2016.09.29
第8回 「新米探偵、データ分析に挑む」の"Rと地図と連携する"をやってみた
「地図との連携方法」と「インターネット上に公開する」方法として、Shinyというパッケージを用いたアプリケーションで作成する手法についてご説明します。

はじめに
Rは年々便利になっており、データの取得から結果の公開まですべてRで完結することができます。
『新米探偵、データ分析に挑む』の第6章235ページにおいて、Rの操作に慣れてきた俵太くんが、 Rに地図と連携する機能がある、また、それをそのままスライドとしてインターネットに公開することができる、ということを見つけるシーンがあります。 作中には、その具体的な方法は書かれていませんでした。 今回は、「地図との連携方法」と「インターネット上に公開する」方法として、Shinyというパッケージを用いたアプリケーションで作成する手法について説明したいと思います。
「スライドとして公開する」方法としては、RMarkdownを使う方法が非常に便利です。 日本語の書籍やウェブページも多いので、是非検索してみてください。
以下は、このような流れで話を進めていきたいと思います。
1. データの取得
2. データの加工
3. 描画
4. アプリケーションの作成
1. データの取得
政府統計の総合窓口にある、国勢調査のデータを用います。 csv形式でダウンロードする方法もありますが、今回はAPIを使用してデータを取得する方法を用います。 政府統計の総合窓口(e-Stat) API機能から利用します。
「利用登録・ログイン」から利用登録をし、「ログイン」画面内にある「アプリケーションIDの取得」から、「appID」という英数字の文字列を取得します。
ここからRを使用します。
今回使用するパッケージとその大まかな用途は以下のとおりです。 すべてCRANにあるパッケージなので、ダウンロードしていない場合は以下のコマンドで取得できます。
# 今回使用するパッケージ
install.packages("estatapi") # 政府統計からデータを取得する用
install.packages("dplyr") # データ加工用
install.packages("tidyr") # データ加工用
install.packages("ggmap") # 住所・緯度経度対応用
install.packages("leaflet") # プロット用
# ダウンロードしたらパッケージの読み込み
library(estatapi)
library(dplyr)
library(tidyr)
library(ggmap) # 住所・緯度経度対応用
library(leaflet) # プロット用
※ estatapiパッケージの詳しい使い方は
* estatapi - 政府統計の総合窓口(e-Stat)のAPIを使うためのRパッケージ
* Rで解析:政府統計の総合窓口(e-Stat)データ取得に便利です!「estatapi」パッケージ
などを参考にしてください。今回は簡単に説明します。
パッケージを読み込んだら、先ほど取得したappIDをRにも置きます。
> パッケージの読み込み > library(estatapi) > # API使用のためのID > AppID <- "取得したID"
今回は平成22年の国勢調査のデータを使っていきます。 平成22年の国勢調査の調査結果になにがあるのかを調べます。
> # 「平成22年国勢調査」のデータに何があるのかを調べる
> ResultData <- estat_getStatsList(appId = AppID, searchWord = "平成22年国勢調査")
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 356 obs. of 11 variables:
$ @id : chr "0003033021" "0003033022" "0003033023" "0003033024" ...
$ @code : chr "01" "01" "01" "01" ...
$ $ : chr "人口" "人口" "人口" "人口" ...
$ STATISTICS_NAME : chr "平成22年国勢調査 速報集計 抽出速報集計" "平成22年国勢調査 速報集計 抽出速報集計" "平成22年国勢調査 速報集計 抽出速報集計" "平成22年国勢調査 速報集計 抽出速報集計" ...
$ @no : chr "00110" "00120" "00210" "00220" ...
$ CYCLE : chr "-" "-" "-" "-" ...
$ SURVEY_DATE : chr "201010" "201010" "201010" "201010" ...
$ OPEN_DATE : chr "2011-06-29" "2011-06-29" "2011-06-29" "2011-06-29" ...
$ SMALL_AREA : chr "0" "0" "0" "0" ...
$ OVERALL_TOTAL_NUMBER: chr "1980" "38700" "7776" "75810" ...
$ UPDATED_DATE : chr "2011-08-02" "2011-08-02" "2011-06-29" "2011-06-29" ...
> ResultData %>% as.data.frame() %>% head() # 頭6行を見る
@id @code $ STATISTICS_NAME @no CYCLE
1 0003033021 01 人口 平成22年国勢調査 速報集計 抽出速報集計 00110 -
2 0003033022 01 人口 平成22年国勢調査 速報集計 抽出速報集計 00120 -
3 0003033023 01 人口 平成22年国勢調査 速報集計 抽出速報集計 00210 -
4 0003033024 01 人口 平成22年国勢調査 速報集計 抽出速報集計 00220 -
5 0003033025 01 人口 平成22年国勢調査 速報集計 抽出速報集計 00310 -
6 0003033026 01 人口 平成22年国勢調査 速報集計 抽出速報集計 00320 -
SURVEY_DATE OPEN_DATE SMALL_AREA OVERALL_TOTAL_NUMBER UPDATED_DATE
1 201010 2011-06-29 0 1980 2011-08-02
2 201010 2011-06-29 0 38700 2011-08-02
3 201010 2011-06-29 0 7776 2011-06-29
4 201010 2011-06-29 0 75810 2011-06-29
5 201010 2011-06-29 0 15390 2011-06-29
6 201010 2011-06-29 0 7182 2011-06-29
estatapiパッケージのestat_getStatsList()で、平成22年の国勢調査の調査結果一覧が得られました。 「STATISTICS_NAME」がその調査結果名で、一番右の「@id」がそれに対応するIDです。 今回はIDが0003038591の調査結果を用いることにします。各都道府県の年齢層別の人口です。
> # 今回はIDが0003038591の調査結果を用いる > # メタ情報を取得 > MetaInfo <- estat_getMetaInfo(appId = AppID, statsDataId = "0003038591") > > # データの取得 > PrefData <- estat_getStatsData(appId = AppID, + statsDataId = "0003038591", + cdCat01 = "00710", + cdCat02 = "000", + cdCat04 = "000", + cdCat05 = "000", + lvArea = 2) > # 中身をチェック > PrefData %>% str() Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 1081 obs. of 19 variables: $ @tab : chr "020" "020" "020" "020" ... $ @cat01 : chr "00710" "00710" "00710" "00710" ... $ @cat02 : chr "000" "000" "000" "000" ... $ @cat03 : chr "000" "000" "000" "000" ... $ @cat04 : chr "000" "000" "000" "000" ... $ @cat05 : chr "000" "000" "000" "000" ... $ @area : chr "01000" "02000" "03000" "04000" ... $ @time : chr "2010000000" "2010000000" "2010000000" "2010000000" ... $ @unit : chr "人" "人" "人" "人" ... $ $ : chr "5506419" "1373339" "1330147" "2348165" ... $ value : num 5506419 1373339 1330147 2348165 1085997 ... $ tab_info : chr "人口" "人口" "人口" "人口" ... $ cat01_info: chr "全域" "全域" "全域" "全域" ... $ cat02_info: chr "総数(男女別)" "総数(男女別)" "総数(男女別)" "総数(男女別)" ... $ cat03_info: chr "総数(年齢)" "総数(年齢)" "総数(年齢)" "総数(年齢)" ... $ cat04_info: chr "総数(国籍)" "総数(国籍)" "総数(国籍)" "総数(国籍)" ... $ cat05_info: chr "総数(出生の月)" "総数(出生の月)" "総数(出生の月)" "総数(出生の月)" ... $ area_info : chr "北海道" "青森県" "岩手県" "宮城県" ... $ time_info : chr "2010年" "2010年" "2010年" "2010年" ... > > PrefData %>% as.data.frame() %>% head() @tab @cat01 @cat02 @cat03 @cat04 @cat05 @area @time @unit $ value 1 020 00710 000 000 000 000 01000 2010000000 人 5506419 5506419 2 020 00710 000 000 000 000 02000 2010000000 人 1373339 1373339 3 020 00710 000 000 000 000 03000 2010000000 人 1330147 1330147 4 020 00710 000 000 000 000 04000 2010000000 人 2348165 2348165 5 020 00710 000 000 000 000 05000 2010000000 人 1085997 1085997 6 020 00710 000 000 000 000 06000 2010000000 人 1168924 1168924 tab_info cat01_info cat02_info cat03_info cat04_info cat05_info 1 人口 全域 総数(男女別) 総数(年齢) 総数(国籍) 総数(出生の月) 2 人口 全域 総数(男女別) 総数(年齢) 総数(国籍) 総数(出生の月) 3 人口 全域 総数(男女別) 総数(年齢) 総数(国籍) 総数(出生の月) 4 人口 全域 総数(男女別) 総数(年齢) 総数(国籍) 総数(出生の月) 5 人口 全域 総数(男女別) 総数(年齢) 総数(国籍) 総数(出生の月) 6 人口 全域 総数(男女別) 総数(年齢) 総数(国籍) 総数(出生の月) area_info time_info 1 北海道 2010年 2 青森県 2010年 3 岩手県 2010年 4 宮城県 2010年 5 秋田県 2010年 6 山形県 2010年 > # 年齢層 > ages <- PrefData$cat03_info %>% unique() > ages [1] "総数(年齢)" "0~4歳" "5~9歳" "10~14歳" "15~19歳" [6] "20~24歳" "25~29歳" "30~34歳" "35~39歳" "40~44歳" [11] "45~49歳" "50~54歳" "55~59歳" "60~64歳" "65~69歳" [16] "70~74歳" "75~79歳" "80~84歳" "85~89歳" "90~94歳" [21] "95~99歳" "100歳以上" "不詳"
説明が駆け足になりましたが、ここまでがデータの取得です。 最初にも書きましたが、csvをダウンロードする方法もありますので、 この方法が面倒だと感じたらそちらの方法でも良いでしょう。
2. データの加工
上で取得したデータを、地図上でプロットするために加工していきます。 まずは、行に都道府県、列に年齢層が並ぶデータを作るために、dplyrパッケージ、tidyrパッケージを駆使します。
> library(dplyr) > library(tidyr) > # 整形 > Prefdf <- PrefData %>% + # 今回用いる列はPrefDataのうち、area_info(都道府県)、cat03_info(年齢層)、value(人口) + select(area_info, cat03_info, value) %>% + # 行に都道府県、列に年齢層がくるように加工 + tidyr::spread(key = cat03_info, value = value, fill=NA, convert=FALSE, drop=TRUE) %>% + # 「area_info」を「都道府県」に名称変更 + rename(都道府県 = area_info) %>% + # 列の並ぶ順番を調整 + select(都道府県, one_of(ages)) %>% + # 扱いやすいようにdata.frame型に変更 + as.data.frame() > > # このようなデータになります > Prefdf %>% str() 'data.frame': 47 obs. of 24 variables: $ 都道府県 : chr "愛知県" "愛媛県" "茨城県" "岡山県" ... $ 総数(年齢): num 7410719 1431493 2969770 1945276 1392818 ... $ 0~4歳 : num 346338 56508 122330 82489 80792 ... $ 5~9歳 : num 353251 61357 134010 88502 81422 ... $ 10~14歳 : num 365665 67314 143298 93862 84099 ... $ 15~19歳 : num 361670 65646 144480 94662 83477 ... $ 20~24歳 : num 403988 58624 145495 97478 76546 ... $ 25~29歳 : num 462251 70427 167064 104518 86184 ... $ 30~34歳 : num 518107 82870 189035 117606 94733 ... $ 35~39歳 : num 618763 97172 221348 140449 105201 ... $ 40~44歳 : num 539881 84402 195016 117230 91826 ... $ 45~49歳 : num 472604 85099 181718 109577 88611 ... $ 50~54歳 : num 413484 89511 186762 113512 91916 ... $ 55~59歳 : num 449460 104136 221170 127211 98513 ... $ 60~64歳 : num 551237 121104 239613 156250 80953 ... $ 65~69歳 : num 464480 94089 193226 128664 58874 ... $ 70~74歳 : num 374676 83951 156865 106181 61287 ... $ 75~79歳 : num 292728 79119 128216 100233 50514 ... $ 80~84歳 : num 197726 63446 99179 77672 35072 ... $ 85~89歳 : num 105492 37114 57055 45086 19940 ... $ 90~94歳 : num 43148 15562 23178 19806 10400 ... $ 95~99歳 : num 12261 4590 6532 6096 3548 ... $ 100歳以上 : num 1574 720 814 980 872 ... $ 不詳 : num 61935 8732 13366 17212 8038 ... > Prefdf %>% head() 都道府県 総数(年齢) 0~4歳 5~9歳 10~14歳 15~19歳 20~24歳 25~29歳 30~34歳 1 愛知県 7410719 346338 353251 365665 361670 403988 462251 518107 2 愛媛県 1431493 56508 61357 67314 65646 58624 70427 82870 3 茨城県 2969770 122330 134010 143298 144480 145495 167064 189035 4 岡山県 1945276 82489 88502 93862 94662 97478 104518 117606 5 沖縄県 1392818 80792 81422 84099 83477 76546 86184 94733 6 岩手県 1330147 49685 56532 62587 64637 54739 63878 74898 35~39歳 40~44歳 45~49歳 50~54歳 55~59歳 60~64歳 65~69歳 70~74歳 75~79歳 1 618763 539881 472604 413484 449460 551237 464480 374676 292728 2 97172 84402 85099 89511 104136 121104 94089 83951 79119 3 221348 195016 181718 186762 221170 239613 193226 156865 128216 4 140449 117230 109577 113512 127211 156250 128664 106181 100233 5 105201 91826 88611 91916 98513 80953 58874 61287 50514 6 83067 77956 82114 88648 101897 103946 84522 83864 80110 80~84歳 85~89歳 90~94歳 95~99歳 100歳以上 不詳 1 197726 105492 43148 12261 1574 61935 2 63446 37114 15562 4590 720 8732 3 99179 57055 23178 6532 814 13366 4 77672 45086 19806 6096 980 17212 5 35072 19940 10400 3548 872 8038 6 60973 33193 13636 3699 501 5065
無事、行に都道府県、列に年齢層が並ぶデータができました。
3. 描画
ようやく本番です。 地図上にデータをプロットするために、地点(この例では各都道府県)ごとに緯度と経度を取得する必要があります。 今回はggmapパッケージのgeocode()を使用します。 これは、Google Maps APIを使用して緯度と経度を取得するものです。 APIの利用には制限があるので(1日2500回まで)、使いすぎることのないようにしましょう。
> library(ggmap)
>
> # 各都道府県の緯度経度を手に入れる。API制限に注意
> PrefInfo <- geocode(Prefdf$都道府県, source = "google", output = "latlon")
>
> # lanが経度、latが緯度
> PrefInfo %>% head()
lon lat
1 136.9066 35.18019
2 132.7657 33.84162
3 140.4468 36.34181
4 133.9344 34.66175
5 127.6809 26.21240
6 141.1527 39.70362
>
> # 人口データと合体
> PrefMap <- Prefdf %>% cbind(PrefInfo)
> PrefMap %>% head()
都道府県 総数(年齢) 0~4歳 5~9歳 10~14歳 15~19歳 20~24歳 25~29歳 30~34歳
1 愛知県 7410719 346338 353251 365665 361670 403988 462251 518107
2 愛媛県 1431493 56508 61357 67314 65646 58624 70427 82870
3 茨城県 2969770 122330 134010 143298 144480 145495 167064 189035
4 岡山県 1945276 82489 88502 93862 94662 97478 104518 117606
5 沖縄県 1392818 80792 81422 84099 83477 76546 86184 94733
6 岩手県 1330147 49685 56532 62587 64637 54739 63878 74898
35~39歳 40~44歳 45~49歳 50~54歳 55~59歳 60~64歳 65~69歳 70~74歳 75~79歳
1 618763 539881 472604 413484 449460 551237 464480 374676 292728
2 97172 84402 85099 89511 104136 121104 94089 83951 79119
3 221348 195016 181718 186762 221170 239613 193226 156865 128216
4 140449 117230 109577 113512 127211 156250 128664 106181 100233
5 105201 91826 88611 91916 98513 80953 58874 61287 50514
6 83067 77956 82114 88648 101897 103946 84522 83864 80110
80~84歳 85~89歳 90~94歳 95~99歳 100歳以上 不詳 lon lat
1 197726 105492 43148 12261 1574 61935 136.9066 35.18019
2 63446 37114 15562 4590 720 8732 132.7657 33.84162
3 99179 57055 23178 6532 814 13366 140.4468 36.34181
4 77672 45086 19806 6096 980 17212 133.9344 34.66175
5 35072 19940 10400 3548 872 8038 127.6809 26.21240
6 60973 33193 13636 3699 501 5065 141.1527 39.70362
>
> # PrefMapの列名を変更しておく
> colnames(PrefMap) <- c("都道府県", "総数", ages[-1], "lon", "lat")
これで各都道府県の緯度・経度と人口の情報が得られたので、地図上で表現していきましょう。 今回使用するパッケージはleafletです。 leafletパッケージとは、オープンソースのJavaScriptのライブラリで、地図を描画し、インタラクティブに動かすことのできるものです。Rのleafletパッケージは、これを簡単に呼び出すことができます。
それでは、今回取得したデータについて、まずは各都道府県の人口の総数をプロットしてみましょう。 Rは以下のように書きます。
> # 人口の総数を描画 > leaflet(PrefMap) %>% + addTiles() %>% + # 中心、ズームサイズを調整 + setView(lng = 139, lat = 37, zoom = 5) %>% + # 人口の総数ごとにプロットサイズを変える + addCircles(lng = ~lon, lat = ~lat, weight = 1, + radius = ~sqrt(総数) * 30, + # プロットをクリックしたら都道府県名と人口の数が表示されるようにする + popup = ~paste(都道府県, 総数, sep=": "))
これを実行すると、RStudioを使用している場合「Viewer」の部分にこのような日本地図が表示されるはずです。
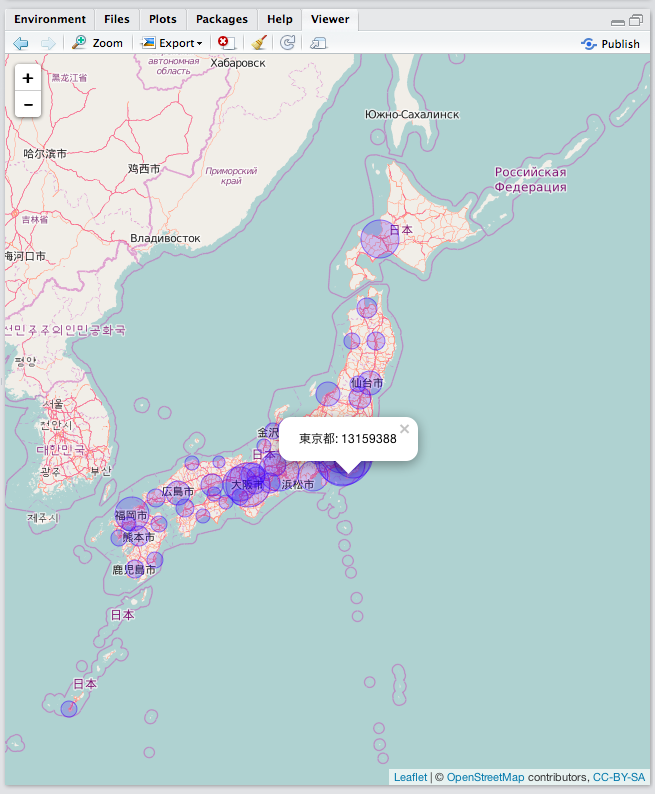
人口が多いところほど大きな円でプロットされます。また、円をクリックすると都道府県名と人口が表示されます。sqrtとpasteの中身をPrefMapのほかの列に変更するとそれに対応した列を同様にプロットできます。



