2017.12.26
作りながら学ぶ強化学習 -初歩からPyTorchによる深層強化学習まで
第2回 強化学習が注目されている理由と応用事例
SEやプログラマ、エンジニア、一般の方を対象に、少しずつ実際にプログラムを作りながら、強化学習および深層強化学習について解説していきます。
本連載をまとめ、さらに多くの記事を追加した書籍『つくりながら学ぶ!深層強化学習』を2018年7月に発売しました!

(上の書籍画像をクリックすると購入サイトに移動できます)
はじめに
前回は、教師あり学習、教師なし学習、強化学習の概要について紹介しました。
今回は、近年強化学習が注目されている理由と、強化学習・深層強化学習が現在どう活用されていて、この先どのように社会で応用されていくのか私見を紹介します。
強化学習が注目されている2つの理由
強化学習が注目されている背景には、2つの理由があると考えています。1つ目は、強化学習が脳の学習メカニズムと類似しているため、2つ目はディープラーニング(深層学習)との相性が良く、強化学習とディープラーニングを組み合わせた深層強化学習により、これまで困難であった課題を解決する発表が連続したためです。
1. 強化学習と脳の学習メカニズム
1つ目の理由、強化学習が脳の学習メカニズムと類似しているという点を解説します。強化学習という名前は、Skinner博士の提唱した脳の学習メカニズムであるオペラント学習(オペラント条件づけ)[1]に由来します。オペラント学習の一種である強化と学習方法が似ているため、強化学習という名前で呼ばれるようになりました。
Skinner博士のオペラント学習は、「スキナー箱」と呼ばれるラット(ねずみ)の実験で提唱された理論です。スキナー箱実験の最も単純な例を紹介します(図2.1)。ラットが箱(飼育ゲージ)の中のボタンを押すと餌(報酬)が出てくる構造にしておきます。ラットははじめ、偶然ボタンに触れます。すると餌が出てくるのですが、ボタンと餌の関係は理解できていません。ですが、ボタンに偶然触れ餌が出てくる経験を繰り返すうちに、ラットはボタンを押す動作と餌(報酬)の関係を学習し、そのうちボタンを押す動作を繰り返すようになります(行動の強化)。つまり、特定の動作(ボタンを押す)に対して、報酬(餌)を与えると、その動作が強化される(繰り返される)という実験結果が得られ、この動作学習メカニズムはオペラント学習(強化)と提唱されました。
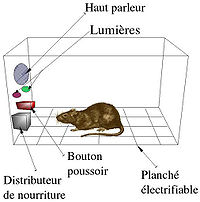
図2.1 スキナー箱[2]
その後1990年代後半に脳科学の実験で、オペラント学習による強化がニューロン(神経)レベルでも実証されるようになりました。Skinner博士の強化は行動実験によるものでしたが、Schultz博士らは実際にサルの脳に電極を刺してニューロンの活動(電位の変化)を記録しながら、行動実験を行いました[3]。その結果、黒質と腹側被蓋野(ふくそくひがいや;脳幹)に存在するドーパミンを放出するニューロンの活動タイミングが、課題の学習前後で変化することが明らかになりました。さらにその変化の仕方が強化学習のアルゴリズムとよく一致していることが示されました。この実験により、強化学習のアルゴリズムはニューロンレベルで脳の学習メカニズムと類似していることが示されました。
AI(人工知能)を実現するために知的システムの代表である脳を参考にするのは必然の流れであり、「強化学習は、脳が複雑な課題を学習するのと同じようなメカニズムです」と説明されれば、期待が高まります。実際、1990年代後半から2000年代初頭には強化学習のブームが起こりました。しかし残念なことにこのタイミングでは想像した成果は出ず、2000年代後半に入ると、強化学習で知的システムを作る試みはいったん下火となります(図2.2)。
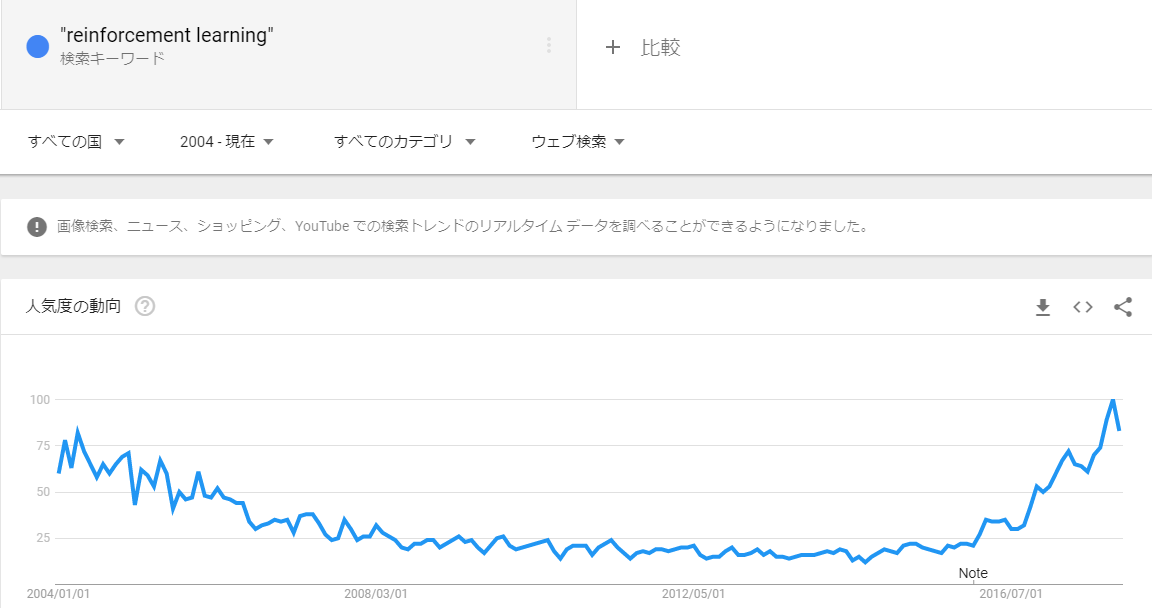
2000年代前半に強化学習が一度下火になった理由は、状態を縮約表現する良い方法が存在しなかったからです。これは難しい表現となっているので、丁寧に説明します。
状態とは、例えば 歩行ロボットであれば「各脚の関節の角度や速度」の情報を意味し、囲碁や将棋であれば「盤面のどの位置にどのコマがあるのか(加えて、将棋の場合は持ち駒は何か)」という情報です。つまり時刻tにおける制御対象を再現するために必要な情報を状態と呼び、s(t) と書きます。
続いて縮約表現について説明します。強化学習ではシステムに状態s(t)を入力して、次に行うべき行動a(t)を出力させます。このとき、全状態パターンを列挙し、各パターンごとに全行動を学習させる方法を表形式表現(tabular representation)と呼びます。(状態パターン数)×(行動の種類数)の表を作成するからです。表形式表現は対象課題が単純で、状態数と行動の種類が少なければ表現可能です。しかし、ロボットの歩行や、囲碁、将棋の場合には、状態のパターンと行動の種類が莫大な組み合わせ数となり、表で表すことは不可能となります。そこで、状態s(t)を、縮約(≒圧縮)して表現してあげる必要があります。例えば将棋であれば、盤面全ての情報ではなく「王と飛車と金の位置関係のみ」に注目するなどです(この例は概念的な話で、実際の将棋AIとは異なります)。
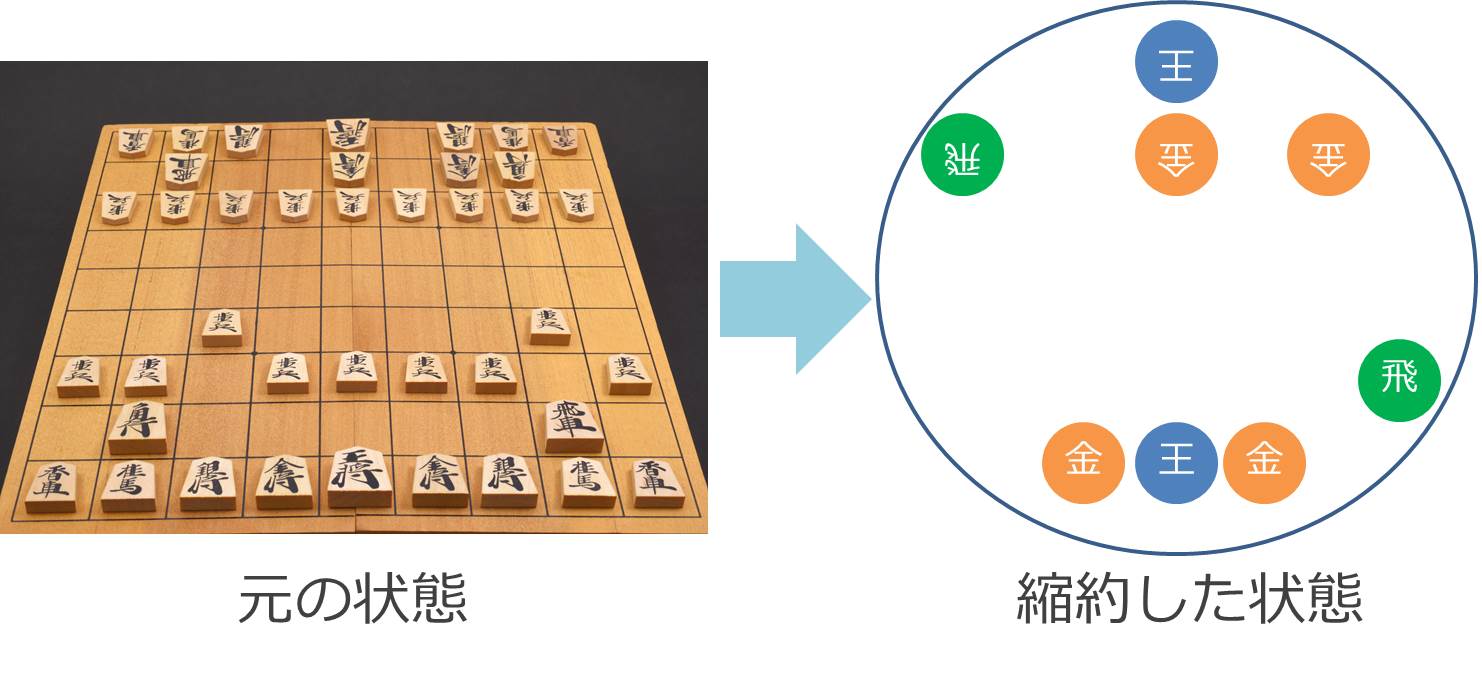
ただし、盤面の情報をどう縮約するのか、そのルールを自動で生み出すことは非常に困難でした。なぜなら状態s(t)に対して、次にとるべき行動 a(t)を決めるのに重要な情報を損なわずに、状態を縮約する必要があるからです。そのため、状態を縮約表現する良い方法の実現が、強化学習で困難な課題を解決するための課題となっていました。
2. 強化学習とディープラーニングの出会い
そんな状況を打開したのが、強化学習が注目を集めている2つ目の理由、ディープラーニングの出現です。ディープラーニングは、Hinton博士らが2006年の論文で発表した機械学習手法の一種です[6]。その後、Hinton博士らはディープラーニングを実装した画像識別システムを構築し、2012年の画像認識コンテスト「ILSVRC(ImageNet Large Scale Visual Recognition Challenge)」でこれまでの識別精度を大幅に更新する結果を出しました。これを機会に、ディープラーニングに注目が集まるようになりました。
ディープラーニングとは、これまで3層(入力層・中間層・出力層)で表現されていたニューラルネットワークの中間層を増やした(深くした)ものです。ディープラーニングには、複雑な入力情報(例えば画像データ)をうまく縮約して表現できるという特徴があります。ニューラルネットワークや、ディープラーニングについての詳細な説明は、本連載の後半で行います。ディープラーニングの出現により、強化学習の状態s(t)の縮約にディープラーニングを使う試みが行われるようになりました。
強化学習にディープラーニングを組み合わせた手法は、深層強化学習(Deep Reinforcement Learning)と呼ばれています。これはブロック崩しゲーム[7]を深層強化学習の一種であるDQN(Deep Q-network)で攻略する動画で、一躍有名となりました[8]。次の動画を御覧ください(図2.4)。この動画では、ボールを下に落とすとマイナスの報酬(罰)、ブロックを崩すとプラスの報酬を与えて強化学習させています。学習が進むと、端のブロックを崩してボールをブロックの裏側へと通し、一気にブロックを崩すという、まるで凄腕の人間プレイヤーの動作を学習しています。強化学習とディープラーニングを組み合わせるとこんな複雑なことが実現できるのかと世間にインパクトを与え、深層強化学習に注目が集まるきっかけとなりました。
図2.4 深層学習によるブロック崩しの攻略[9]
※画像をクリックするとYouTube動画が再生されます。
ブロック崩しにつづいて、深層強化学習が注目された理由がアルファ碁(AlphaGO)の出現です[10]。アルファ碁はGoogleが買収したDeepMind社で開発されました。2015年10月、碁のヨーロッパ王者であるファン・フイ2段に勝ち越し、2016年3月には、世界王者経験のあるイ・セドル9段に勝ち越しました。そして2017年5月には、当時の世界王者といえるカ・ケツ9段にも勝ち越し、事実上人類を超える囲碁プログラムとなりました。アルファ碁は、プロ棋士を含む多くの棋譜データを学習した「教師あり学習システム」と、教師あり学習システム同士を対戦させて深層強化学習により進化させた「深層強化学習システム」の両方を用いて、次に打つ手を決めていました。その後、2017年10月にはアルファ碁をさらに進化させたアルファ碁ゼロ(AlphaGo Zero)が発表されました[11]。アルファ碁ゼロは人間の棋譜データを用いた教師あり学習をいっさい使わず、深層強化学習のみで囲碁の攻略法を学習しています。アルファ碁と対戦すると、全勝するレベルになったと報告されています。さらに囲碁だけでなく、将棋やチェスにもアルファ碁ゼロのアルゴリズムを応用したAlphaZeroというシステムも発表されました[12]。このアルファ碁シリーズの功績は、攻略対象の状態s(t) と行動a(t) がPC上で完全に再現できる条件下では人間の知能はもうプログラムには敵わないのでは、と思えるレベルとなっています。
このように、強化学習が脳の学習メカニズムに似ている点で注目が集まり、さらに近年ディープラーニングと組み合わせることで非常に難しい課題が攻略できるようになったため、強化学習・深層強化学習に注目が集まっています。
強化学習・深層強化学習の応用事例
強化学習の研究・応用状況
強化学習の研究や応用は、不完全情報ゲームの攻略や現実空間での知的システムの構築に焦点を移しつつあります。
不完全情報ゲームと完全情報ゲームについて解説します。将棋や囲碁は完全情報ゲームと呼ばれ、プレイヤーはゲーム状態のすべての情報をお互いに知っています。一方で、大富豪や、ポーカー、麻雀といったゲームは、不完全情報ゲームと呼ばれます。これはプレイヤーによって知っている情報が異なったり、山札の中に誰も分からない情報が存在するからです。ですが、このような不完全情報ゲームが攻略されるのも時間の問題となりつつあるように感じます。例えばポーカーではAIがプロプレイヤーに勝ったことが報告されています[13]。
現実空間での知的システムの構築では、例えば自動運転技術や高精度な工作機械などが実現しつつあります。この分野では日本のPreferred Networks社などが、図2.5に示す自動運転の研究動画を公開するなど[14]、深層強化学習を利用した取り組みを実施しています。また、アルファ碁を開発したGoogle DeepMindのCEOであるDemis Hassabis博士は、Googleのサーバを集めたデータセンタの冷却効率を、強化学習を用いて改善し消費電力削減に成功したと発表しています[15]。さらに今後、バーチャル個人アシスタントの開発やイギリスで電力のスマートグリッドシステムに、強化学習を導入して取り組むことが発表されています[16]。

図2.5 分散深層強化学習による自動運転ロボット制御の様子[14]
※画像をクリックするとYouTube動画が再生されます。
深層強化学習が社会に与える影響
強化学習、深層強化学習は、PC上でのゲーム攻略から実空間社会での応用へと、その適用範囲を移しつつあります。筆者は「深層強化学習は日本企業が世界を変える原動力になるのでは」と考え、社内で開発・研究に取り組んでいます。
DeepMindの発表した強化学習によるデータセンタの冷却効率向上手法は、その詳細が明らかにされていません。データセンタ内外に多数のセンサを設置し、おそらく空間的最適化と時間的最適化を実現する空調(冷却装置)の制御手法を、深層強化学習で実現したと推察されます。空間的最適化とは、広大なデータセンタの一部のサーバの温度が上昇した際に、どの空調とどの空調をどんな風向きで動かせば、一番効率的にそのサーバ周囲だけを冷却できるのかを制御する手法です。時間的最適化とは、ネットワークの状況やデータセンタ周囲に配置した気温・湿度センサの情報から、一定時間後のサーバの稼働率とデータセンタの周囲の気温を予測し、時間的に無駄な冷却を避ける制御手法です。つまり、「このあとサーバの稼働率は下がり、外気の気温も下がってデータセンタ全体の室温も下がるから、このサーバの温度も自然と下がるし、今は急いで冷却しなくていいや」と判断できれば、電力消費の削減につながります。この制御則を人間が構築するのは大変ですが、電力消費量が少なく冷却できたときにはプラスの報酬を、電力消費量が多かったり、きちんと冷却できなかったときにはマイナスの報酬を与えることで、深層強化学習により制御則を構築させたと思われます。
今後、現実空間の情報をセンサで取得し、現実空間にあるシステムを効率的に制御する手法は、新たなフェイズを迎えると考えられます。新しい通信規格である5G通信が導入されれば、多数同時接続、超低遅延な通信が実現し、IoT(Internet of Things)の流れは一気に加速するでしょう。すると、現実空間に大量のセンサを配置し、莫大な情報を取得できるようになります。現実空間からたくさんの情報が取得できれば、より細やかで効率的な制御も可能になります。例えば、街中の位置センサから人と車の流れを観測し、道路の信号を効率的に動作させられれば渋滞が緩和できます。身体につけたセンサで生体情報や視覚情報、会話情報を測定すれば、仕事の効率を最大限にするように休憩や仕事内容のアドバイスをしてくれることもできるかもしれません。様々な応用可能性があります。
ただし、センサの数が膨大になり入力情報が莫大で超高次元になれば、これまでのように「このセンサの値がこれ以上の値の場合はこう動かす」といったルールベースでの制御ができなくなります。そこで超高次元の入力情報を、制御に必要な情報だけに縮約し、報酬信号から自己学習で制御手法を獲得できる深層強化学習の出番となります。現実空間のシステムや機器の制御は日本企業にとって得意な分野です。そのため私は、深層強化学習×実空間のシステム制御という分野は、日本企業が今後新たに活躍できる分野だと考えており、強化学習・深層強化学習は社会に大きな影響を与えると考えています。
以上、今回は強化学習が注目される2つの理由と応用事例・今後の展開について私見を紹介しました。次回からは実際にプログラムを実装し、作りながら強化学習を学びます。
引用
-
[1] Skinner, Burrhus Frederic. The behavior of organisms: An experimental analysis. BF Skinner Foundation, 1990.
-
[3] Schultz, Wolfram. "Predictive reward signal of dopamine neurons." Journal of neurophysiology 80.1 (1998): 1-27.
-
[4] https://trends.google.com/trends/explore?date=all&q=%22reinforcement%20learning%22
-
[5] Katsuhiro/shutterstock
-
[6] Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." science 313.5786 (2006): 504-507.
-
[7] AtariのBreakout https://gym.openai.com/envs/Breakout-v0/
-
[8] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.
-
[10] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
-
[11] Silver, David, et al. "Mastering the game of go without human knowledge." Nature 550.7676 (2017): 354-359.
-
[13] Brown, Noam, and Tuomas Sandholm. "Superhuman AI for heads-up no-limit poker: Libratus beats top professionals." Science online 17 Dec (2017).
-
[14] https://research.preferred.jp/2015/06/distributed-deep-reinforcement-learning/
-
[15] https://www.technologyreview.jp/s/3679/the-ai-that-cut-googles-energy-bill-could-soon-help-you/
-
[16] https://www.ft.com/content/27c8aea0-06a9-11e7-97d1-5e720a26771b



{kind=link}