = image.load_img(image_path, grayscale=True , target_size=(64, 64)) img_array = image.img_to_array(img) pImg = np.expand_dims(img_array, axis=0) / 255
Python/Kerasの推論を見てみましょう。同様の処理をしているのがわかるかと思います。
6-4. 学習済みデータを使い推論を行う
predict.js より抜粋
let model;
async function loadModel(){
console.log("model loading..");
$("#console").html(`<li>model loading...</li>`);
model = await tf.loadModel(`http://localhost:8080/emotion_XCEPTION/model.json`);
console.log("model loaded.");
$("#console").html(`<li>XCEPTION model loaded.</li>`);
};
モデルの読み込みはホストされた状態でなければなりません。tf.loadModel()メソッドを使い読み込みます。
predict.js より抜粋
const CLASSES = ({0:'😠 angry',1:'😬 disgust',2:'😨 fear',3:'😄 happy', 4:'😢 sad',5:'😮 surprise',6:'😐 neutral'})
async function predict(rect){
let tensor = captureWebcam(rect) ;
let prediction = await model.predict(tensor).data();
let results = Array.from(prediction)
.map(function(p,i){
return {
probability: p,
className: CLASSES[i],
classNumber: i
};
}).sort(function(a,b){
return b.probability-a.probability;
}).slice(0,6);
$("#console").empty();
results.forEach(function(p){
$("#console").append(`<li>${p.className} : ${p.probability.toFixed(6)}</li>`);
return emotion = [results[0].classNumber,results[0].className, results[0].probability]
});
};
推論はmodel.predict()メソッドを使って行います。戻り値の推論値とクラス名を紐付けるのにArray.from()メソッドとmap()関数を使います。8
戻り値の高い順にソートするためsort()メソッド9とslice()メソッド10を利用します。
今回は感情を推論した結果をreturnを使って返すようにしています。

[フリー素材アイドルMika+Rika]
predict.py より抜粋
classes = ({0:'angry',1:'disgust',2:'fear',3:'happy',
4:'sad',5:'surprise',6:'neutral'})
prediction = emotions_XCEPTION.predict(pImg)[0]
top_indices = prediction.argsort()[-5:][::-1]
result = [(classes[i] , prediction[i]) for i in top_indices]
for x in result:
print(x)
Pythonの記述ではこの様になります。
8.リアルタイムで推論結果を表示する
predict.js より抜粋
const COLORS = ({0:'red',1:'green',2:'purple',3:'yellow', 4:'blue',5:'skyblue',6:'white'})
async function alignment(){
tracker.on('track', function(event) {
var canvas = $('#main-stream-canvas').get(0);
var context = canvas.getContext('2d');
context.clearRect(0,0,canvas.width, canvas.height);
if(!event.data) return;
event.data.faces.forEach(function(rect) {
predict(rect);
console.log(emotion[0],emotion[1],emotion[2]);
emotionColor = COLORS[emotion[0]]
context.strokeStyle = emotionColor;
context.lineWidth = 2;
context.strokeRect(rect.x, rect.y, rect.width, rect.height);
context.font = '11px Helvetica';
context.fillStyle = emotionColor;
context.fillText(emotion[1], rect.x + rect.width + 5, rect.y + 11);
context.fillText(emotion[2].toFixed(6), rect.x + rect.width + 5, rect.y + 22);
});
}); };
tracking.jsではtracker.on()メソッドを使うことで自動的にWebカメラ画像から顔の座標を抽出してくれます。11
座標を示す変数rectを上述の通りTensorFlow.jsで推論させることで推論結果が返されます。今回のアプリケーションでは推論結果を元に顔部分の色を変えるように指定しています。

happy [フリー素材アイドルMika+Rika]
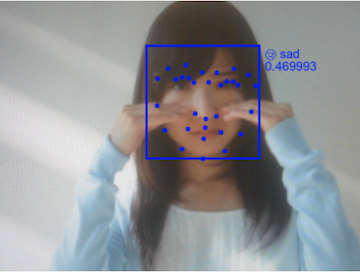
sad [フリー素材アイドルMika+Rika]
ループの終了は画面のリロードにより行います。
9. まとめ
冒頭の画像は子供用のPC(Celeron N3350)で動作させている様子です。JavaScriptだけで実行できるので低出力PCのローカル環境でも動作させることができます。
またHerokuなどのPaaSに簡単にデプロイすることができます。(Herokuにデプロイしたサンプルアプリケーションはこちらです)
PCのデスクトップアプリやスマートフォンアプリなども工夫次第で面白いものができそうですね。
Let's Play機械学習! 是非試してみてください。


