2017.07.28
第3回 人狼知能と対話システム
第1回で、人狼知能にはプロトコル部門と自然言語部門があることを紹介しました。第2回では、人狼知能エージェントを対戦させる方法について説明しました。エージェントの作り方(仕様)自体は、プロトコル部門と自然言語部門で共通です。第3回と第4回は、自然言語部門に焦点をあてて、そもそも人狼知能エージェントを作るというのはどういうことなのかを紹介していきましょう。

電子書籍『人狼知能で学ぶAIプログラミング 欺瞞・推理・会話で不完全情報ゲームを戦う人工知能の作り方』をマナティで発売中!
(上の書籍画像をクリックすると購入サイトに移動できます)
1. 人狼知能と対話システム
人狼ゲームは、本来、人間同士が対話(会話)を通じて行うゲームです。そのゲームをコンピュータに行わせるということは、自動的に会話ができる「対話システム」を作るということになります。身近なところでは、Microsoftの「りんな」「Cortana」、NTTドコモの「しゃべってコンシェル」、Appleの「Siri」、Google社の「Google アシスタント」など、各社からさまざまな対話システムが提供されています。
対話システムは、大きく分けると2種類あります。特定のタスクの達成を目的にするものを「タスク指向型対話システム」と呼び、雑談的に対話を続けるものを「非タスク指向型対話システム」と呼びます。人狼知能エージェントに必要となる対話システムは、この両方の要素が必要です。
対話システムとは、誤解を恐れず端的にいえば「人間とおしゃべりするシステム」です。このように表現すると、ユーザーである人間と言語情報を通じた会話をするのみのように聞こえてしまいますが、表情やジェスチャーなどの非言語情報も重要です。さらに、対話する相手が、どのような見た目であるか、どのような人物設定であるかということも大きな影響を及ぼします。このように非言語情報は重要ですが、ここでは言語情報を通じた対話システムに焦点をあてて説明します。
2. ルールベースの対話システム
初期の対話システムから現在に至るまで、ルールベースの仕組みはよく使われています。ここでは初期の対話システムとして有名なELIZAを紹介しましょう。ELIZA※1は、1960年代に開発された対話システムで、達成すべき特定の目的がないので非タスク指向型対話システムに分類されます。ELIZAでは、キーワードのリストと対応する言語表現パターン、返答用テンプレートを定義しておきます。そして、ユーザーの入力にそれらのキーワードがないかを探し、もしあればパターンマッチを実行して、入力から単語やフレーズを抽出します。最後に抽出した単語やフレーズを定義済みのテンプレートにはめ込んで返事をします。たとえば、次のような具合です。
こうした記述を「スクリプト」と呼んでいますが、ELIZAの有名なスクリプトとして、精神分析医をシミュレートしたといわれる「DOCTOR」があります。DOCTORは、英語のテキスト入力に対して英語で回答します。UNIX系のOSには標準で入っていることの多いEmacsで、「M-x doctor」(「M-x」は[Meta]キー([Esc]キー)を押した後に[x]キーを押す)というコマンドを打てば起動するので、環境をお持ちの方は試してみてください。図1は筆者が試してみたDOCTORスクリプトとの対話の例です。カッコ内は筆者による拙訳です。仕組みをわかった上で観察すると、なぜこのような応答が返ってくるのかが理解できます。

ELIZAでは、人間が記述したスクリプトの範囲でしか応答ができません。それでは会話がつながらなくなってしまうので、スクリプトのパターンで答えるのが難しい場合には、ある種のオウム返し的な答えをしたり(A)、なにがしか話題を転換したりするように(B)工夫されています。また、答えられる範囲内であれば、ユーザーに疑問を投げかけることで会話を続けさせるようにしています。
ELIZAは、「人工無脳」(あるいはチャットボット、ボット)などと呼ばれる対話システムの元祖といえます。ELIZAが登場した際、ユーザーによっては、これがパターンマッチで動作しているとは信じなかったといいます。現代でも、掲示板やTwitterなどで相手が機械だと気づかず会話をしている場面を見かけることがあります。
3. 機械学習による雑談対話システム
日本マイクロソフトが開発した「女子高生AIりんな」は、現在、最もユーザーの多い雑談対話システム(非タスク指向型対話システム)の1つといえるでしょう。ここでの説明は主に2016年時点の論文※2に基づいています。りんなには「恋愛相談」など、いくつかのモードがあるようで、その際はタスク指向型対話システムのように振る舞いますが、中核は「チャットワーカー」と呼んでいる雑談対話システムです。この対話システムでは、学習用に大量の発話ペアデータを準備した上で、「教師付き機械学習」によってユーザーの入力に最も類似した発話ペアを決定し、これを回答として用いています。
教師付き機械学習とは、入力に対して期待する出力を付与した訓練データを用意し、この訓練データを使って学習することで、出力の不明な未知の入力データに対しても出力を推測できるようにする手法です。詳細は書籍の「第4章 機械学習入門」で説明しているので、そちらを参照してください。ここでの類似度は主に出現した単語によって計算しています。
こうした発話ペアデータと教師付き機械学習を用いた手法は、統計的な対話システムの多くに共通しています(図2)。機械学習手法の一種である強化学習を利用する場合、やはり対話データをある種の正解として訓練に用いますが、状態遷移を訓練することになるため「会話の流れ」を学習できることが期待されます。
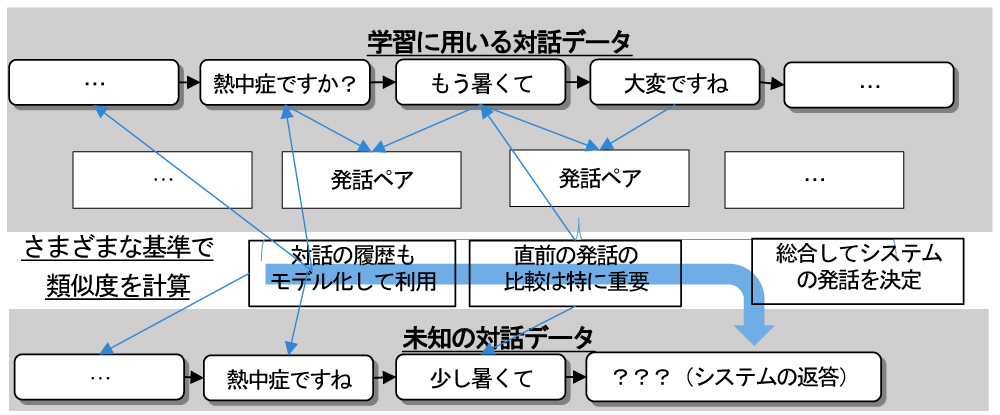
いずれにせよ、ユーザーとの対話を通じて学習データを蓄積し、学習により「賢く」なっていくことを期待する仕組みといえます。
4.対話システムの構成
対話システムの構成を、もう少し一般化して説明しましょう。図3の左側は、対話システムの典型的な構成例です。ここでは音声対話を想定したものになっていますが、テキスト入出力の対話システムであれば、この図から音声認識と音声合成を除いたものになります。実際にはもっと細かい機能ブロックから構成されることもありますが、このように独立した機能ブロックを組み合わせる形で構成されることが一般的です。
また、機能ブロックを組み合わせる構成は、対話システムに限らず、自然言語処理を用いたシステムではよくみられる設計です。機能ブロックの要素1つひとつが複雑で、要素の作成自体が研究分野をなしているレベルのため、すべてを1から作成するのは現実には難しく、既存のツールやリソースを利用することが多いからです。
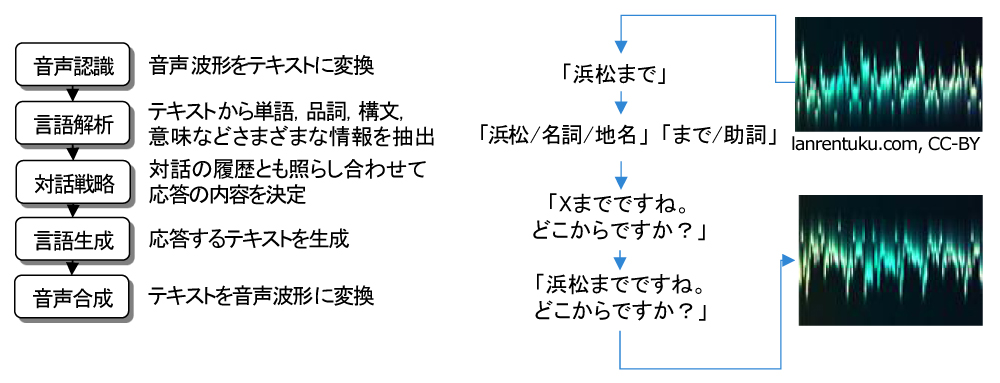
典型的な対話システムの流れを、乗車券の予約をするシステムの例として説明します。図3の右側に挙げたように、ユーザーが「浜松まで」と発話したとします。「音声認識」では、この音声波形をテキストに変換します。続く「言語解析」では変換されたテキストを解析し、さまざまな情報を抽出します。たとえば「浜松 / 名詞 / 地名」「まで / 助詞」というように、形態素解析、品詞解析、固有表現解析、あるいは係り受け解析や主語述語の解析といったことを行います。
さらに「対話戦略」では、そうした言語解析の結果を用いて、応答する内容を決定します。乗車券の予約であれば、対話を通じて少なくとも出発地と目的地を確認する必要があります。「浜松まで」という入力から、目的地が「浜松」であると判断できれば、あとは出発地を確認する必要があるといった具合です。
このとき、すでにそれまでの対話で出発地が確認済みであれば、予約終了の手続きに移ることになるかもしれません。つまり、次に何を行うべきかは、対話の流れの中での「状態」を定義し、ユーザー入力とシステム出力に応じて状態遷移をすることで決定できます。対話戦略の部分は、対話システムとその目的によってさまざまに異なります。
「対話戦略」で応答したい内容が決まったら、これをもとに応答テキストを生成します。生成といっても、1から自然な文章を作り上げるのはまだ難しいため、多くの場合ではテンプレートとなるテキストが用意されており、そこに単語を当てはめることでテキストを生成します。たとえば「Xまでですね。どこからですか?」というテンプレートを用意しておいて、Xに「浜松」を当てはめるという形です。
最後に、こうして生成された「浜松までですね。どこからですか?」というテキストを音声合成システムで音声波形に変換して、発話します。
ここでは単純な例で説明しましたが、ユーザーはどんな自然言語の入力(対話)もできてしまうので、予期しない入力が来ることが大いに考えられます。先の乗車券予約の例はタスク指向型対話システムであり、目的が限定される分、予期できなかった入力は目的に関係がなければ対応できなくても、ある程度は許されるでしょう。しかし乗車券の予約だけだとしても、対話の状態とテンプレートの準備に大変な労力が必要です。さらにテーマを問わない雑談となると、あらゆる入力に対応しなければなりません。そうなると機械学習を用いて自動的な対話の学習を行うシステムが期待されますが、人間のように自然な対話ができるようなシステムはまだ存在しないといえるでしょう。
今のところ、人狼知能エージェントでは音声認識や音声合成は必要ありませんが、それ以外の自然言語を処理する部分は必要です。次回は、その背後にある自然言語処理について、詳しく説明します。
※本稿の一部は、許可を得て下記原稿の一部を基にしています。
狩野 芳伸「コンピューターに話が通じるか:対話システムの現在」(『情報管理』Vol. 59、p.658~665(http://doi.org/10.1241/johokanri.59.658)
参考文献
※1 Weizenbaum, J. 1966. ELIZA: A computer program for the study of natural language communication between man and machine. Communications of the ACM. vol.9, no.1, p.36-45.
※2 呉先超、伊藤和重、飯田勝也、坪井一菜、クライアン桃(2016)「りんな:女子高生人工知能」、言語処理学会第22回年次大会(NLP2016)、(http://www.anlp.jp/proceedings/annual_meeting/2016/pdf_dir/B1-3.pdf)
Manateeではメルマガ会員を募集中!